最終更新:2017年 2月 10日 (金曜日)
Awesome-R(2016年11月29日)
Rのキュレーションサイトとして,awesome-r.comというサイトがtweetされていて,見てみたらgapminderのデータがパッケージ化されていた。知らなかった。パッケージサイズも150KBくらいだし,これは常用パッケージリストに入れよう(web上のリストも更新した)。インストールしてロードしてexample(gapminder)すれば国際保健の教育ツールとしての価値は一目瞭然だろう。(鵯記1464)
(追記:gapminderパッケージについては,半年前に触れたのに完全に忘れていた)
ビデオの表情から感情分析(2016年11月12日)
Microsoft Analyticsからのtweetで紹介されているのは,ビデオ画像の人の表情から感情を分析するウェブサービス+APIだそうで,面白そう。記事の最後にはRコード付き。使っているパッケージは超有名なdplyr,stringr,tidyrに加えてexploratory。 64ビット版しかないが,その分高速で高機能なMicrosoft R Openの3.3.2は11月21日リリース予定だそうだ。
反復測定分散分析のエラー(EZR)(2016年11月8日;12月18日)
4限と5限は公衆衛生実習で,先週まで3週にわたってやってもらった実験のデータ解析の方法をEZRを使って教える。本当はEZRではなく,素のR(または+RStudio)でやりたいのだが,それだとたぶん取っつきにくくて誰も覚えてくれなそうなので,約3時間でゼロからするには仕方ない妥協。まあ,院生でさえEZRから素のRへ進んでくれる人はほとんどいないし,それだけ,良く使う解析はEZRだけでできてしまうということでもあるが。
実験データの解析方法を実演する講義のため,自治医大のサイトからEZRをダウンロードしてインストールし直し,反復測定分散分析をやろうとしたら,とくにエラーが出るわけではないのだが結果が出ないので焦った。学生実習用のコンピュータで古いバージョンでやる分には何の問題も起こらないが,Windows 10のAnniversary Update後に自治医大サイトからダウンロードしたR本体入りEZRの最新版をインストールした状況ではうまくいかない。R-3.3.1にRcmdrとRcmdrPlugin.EZRをinstall.packges()を使ってインストールしておき,Rを起動してからlibrary(Rcmdr)とし,プラグインをロードしてRcmdrを再起動するという起動の仕方をすると,問題なく反復測定分散分析ができた。原因は不明だが,とりあえず問題は回避できたので良かった。
火曜の公衆衛生実習の班ごとの発表の中に,EZRで反復測定分散分析をした班があった。EZRの場合,carパッケージのAnova()関数で実行する際に,自動的に交互作用項が入ってしまうので,交互作用項の効果が有意でないからモデルから除去したいと思ってもEZRだけではできない。解決策として,縦長形式にしてaov()でError()に個人を与えるという方法も考えたが,よく考えたら線形混合効果モデルでいけるので,博士後期の統計テキストに書いたように,lmerTestパッケージのlmer()関数を使えば良い。ただ,いろいろと試行錯誤したがlmer()でAnova()と同じ結果を得ることができなかった。問題解決まではもう1歩か。(鵯記1474)
R Studio 1.0リリース(2016年11月2日)
とうとうRStudio 1.0正式リリース。長い間バージョン0.9.***でありつつも大変便利に使わせていただいてきたが,やっと1.0になった。
R-3.3.2リリース(2016年10月31日)
R-3.3.2がリリースされた。Windows 7以降で,使っているテーマによっては,Alt+Tabを使った後にRtermが入力を受け付けなくなることがある,という講習会などでの講師泣かせなバグがフィックスされた模様。bartlett.test()とかxtabs()といった,比較的良く使う関数についてもバグフィックスされて振る舞いが変わる場合があるため,更新時には注意深く結果を見ておくべきであろう。なお,Microsoft R Openはまだ3.3.1のようだ。
『みんなの医療統計 12日間で基礎理論とEZRを完全マスター!』(2016年9月22日;27日)
大阪大学の新谷歩先生が,『みんなの医療統計 12日間で基礎理論とEZRを完全マスター!』という本を今年の3月に出版されていた。開発者の神田先生によるもの以外のEZRの本は初めてと思う。エビデンスベーストヘルスケア特講と公衆衛生学実習ではEZRを使っているので,参考文献としてあげておこう。
AICとベイズが古典的統計解析にも使えることを示した入門書としては,これまで読んだ本の中では,1995年に出た鈴木義一郎『情報量規準による統計解析入門』がベストだと思っているが,2年半ほど前に書かれた小島寛之さんのweblogにも,「ミス・ユニバース日本代表の統計学」と「赤池情報量基準ってナニ?」という良い書評があった。同書が絶版なのは非常に勿体ないことで,せっかく講談社なのだから,ブルーバックスから再刊されたら良いのにとも思うが,同じ著者でやはり絶版になっている『先を読む統計学―「情報量規準」とは何か』というブルーバックスの本と内容的にある程度被っているので難しいか。
新谷歩『みんなの医療統計:12日間で基礎理論とEZRを完全マスター!』講談社,ISBN 978-4-06-156314-8(Amazon | bk1 | e-hon)は,まあ内容的にはとくに新しいことはないように思うが,カラーをふんだんに使った見やすい本で,開発者の神田さん以外の著者によるEZR本としては初めてのものだし,比較的安いので,院生に勧めるには良い本かもしれない。
Microsoft R Openを入れてみた(2016年9月19-20日)
奥村さんの『Rで楽しむ統計』の1ページに「最近では他の実装(Microsoft R Openなど)もある」と書かれていたので,Microsoft R Openをデスクトップマシンに入れてみた。Revolutionを引き継いだ実装なので,いろいろと高速化がされているらしいのだが,少なくともWindows版の場合,インストール時にMDIかSDIか選ぶオプションがなくMDIになってしまうのは残念。もちろんGUIプリファレンスでSDIに設定して保存してから再起動すればいいのだが。ちなみにR Studioからも呼べるらしいが,今日はそこまで試す時間はない。
Microsoft R Openをインストールした後でR Studioを起動すると,起動されるRが自動的にMicrosoft R Openになっていた。これを元のRを使うように変えるには,ToolsのGlobal Optionsから,呼び出すRをどれにするか選んで,いったん保存してR Studioを終了してから再度起動すればいい。
拡張マクネマー検定(Bowker's test)のゼロ割回避(2016年9月11-13日;2017年2月8日追記)
拡張マクネマー検定(McNemar test for symmetry,あるいは,Agrestiのテキスト"Categorical Data Analysis"のpp.424によると,Bowker's testともいうらしい)を使ったらRのmcnemar.test()がNaNを返してくるというエラーに遭遇した。通常の2x2のMcNemarの検定の場合は,N12(1回目はカテゴリ1で2回目はカテゴリ2に変化した人数;以下同様)とN21の両方がゼロだったら2回の間でまったく変化していないということだから,検定する必要がなくなり問題はない。しかし,カテゴリ3つ以上の場合は,例えば,N13はゼロでないがN23とN32がゼロ,という状態だと,(N23+N32)が分母になる項で"Division by zero"エラーがでてしまって,カイ二乗値の計算結果自体がNaNになってしまうのだ。この問題への対処としては,その項をスキップするか(カイ二乗検定をするときにスキップした項数だけ自由度を減らせば良いはず),あるいは全部のセルに極めて小さい数字を足すかすれば計算できるし,実際に"Division by zero"を避けるために全部のセルに0.01を足したと書いてある文献を1つ見つけたのだが,有名どころのテキストにはどうすべきか書かれていないのだった。これはどうするのが良いのだろうか?
ちなみに,共立出版「Rで学ぶデータサイエンス」シリーズの藤井良宜『カテゴリカルデータ解析』には,丁寧に拡張マクネマーの考え方が書かれているけれども,やはり分母がゼロの項をどうすべきかについては触れられていなかったし,「Wonderful R」シリーズの奥村晴彦『Rで楽しむ統計』では,拡張マクネマーについては触れられておらず,そもそも連続量をカットオフで二値化したものならば連続量のままt検定した方が良いという説明がされていて,それはその通りなのだけれども,今回の場合は元々4水準の名義尺度なので,そういう王道はとれないのだった。
結局,今回はカテゴリを併合して2x2にした方がすっきりして,かつdivision by zeroの問題も消えたので良かった。けれども,一般論としてこの場合にどうしたら良いのかは知っておきたいところだなあ。
全部のセルに0.01を足すのは,検定したい行列オブジェクトをxとして,mcnemar.test(x+0.01)で済むので,分母がゼロになる組合せをスキップする最低限の関数(mct.R)を書いてみた。使い方はmct(x)とするだけ。
この件,すっきりしないので某学会の編集委員会で会ったときに村上さんに相談しておいたら,2017年2月8日にメールがあって,"Marginal Homogeneity Tests"で検索してみては? とsuggestionいただいた。やってみると,このページが見つかり(そこからリンクされていたMcNemar test関連の説明),作者がMS-DOS(Windowsのコマンドプロンプトでも動作する)のソフト(説明とダウンロード)を公開していた。そこでzipファイルをダウンロードして展開し,input.txtを
Example of testing zero-division possibility
3
Rater 1
Rater 2
ord
30 0 0
0 10 2
0 4 8
という内容のinput2.txtに書き換え,mh.exeをダブルクリックして,input file:にinput2.txtと打ち,output file:にmt-zero-sample.txtと打ってみたら結果が出た。mt-zero-sample.txtにはたくさんの検定結果が出ているが,ゼロ割りエラーは出ていない。
ちなみに,Rで
source("http://minato.sip21c.org/swtips/mct.R")
x <- matrix(c(30, 0, 0, 0, 10, 4, 0, 2, 8), 3)
mcnemar.test(x)
mcnemar.test(x+0.01)
unlist(mct(x))
とすると以下の結果となる。全部のセルに0.01を足してMcNemarをやった結果はmh.exeのBowker Symmetry Testの結果とほぼ同じで(微妙な差があるが誤差範囲だろう),分母がゼロになる組合せをスキップして計算した結果は,mh.exeのStuart-Maxwell Testで保守的でないdf=1を採用した結果と一致した。ということで,このとき考えた方法はそれぞれ先人の名前が付いていることがわかった。結局どれが良いのかはわからないのだが。mh.exeではexact testの結果も出てくるので,それが何をやっているのかを理解してRで実装するのが良いと思うが,そこまで読み解いている時間が今は無い。
McNemar's chi-squared = NaN, df = 3, p-value = NA
McNemar's chi-squared = 0.66445, df = 3, p-value = 0.8815
X2 df p
0.6666667 1.0000000 0.4142162
fmsbパッケージ更新予定(2016年9月9日)
何日か前にもメモした通り,fmsbパッケージはhlifetable()の追加,oddsratio(),riskratio(),rateratio()関数におけるp値と信頼区間の扱いの改良を含むアップデートが必要なのだが,昨日付けで厚生労働省から人口動態統計2015確定数が公表されたので,Jvitalデータも更新しなくてはいけない。
ご恵贈御礼:奥村晴彦『Wonderful R 1: Rで楽しむ統計』共立出版
奥村晴彦『Wonderful R 1: Rで楽しむ統計』共立出版,ISBX978-4-320-11241-4をご恵贈いただいた。普通の統計のテキストとは一味違った構成で面白そう。例えば,「Chapter 4 事件の起こる確率」では富の分布で2項分布をポアソン分布で近似できることを示した後,偶然の再分配を導入すると指数分布に近づくという図を示しておいて「貧富の差のシミュレーションは練習問題として残しておく」という心憎いアクティブラーニング誘導。さらに続いて,地震の確率をポアソン過程と考えた場合の説明からBPTで周期的な発生確率の振動を考えた場合の計算を示し,次にポケットガイガーの測定値を使って「ランダムに事象が起きる」ことのシミュレーションとの類似を見せておいて,『ショパンの「雨だれ」(図4.6)のように一定の時間間隔で起きるのではなく……』と楽譜を提示するセンス。果てはポアソン分布の信頼区間について簡単な求め方と問題点を示し,素粒子物理で使われるようになった新しい方法であるFeldman-Cousinsの信頼区間の話にまで展開する。教科書にはしにくいかもしれないが,Rを自習したい人にはうってつけと思うし,もう10年以上Rを使ってきたぼくでも新しく知ったことも多いので(binom.test()は良く使うが,poisson.test()は知らなかったし,もちろんFeldman-Cousinsの信頼区間は知らなかった),少しでもRやデータをいじることに関心がある人なら読んで考えて手を動かしてみて損はないと思う。なお,本書では付値に<-ではなくて=が使われている。p.3に書かれている通り,かなり前から=も使えるのだが若干問題が生じる場合もあり,ぼくは未だに<-を使ってしまうが,入力の手間はもちろん=の方が少ないわけで,これからRを使う人は=で付値としても良いのかもしれない。また,「Chapter 5 分割表の解析」の中で,オッズ比とp値,信頼区間についてさまざまな求め方が説明されていて,拙作fmsbのoddsratio()も取り上げていただいているが,去年4月や一昨年12月に書いた通り,この関数はp値を求めるときと信頼区間を求めるときに違う考え方を使っているために,時々見かけ上変なことが起こる(という話を他ならぬ奥村先生とかつてtwitterでやりとりしたことがある。本書ではp.79のfisher.test()での非心超幾何分布を使った最尤推定の中身の説明――これ自体,こんなにわかりやすく説明されている本は実はあまりない――に続いて,fisher.test()の場合に同じ問題が起こる話とexact2x2パッケージのfisher.exact()関数を使った解決策について書かれていた)ので,今度のfmsbアップデート(健康余命を求める関数を入れるために近々予定している)には,確実に対処したい。
9,000パッケージ(2016年8月22日)
[r-devel]のメーリングリストで,CRANに登録されたパッケージ数が9,000を超えたことを知った。最近は半年で1,000増えるペースなので,来年2月には1万パッケージに到達しそうだ。しかしここまで増えてくると,車輪の再発明も多そうだな。
radarchartなど(2016年8月6日)
知らなかったが,radarchartに特化したパッケージというか,javascriptのCharts.jsライブラリを使ったインタラクティブなradarchartのパッケージが今年公開されていた。論文投稿に使うにはbaseの出力の方が向いていると思うので,ぼくは自作のfmsbパッケージのradarchart()関数を使い続けるけれども,github界隈のハドラーさんたちはこっちの方が好きだろうなあ。
Rのマルチバイト処理へのクレームは,ぼくの理解では,そもそも間瀬先生からのアピールを受けてProf. Brian Ripley(以下R教授)がコミットするまでコアチームでは気づかれてさえいなかったし,最初はソースへのパッチという形でマルチバイト処理をほぼ独力でやってくださっていた中間さんのコードがR教授主導でR本体にマージされてからも,中間さん以外に本格的にここにコミットする日本人はいなかったので,仕方が無かったとしか言いようがない。中間さんはずっと,積極的に本体のコーディングにコミットする日本人が増えることを期待されていたが,パッケージ開発とは段違いにハードルが高いので,ぼくを含め,統計解析のためにRを使っていた研究者はコミットできなかった。いまでは,昔とは違って多くの本職プログラマがRを使っているのだから,本格的にマルチバイト回りの新しくてきれいなコードを作ってR教授に提案すれば(とはいえ,カイ二乗検定の連続性の補正についての青木先生からの提案も,Yatesの原典通りという思想にこだわって取り入れてくれなかったR教授のことだから,簡単に採用されるとは限らないが),改善されるのではなかろうか。
gapminder(2016年6月27日)
gapminderだが,cranを調べたら同名のパッケージがあった。ブリティッシュコロンビア大学のJennifer Bryanさんがパッケージにしていた(cranにも入っている)。変換プロセスが,この方が公開されているプレゼンファイル群の1つとして解説されているが,これも興味深い。使い方は,library(gapminder); example(country_colors)してみるだけでも面白い。aggregate()という関数はこれまで使ったことがなかったが意外に使いやすい。例えば以下。
aggregate(lifeExp ~ continent+year, gapminder, (meansd <- function(x) sprintf("%f (%f)", mean(x), sd(x))))
Kobe.R #25(2016年6月26日)
13:10頃研究室を出て大阪へ。今日はKobe.R#25(天博との共催)ということで,気象データ解析。YuMake.LLC佐藤拓也さん。防災・減災をこれまで主にやってきた。 センサーで観測した気象データについて(佐藤拓也さん)。Weather APIと気象センサの話。ベースは気象庁のデータ。バイナリやXML形式は扱いにくいので,JSONに変換してAPIで提供している。PDFから変換したものや独自に計算したデータも含む。気象情報APIは三種類(天気予報,防災・災害情報,観測情報)。天気予報は,今日明日天気予報API,週間天気予報API,時系列天気予報APIを提供している(リンク先をみると,初期費用5万円だ)。こういうデータをいろいろな分野のデータと掛け合わせて分析している。センサとしてはNetatmo(リンク先はアマゾン。Gigazineにも紹介記事があった)というのを使っている。屋内モジュール,屋外モジュール,風速計,雨量計の4種類。気温(℃),湿度(%),気圧(hPa),CO2濃度(ppm),騒音(dB)。CO2濃度と騒音は屋内モジュールで測定。屋外センサは単4電池で2年間稼働。雨量計は転倒マス方式。Max 150 mm/h。風速計は4つの超音波センサで測定。風向と風速が出る(単3電池4本で2年間もつ)。家庭用WiFiで接続するのが基本。simフリーWiFiで試験接続。Soracom 3Gで接続確認がとれている。5分間隔で自動アップロード。スマホアプリで現在状況を確認可能(iPhone, Android, Windows)。上部が屋外状況,スワイプで雨量,風速が閲覧可能。下部は屋内状況。週間天気予報付き。WEBからも観測状況の確認が可能(これか?)。観測状況がグラフで細かにわかる。観測データダウンロードも可能。これによる奈良県生駒市某所での観測データを本日使う。
簡単な天候データ分析(河原弘宣さん)天候に関わるtwitterの分析もやってみる。天候データ分析の活用事例としては,日本気象協会が需要予測をして食品ロスの削減に成功した(省エネ物流)というニュースが先日あった。今日はtwitterのテキストデータの分析とYuMakeからの数値データの分析。しかし本当は可視化の後でどう活用するのかが大事。そこは今日は扱わない。というわけで,実際のデータ解析は井上さんにバトンタッチ。
R及び分析手法の紹介(井上英郎さん)食肉検査員で疫学には興味があるエンドユーザとして,ロジスティック回帰分析の話を。理由は,脂肪壊死症という原因不明の病気が和牛に多く発生し死んでしまう。原因を突き止めたくて始めた。疫学ではデータが手に入るプロセスを推定することが大事なのでロジスティック回帰分析が良く使われている。職場でRの解析結果を説明しても理解されないので,Rでのロジスティック回帰の方法と,それをExcelで実施する方法。ロジスティック回帰にはglmとVGAM::vglmとMASS::polrが使える。注意点1:分離(完全に分かれてしまう。glm.fitアルゴリズムが収束しませんでしたとか),brglm::separationでわかる。注意点2:過分散(緑本7章参照)。dispmod::glm.binomial.disp()でわかるらしい。過分散がある場合は,GLMM::glmmML()を使うと良いらしい。今回使うデータはiris(ネタ元は同志社大学金さんの「Rとカテゴリカルデータのモデリング(2)」の書籍版らしい)。3種類を多項ロジスティックで。結果をpredictで得る(type="response"が応答確率を計算させるオプション)。これで得られた係数をExcelに式として入れると,誰でも結果を使えるようになる。今後はglmnetやcaretパッケージを使ってみたいとのこと。(■RExcelって今どうなっているのだろう?)
気象データの可視化をしてみよう(河原弘宣さん)データと予測データのマッピングをするためのRコードはKobe.Rのサイトからダウンロードできる。データの取得はhttps://apps.twitter.com/から。ログインする(電話番号が登録済みである必要がある)。twitteRパッケージとROAuthパッケージを使ってデータを取得する。文字エンコードはiconv('雨 OR 傘', to="utf8")が必須。15分間で180回以内なら自動的にスクリプトを走らせて(Windowsならタスクスケジューラ,Linuxならcronで)データを取得して良い。テキストデータの分析はRMeCabで。リツイなどがあるので,前処理が必要。日本語だけ抽出して単語の前後関係を可視化するとか。この話は,雨と傘に注目したテキストマイニングの例。(■内容的には去年のR研究集会@統数研の(7)や(9)に近いか?)次の話は数値データ解析。おでんが売れる日は前日より気温が下がった日かどうか。緯度経度データも入っているので,leafletパッケージを使って可視化。GapminderをGoogleが買収して,その機能をRで使えるようになったという話は知らなかった。
今日知ったNetatmoだが,地図情報を見たらメラネシアではニューカレドニアにしかまだないが,意外に世界中にあるのだなあ。サラワクに設置しているのは研究者だろうか。シンガポールには15ヶ所もあった。例えば100台くらい買ってソロモン諸島に設置し,気象データを自動記録するのと同時に3ヶ月くらい前向き研究(できれば毎週したいが,それだとfeasibilityがなさそうだから月一度くらいのペースで,指先採血+RDTでマラリアとDengueの検査+質問紙調査+行動観察など)をして,蚊が媒介する感染症と微気象の長期的な関係の分析をしたら,これまで不可能だったレベルの感染症数理モデルの実証ができそう。マレーシアのDengueのデータは,かなり細かいレベルで微気象データがあったが,たしか気温と湿度だけだったので,これだと風速や雨量まで取れるのが大きいと思う(蚊の行動へは風速の影響が大きいので)。予算的にはざっと1000万円くらいかかるが,申請する価値はあるかも。とはいえ,自分で書く暇はないので,誰か書いてチームに入れてくれたら嬉しい。
3.3.1リリース(2016年5月29日;6月21日)
R-3.3.1(コード名は"Bug in Your Hair"。直訳したら「あなたの髪に虫」だが,例によってPeanutsの台詞で,Peppermint PattyがCharlie Brownに言っているようなのだが,Charlie Brownって髪なんて無かったんじゃ……)のリリースは6月21日だそうだ。6月はいろいろ楽しみなことが多いのだが,その前に積み残し仕事を消化しないと楽しめない。
予定通りR-3.3.1がリリースされた。
質的研究のパッケージ+RRR(2016年5月23日)
ちょっとだけ質的研究ソフトについてメモ。佐藤郁哉さんは『質的データ分析法』や『QDAソフトを活用する:実践質的データ分析入門』などで,MaxQDAという市販ソフトの利用を推奨していて,ご自身のサイトでいろいろサポート情報を書かれているが,代替ソフトを検索してみたら,RQDAというRの追加パッケージ(UTF-8であれば非英語でも処理可能と書かれている)と,CATMAというソフトがフリーのようだ。keywordbeeというソフトもフリーのようだったが,リンクをたどれなかった。時間をみてRQDAを試しておくか。
Reduced Rank Regression (RRR)について,とりあえず文献検索した結果のメモ。その1,その2,その3,その4。
3.2.4改訂版リリース(2016年3月17日; 2016年4月16日追記)
■R 3.2.4-revised is releasedというアナウンスが流れた。3.2.4は3.2系最後の超安定板であるべきなので、異例だが2つの不具合を修正したバージョンで置き換えたということらしい。
■Makefileの不具合1つと,format.POSIXlt()のバグフィックスとのこと。
■例えば,format(as.POSIXlt(paste0(1940:2000,"-01-01"), tz="CET"), usetz=TRUE)と打つと,最後の2つが"CET"でなく"CEST"という表示になっていたが,それを修正した。
(追記)メールを見たら,R-announceから,当初予定に無かったR-3.2.5がリリースされたとの報。R-3.2.4改訂版がトラブルを起こすシステムがいくつかあったためなので,R-3.2.4改訂版が無事に動いていれば更新の必要は無いとのこと。
mapdataパッケージのmap()で太平洋を描く工夫(2016年3月16日)
■mapdataパッケージでmap("worldHires")の地図は日付変更線が左端のX座標-180(西経180度)と右端のX座標180(東経180度)になっているので,太平洋を中心にサモアとハワイを1枚の図に入れようと思うと工夫が必要。
■layout(t(c(1,1,1,2,2)))としてグラフィックウィンドウを左対右が3:2になる二画面に分割し,まずpar(mar=c(1,1,1,0))で左画面の右マージンをゼロにしてからmap()のオプションでxlim=c(120,180)と指定して60度分を描画し,次にpar(mar=c(1,0,1,1))で右画面の左マージンをゼロにしてからmap()のオプションでxlim=c(-180,-140)と指定して40度分を描画すると,それらしい地図になった。普通はどうするんだろうか?
順位相関係数の信頼区間についてのメモとR-3.2.4インストール(2016年3月14日,鵯記,15日に追記)
■奥村さんが昨日tweetしていたKryvasheyeu Y et al. (2016) Rapid assessment of disaster damage using social media activity. Science Advances, 2(3), e1500779, DOI: 10.1126/sciadv.1500779は,確かにρやτのような順位相関係数とともに,明らかに相関があるのにp値を出しているのはあまりinformativeではない(この場合,検定の帰無仮説は「無相関」だから,p値がどれほど小さかろうと,「無相関ではない」確信の度合いが増すだけ)。当然,信頼区間を出す方が良いのだが,Rのcor.test()ではmethod="pearson"の場合しか信頼区間は表示されない。cor.test()でmethod="spearman"のとき,二つの変数をxとyとするとスピアマンの順位相関係数ρそのものはcor(rank(x), rank(y))で求めている(getS3method("cor.test", "default")と打って内部コードを見るとそうしている)が,ρをz変換したものが近似的に正規分布に従うと仮定しないとcor.test(rank(x), rank(y))で出てくる信頼区間がρの信頼区間にはならないので,そう言い切ってしまうのは抵抗を感じる。たぶんbootstrapで求めるのが原理的には正しいやり方で,この記事によると,ρの信頼区間を出してくれるのはパッケージRVAideMemoireのspearman.ci()関数であり(bootstrapの回数はnrep=オプションで指定するが,まあ1000もあれば良かろう),ケンドールのτの信頼区間を出してくれるのはNSM3パッケージのkendall.ci()関数である(bootstrapするときは,bootstrap=TRUEオプションを付け,B=オプションで回数を指定する)。せっかくだからエビデンスベーストヘルスケア特講のテキストの順位相関係数のところに付記しておこう。なお,当該論文のFig.2のパネルAみたいなU字型の関係は順位相関ではダメなので,かつてメモしたMICを使うしかないだろう。
■(2016年3月15日追記)上記のいくつかの方法で順位相関係数の信頼区間を求めるためのRコード。
■R-3.2.4がミラーにも来たのでWindowsにもインストール中。mran (Microsoft R Application Network)から,Microsoftが買収するまでRevolution R Openだったものが(つまり,マルチコア対応のRが),Microsoft R Openとしてダウンロードできるのだが,そっちはまだ3.2.3だな。
R-3.2.4リリース(2016年3月10日,鵯記)
■R-3.2.4が予定通りリリースされた。よく使う機能で目に見える変化は,cor.test()がきわめて小さいp値をより正確に計算するようになったという点くらいか(試しに,まだ3.2.3のWindows版でcor.test(1:10, c(2:10, 11.2))と実行するとp-value = 2.665e-15となったが,同じコードを3.2.4にアップデートされたubuntu上のRで実行したらp-value = 2.54e-15となった。95%信頼区間はどちらでも同じ値が表示されていた)。今回,[Rd]メーリングリストに,リリース直後にOracle Enterprise Linuxでビルドしようとした人から,たぶん@であるべきところが$になっているためにエラーが出てビルドできないというバグレポートがあり,すぐに,R-patchedで修正済みでR-3.3.xではなくなる問題だという返事があった。もちろん$を@に直すだけでもビルドできるとのこと。
cranパッケージ8,000到達(2016年2月29日,鵯記)
■[Rd]メーリングリストにcranパッケージ数が8,000に到達という投稿があったので推移をグラフにしてみた(tweet)。コードは140字に入らないので,スラドに投稿しておいたが,ここにも貼っておく。
Npkg <- data.frame(
dates = as.Date(c("2003-04-01","2004-10-01","2007-04-12","2009-10-04",
"2011-05-12","2012-08-23","2013-11-08","2014-10-29","2015-08-12",
"2016-02-29")),
N = c(0.25, 0.5, 1:8)*1000)
plot(Npkg, type="b",main="CRANパッケージ数の推移")
# Source: https://stat.ethz.ch/pipermail/r-devel/2016-February/072388.html
■このコードで描かれるグラフを見ると,cranに登録されるパッケージ数が加速度的に増えていることがわかる。cran以外にもGitHubだけにあるパッケージとかもたくさんあるので,今後どこまで増えていくのか,まだ見当もつかない。
R-3.2.4とR-3.3.0のリリース予定について,及び多項ロジスティック回帰(2016年2月23日,鵯記)
■2月17日にアナウンスメールが流れていたのをメモし忘れていたが,Rの次のリリースは3.2系最終版のR-3.2.4(コード名:"Very Secure Dishes")で3月10日予定。その次はいよいよ3.3系に入ってR-3.3.0が4月14日リリース予定なわけだが,公表されたコードネーム"Supposedly Educational"をこれまで通りPeanutsから探しても,これくらいしか近いものが見つからなかった。しかしこれはSally Brownの言葉だが,コードネームとは若干違って"Supposed to be educational"となっている。Peanuts以外からそのものずばりを探すと,文の一部として使われている例(とくに「おそらく教育的な」と"Slave Tetris"を形容するもの)が多かったが,イカレたプログラマの短編コミックみたいなものがあった。なかなか面白いので他のも見てみたいところだが,ひょっとするとこの方のオリジナルなんだろうか?
■多項ロジスティック回帰分析をしたいという相談を受け(厳密に言うと,アウトカムが3水準のカテゴリで,3水準以上のカテゴリからなる要因について,リファレンスカテゴリに対しての各アウトカムのオッズ比を,他の変数の影響を調整した上で得たいという相談だったが,たぶん素直に考えたらこれだろう),共立出版の「Rで学ぶデータサイエンス」シリーズに入っている,藤井良宣『カテゴリカルデータ解析』を貸して,第6章を読んで真似してみたら? とアドヴァイスしたのだが,6.5にあったのはnnetパッケージのmultinom()関数を使うやり方で,オッズ比を求めるのが若干大変かもしれない。他のパッケージと比べたページを見たところ,VGAMパッケージのvglm()関数を使うのがわかりやすいと思った。とくにこのページは参考になると思う(翌日,エビデンスベーストヘルスケア特講Iのテキストに追記した)。
RjpWikiの旧URL廃止(2016年2月16日,鵯記)
■RjpWikiの旧URLが廃止になったということでリンクを修正していて気づいたが,R-jpメーリングリストが消滅してしまったようだ。こうして時代は移ってゆく。
『R言語徹底解説』の書評情報(2016年2月12日,鵯記)
■Qiitaに「R言語徹底解説」入門と題した同書のレビューがあることを@kazutanさんのtweetで知った。実に的確なレビューだと思った。
世界の年平均気温の推移について(2016年2月2日,鵯記)
■気象庁が発表した世界の年平均気温の推移について,Rでweb上の表からデータをスクレイピングして図示するコードはXMLパッケージを使えばとても簡単で,数行で済む。たぶん数値が更新されてもコードは書き換えずに新しいグラフが作れるはず(なお,グラフの縦軸は基準値からの偏差なので注意。実際の値には意味が無いそうだ)。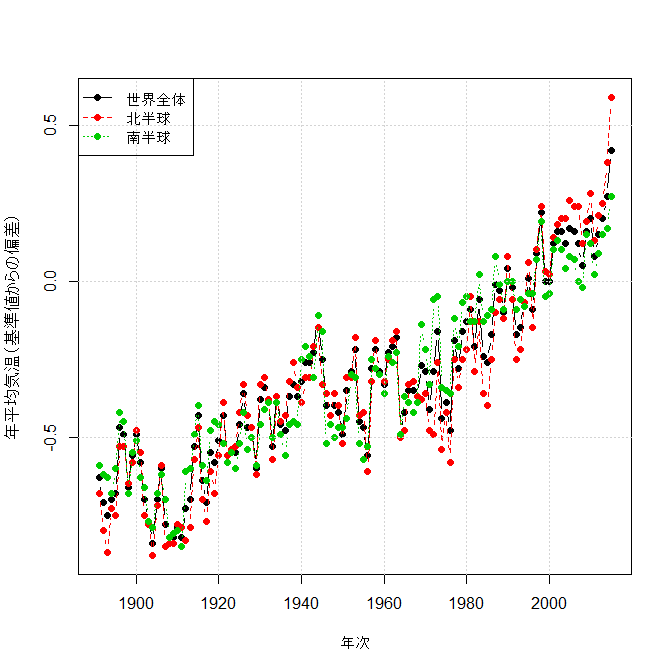
世界全体についての回帰直線を追記したいなら,abline(lm(x[,2]~as.integer(strtrim(x[,1], 4))), lty=1, col=1) でいいし,x[,2]をx[,3]にすれば北半球,x[,4]に変えれば南半球の回帰直線が描ける(重ね描きしていくなら,もちろんltyとcolもそれぞれ2と3にする)。もう少し真面目に時系列データにするならこうか? こうしておけば,library(forecast); plot(forecast(auto.arima(z[,1]), h=50))で世界全体の今後50年の幅付き予測とかもできる。
相対値と順位の関連を見るための散布図を描く方法(2016年2月2日,鵯記)
■十数種類のモノについて数十人の対象者にある軸での順位と,別の軸での0~100%の相対値をつけて貰い,それぞれのモノについて順位と相対値の関係を見るための図を描こうとすると,どうしても散布図では重なりが出てしまって様子がわからない。さりとて普通にstripchart()で描こうと思うと,無い順位が詰まってしまって,ほぼ全員が高い順位を付けたモノと,ほぼ全員が低い順位を付けたモノの違いが図の上で一目でわからない。つまり別々のモノについて,共通の順位軸を与えたい。こういう場合は,順位をそのまま数値としてstripchart()に与えるのではなく,factor(levels=)を使って要因にしてしまえばよい。例えば,
とすれば良い。x1 <- sample(1:6, 100, replace=TRUE)
x2 <- sample(10:15, 100, replace=TRUE)
y <- sample(1:10, 100, replace=TRUE)
layout(1:2)
stripchart(y ~ factor(x1, levels=1:15), vert=TRUE, method="jitter")
stripchart(y ~ factor(x2, levels=1:15), vert=TRUE, method="jitter")
Correspondence to: minato-nakazawa[at]umin.net.