群馬大学 | 医学部 | サイトトップ | 医学情報処理演習
医学情報処理演習:2011年度第8回課題解答例
第8回に出てきた関数と文の主なものはこちらを参照されたい。
課題
carライブラリに含まれているUNというデータフレームは,国内総生産GDPと,乳児死亡率についての国連加盟国のデータである。含まれている2つの変数のうち,GDP(変数名gdp)を横軸,乳児死亡率(変数名infant.mortality)を縦軸にとって散布図と50%及び95%の集中楕円を描き,ピアソンの積率相関係数とスピアマンの順位相関係数を求め,相関が0と差が無いという帰無仮説の検定を有意水準5%で実行した。コードと結果と解釈を以下に示す。
(The data.frame UN, which is included in the car library, consists of two variables as GDP (gross domestic products) and infant.mortality (infant mortality rates) in the United Nations countries. We drew the scattergram of gdp being horizontal axis and infant.mortality being vertical axis, with 50% and 95% probability ellipse. Then we calculated the Pearson's product-moment correlation coefficient and Spearman's rank correlation coefficient and tested the null-hypothesis that those coefficients are 0, with significance level being 0.05. The code and result with its interpretation are shown below.)
学籍番号・氏名とともに,下のフォームと解釈文を穴埋めして送信せよ。
(Please write the registry number and name, fill the boxes A to D.)
コードは以下の通り。
(The code is shown below.)
require(car) # load and activate car package
UNs <- subset(UN, complete.cases(UN)) # exclude cases with missing values
dataEllipse(UNs$ , UNs$
, UNs$ , levels=c(0.5,0.95)) # draw scattergram with probability ellipse of 50% and 95% CI.
, levels=c(0.5,0.95)) # draw scattergram with probability ellipse of 50% and 95% CI.
cor.test(UNs$, UNs$) # estimate Pearson's r and test the zero-correlation
cor.test(UNs$, UNs$, method=" ") # estimate Spearman's rho and test the zero-correlation
") # estimate Spearman's rho and test the zero-correlation
# (cf.) As shown below, logarhythmic transformation makes correlation closer to be linear.
# Lgdp <- log10(UNs$gdp)
# Linfant.mortality <- log10(UNs$infant.mortality)
# dataEllipse(Lgdp, Linfant.mortality, levels=c(0.5, 0.95)) # probability ellipse
# cor.test(Lgdp, Linfant.mortality) # Pearson's correlation
# cor.test(Lgdp, Linfant.mortality, method="spearman") # Spearman's rank correlation
図が描かれた後,ピアソンの相関係数がゼロと差が無いという帰無仮説が検定され,さらにスピアマンの順位相関係数がゼロと差が無いという帰無仮説が検定される。ピアソンの相関係数の点推定量は-0.511,スピアマンの順位相関係数の点推定量は-0.807であり,有意確率はどちらも5%より遥かに小さいので,有意水準5%で統計学的に有意な相関 (1. がある|2. はない)といえる。
(1. がある|2. はない)といえる。
(After the graph is drawn, Pearson's correlation coefficient and Spearman's rank correlation coefficient are calculated, and the null-hypotheses that the coefficients are not different from 0 are tested. The point estimates of the coefficients were -0.511 and -0.807, and the p-values were far smaller than 0.05. Therefore, we can conclude that there (1. was | 2. was not) statistically significant correlation at 5% level.)
解答例
| 項目 | 解答例 |
|---|
| gdp |
| infant.mortality |
| spearman |
| 1 |
※これは回帰分析でなく,あくまでgdpとinfant.mortalityの相関関係を調べているだけなので,ボックスAとBは逆でも可。
主な質問・コメントへの回答
- 進度についてのアンケート結果
- 速い=27名,ちょうどいい=35名,遅い=1名
- 遅いと感じている人には涙を飲んでいただくしかありません。周りの人に教えてあげてください。ちょうどいいという意見が回答者の過半数だったので,今後もこのペースでいきたいと思います(なお,大事なところは時間をかけます)。
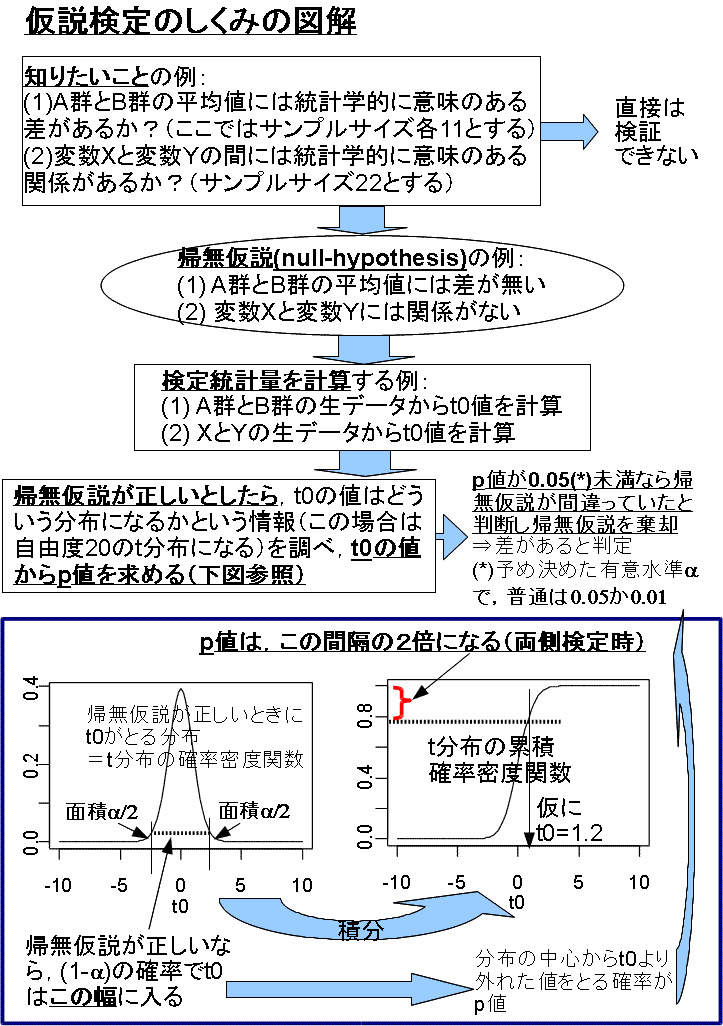
- 帰無仮説の棄却がわかりません。
- 第5回に説明し,その課題解答例にもまとめを書きましたが,確かにつまづきやすいところなので,下に図解しておきます(やや大雑把ですが,理解しやすいのではないかと思います)。
- pc24のパソコンの起動が他のものより遅い
- ハードウェア的に調子が悪い場合は,学務課経由でメディアセンター昭和分室に連絡してメンテしてもらうしかありません。
- まだ空いているコンピュータはいくつかあるので,使うコンピュータを変えてみてはいかがでしょうか。
- 関数ごとに(X,Y)と(X~Y)のどれがOKかを覚える方法はありますか?
- 基本的に(X~Y)は,YによってXを説明するときにしか使いません。回帰モデルの当てはめに使うlm(X~Y)や分散分析のoneway.test(X~Y)が代表的です。"X~Y"がモデルという1つのオブジェクトとして関数に渡されます。(X,Y)は,関数に2つの引数XとYが渡される構文です。相関関係には向きが無いのでcor()の引数は2つの変数X,Yであって,cor(X,Y)となります。ちなみにcor(X,Y)とcor(Y,X)は同じ結果になります。pairwise.t.test()は,第2引数によって決まるグループ間の多重比較なので,第2引数によって第1引数を説明しているようにも見えますが,区切りはコンマです。これはむしろpairwise.t.test()やpairwise.wilcox.testが()特殊なのだとお考えください。
- Rが学べるサイトをもっと知りたいです。
- とりあえずここからリンクを辿ってみてください。
リンクと引用について