- 舟尾さんのR-Tipsのpdf版公開(2004年2月3日)
- ●Tipsというより,マニュアルといった方がいいと思う,舟尾さんのR-Tipsのpdf版とTeXのソースとeps形式画像ファイルが竹澤さんのサイトで公開された。たぶん,統計はわかっているけれどRでそれをどうやったらいいのかを知りたいというユーザには,物凄く役に立つ文書だと思う。280ページもあって全部印刷するのは辛いので(目次からジャンプできるので印刷しないでオンラインマニュアルとして使うのでも便利だと思うが),どこかの出版社が出版してくれたら嬉しい(ライセンスについての舟尾さんのご意向は不明だが)。少なくともぼくは買う。
- 新刊紹介(2004年2月18日; 2月27日変更)
- ●新刊というよりもぼくにとっての新着だが,John Maindonald and John Braun: Data analysis and graphics using R, Cambridge Univ. Press, 2003, Cambridge, ISBN0-521-81336-0は,いい本だと思う。区間推定の方が仮説検定よりずっといいということを何度も書いていて思想的にもまっとうだし,例題を具体的に操作する方法を中心に書かれていてわかりやすい。とくに4章8節の並べかえ検定と5章5節にも出てくるbootstrap(もっとも,三中さんの「Rでブーツ」の方がわかりやすいし詳しいが)と,8章のロジスティック回帰を含む一般化線型モデルのところと,9章のマルチレベル分析のところは,他の本にあまり載っていない点について詳しくて役に立つ。10章の決定木でSPAMメールを検出する話も面白い。Amazonで買ったら,ハードカバーで7000円くらいだった。詳しい目次と,A Chapter by Chapter Summaryの勝手な私訳(下記……にしていたが,長くなりすぎたので独立したページにした)を挙げておく。
- データの再コーディング法の修正(2004年2月18日; 3月14日追加)
- ●データの再コーディングの記載に誤りがあったので修正し,群馬大学の青木先生から頂いたコードを掲載した。
- ●水準を変えずに名前を変えるだけならもっと簡単な方法があったことを忘れていたので追記した。
- 青木先生の「Rを味見してみる(インターネットでR!!)」(2004年2月23日; 2月25日中止)
- ●群馬大学の青木先生が,「Rを味見してみる(インターネットでR!!) 」というページを開設された。Rwebなどと同じく,webページからRのプログラムを実行できる環境のようだ。
- ●2月25日にメールでお知らせいただいたのだが,諸般の事由により中止されたとのこと。残念だが仕方がない。
- Windowsでproxy越しにパッケージをインストールする方法(2004年2月23日)
- ●メールで相談があったので調べてみたのだが,Windows版のRでは,デフォルトではproxy越しにはinstall.packagesでのパッケージインストールが通らないのだった。解決策はCRANのFAQのWindows編のページに載っていた。次のいずれかの方法でいいらしい。
- Rを起動するアイコンの上で右クリックすると現れるメニューからプロパティを選んで,起動コマンドが"C:\Program Files\R\rw1081\Rgui.exe"などと設定されているところに,--internet2とつけておく。
- 認証が必要なプロキシの場合は,プロキシサーバがgannetで認証IDがuser,パスワードがpassだとすると,やはりR起動コマンドの後に,http_proxy=http://user:pass@gannet/またはhttp_proxy=http://gannet/ http_proxy_user=askを追加する。後者の場合は認証を求めるウィンドウが現れるらしい。
- John Foxの最新講義(2004年2月27日)
- ●John Fox's Home Pageを自動更新チェックしているので気づいたのだが,今日からSTATISTICAL COMPUTING IN S: An Introduction to R and S-PLUSという新しい講義が始まるらしい。講義資料を見るだけでも参考になりそうだ。ちなみにRcmdrも2月15日付けで0.9-4にバージョンアップされていた。
- 続・わしの頁(2004年3月1日)
- ●たぶん舟尾さんのサイトだと思うが,続・わしの頁を発見した。
- Windows環境でのパッケージ管理のヒント(2004年3月2日)
- ●Windows環境でのパッケージ管理のヒントをまとめてみた。
- 「データサイエンス入門」(2004年3月3日;9日追記;25日追記;4月7日追記)
- ●間瀬先生の「データサイエンス入門」が今月末に刊行予定とのニュース。早く読みたいなあ。
- 書誌情報は,間瀬 茂・神保 雅一・鎌倉 稔成・金藤 浩司『工学のための数学3 工学のための データサイエンス入門 ― フリーな統計環境Rを用いたデータ解析 ― 』(数理工学社発行),A5判 264頁 本体2300円 2004年3月29日発売予定,ISBN4-901683-12-8。簡単な目次がサイエンス社の近刊案内にある。
- ※(25日追記)上記「簡単な目次」は無くなって,代わりに詳細な目次と内容紹介が公開されている。
- ※※(4月7日追記)間瀬先生のページに,正誤表が公開された。
- 「Rでシミュレーション」を更新(2004年3月3日)
- ●著者16人で作っているRの新しい本に「Rでシミュレーション」(この内容を膨らませたもの)の章を担当することで参加させて貰っているのだが,原稿を書いている途中で試したけれど結局使わなかった3次元プロットが惜しいので,ページを更新した。ちなみに,この本は,インストールや使い方の本当の基本の基本から,GISとか画像処理とかマルチレベル分析とか時系列解析とか実践的な応用例まで,実に幅広くカバーした本で,こんなに充実した本を出版前に読めるのは著者に入れてもらっている特権だと思う。
- ●なお,3次元の散布図をプロットするには,library(lattice)のcloud()関数を使う手もあるし,baseライブラリに入っているpersp()関数を応用することもできるが,library(scatterplot3d)が一番楽だし便利だと思う。
- R関連の本の出版ニュース2つ(2004年3月9日)
- ●慶應の渡辺利夫先生によるフレッシュマンから大学院生までのデータ解析・R言語。ナカニシヤ出版から5月頃発売予定とのこと。心理学で使用する多変量解析が主題。
- ●三中さんの日録から知った,東京大学生物統計学研究室編「実践生物統計学:分子から生態まで」(リンク先はamazon.jp)(朝倉書店)。こちらは3月1日に既刊。こういう本を書くのにRは本当に向いていると思う。中西・益永・松田「演習 環境リスクを計算する」もExcelではなく,Rでできるように書かれていればなお良かったのに,と残念でならない。
- 「The R Book --データ解析環境Rの活用事例集--」出版案内(2004年3月18日)
- ●手前味噌で恐縮だが,「Rでシミュレーション」を含む新しい本のタイトルが決まったのでお知らせする。今はclosedなWikiとMLで連絡をとりながら仕上げ作業を進めている段階なのだが,だいたいの目次を含む概要説明には4-5月が出版目標となっている。個人的に一番のお薦めは高階さんの画像処理の章で,かつてNIH Imageとか使って顕微画像計測をやっていたような微生物系の研究者が読んだら,たぶん目からウロコが何枚も落ちて,Rを使いたくなるに違いないだろう。もう1つの目玉はGIS関係の応用事例がたくさん載っていることで,これも無料でこんなにできるというのは,高い金を払ってGISやリモセンをやってきた人には驚異なのではないか。メーカーには驚異というより脅威かも。
- 「データサイエンス入門」正誤表公開(2004年4月7日)
- ●先月紹介した間瀬 茂・神保 雅一・鎌倉 稔成・金藤 浩司『工学のための数学3 工学のための データサイエンス入門 ― フリーな統計環境Rを用いたデータ解析 ― 』(数理工学社発行)は,ぼくも一冊ご恵贈いただいたのだが(ありがとうございます>間瀬先生),青木先生のお名前が間違っているなど,いくつか誤植があることには気づいていた。すると,さすが間瀬先生,すかさず正誤表を公開された。この辺りもオンラインコミュニティが活発なソフトを使う利点だと思う。
- R-1.9.0リリース(2004年4月13日; 15日, 16日, 26日;6月10日追記)
- ●Peter Dalgaardによって,R-Announceに1.9.0のリリースがアナウンスされた。ほぼ半年振りのメジャーバージョンアップである。多くのバグフィックスのほかにも,かなり大きな変更があって,その主なポイントは,基本ライブラリの構成変更,gridグラフィックスの大幅な変更,"_"(アンダースコア)を変数名に使えるようにしたこと,の3点だということだ。でも,なかまさんによる日本語対応版がGW中にはできると思われるので,それを楽しみにして待っておこう。13日11:00現在,まだCRANにはソースしかないが,FreeBSD 4.8Rのコマンドライン環境に限って言えば,ダウンロードしてtar xvzf R-1.9.0.tgzで展開後,cd R-1.9.0して,./configure; makeでコンパイルでき,suしてからmake installでインストールでき,普通に使えた。
- ●(15日追記)14日の竹内君の日記で指摘されているように,1.9.0のbarplot()はおかしい。example(barplot)の結果からすると,仕様変更というよりもバグだと思う。開発グループに知らせた方がいいと思うので,発見者の竹内君に,R-helpにでも投稿してみては,と薦めておいた。ちなみに,1.8.1以前のバージョンで,
barplot(table(c(1,1,1,1,1,1,2,2,3,4)))
でできたのと同じ動作をさせるには,barplot(matrix(x<-table(c(1,1,1,1,1,1,2,2,3,4)),nc=length(x)),names.arg=names(x))
とすればよい。 - ●(16日追記)上記バグだが,既にR-helpに投稿されたようだ([R] tapply() and barplot() help files for 1.8.1から始まるスレッド)。投稿者は竹内君ではなかったが。
- ●(26日追記)25日付けで,なかまさんが1.9.0用日本語対応化パッチ(適用済みバイナリも)を発表された。いつもながら素早すぎる。R-helpを流れる膨大な量のメールに目を通していると,なんとなく1.9.0に全面移行するのはもう少し待った方がいいような気はするが。
- ●(6月10日追記)R-helpに1.9.1alphaで直ったという話が流れたので,なかまさんのRworkから1.9.1alphaの6月7日パッチをダウンロードして試してみたら,確かに直っていた。1.8.1と同じ動作が復活したらしい。
- 分布のパラメータ推定(2004年4月27日)
- ●西浦さんがワイブル分布のパラメータ推定でお困りのようなので,Rで参考になりそうなコード(paramest.R)を書いてメールで送ってみた。非線形回帰か関数の最適化でいけるはずと思ってやってみたが(だから,コードといっても,要は分布関数にfitさせるだけなんだが),optim()ではどうもうまく推定できなかった。非線形回帰では,初期値をある程度適当にとれば,それなりにいい結果が得られるようであった。これで十分な精度かどうかは不明だが,悪くはないと思う。なお,なんらかの確率密度関数に従うと思われるデータxの近似曲線をプロットするだけなら,plot(density(x))とすればいい。
- ●後になって気づいたが,青木先生謹製の関数も公開されていた。
- ホッケースティック回帰(2004年5月7日)
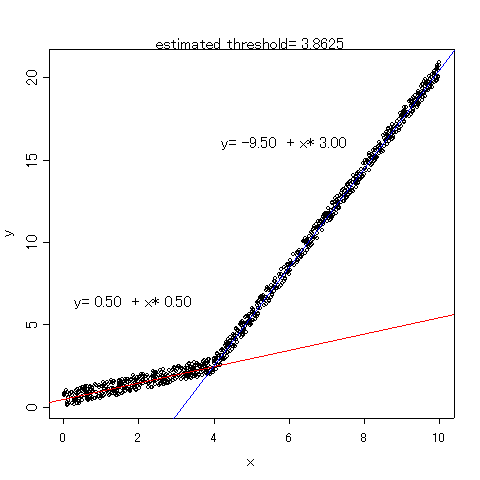 ●ホッケースティック回帰(hockey-stick regression)とは,何かの閾値(threshold)があって,それ以上とそれ以下では回帰の傾きが異なるような場合に,2本の回帰直線(線分)をfitさせる手法である。閾値が明確ならそれ以上とそれ以下で別々に回帰式を推定すればいいが,不明確な場合は,それを未知数として関数の最小化をすることでパラメータ推定する。Yanagimoto and Yamamoto (1979) Env. Health Perspect., 32: 193-199.が良く引用されているようである。Rでの実装は,ちょっと探したところでは見つからなかったので,optim()を使って簡単なコードを書いてみた。
●ホッケースティック回帰(hockey-stick regression)とは,何かの閾値(threshold)があって,それ以上とそれ以下では回帰の傾きが異なるような場合に,2本の回帰直線(線分)をfitさせる手法である。閾値が明確ならそれ以上とそれ以下で別々に回帰式を推定すればいいが,不明確な場合は,それを未知数として関数の最小化をすることでパラメータ推定する。Yanagimoto and Yamamoto (1979) Env. Health Perspect., 32: 193-199.が良く引用されているようである。Rでの実装は,ちょっと探したところでは見つからなかったので,optim()を使って簡単なコードを書いてみた。- ●上でリンクしているコードの実行結果を使ってグラフを描いてみると,右図のようになる(まずplot(y~x)してから,abline()を2回使って回帰直線を重ね書きし,mtext()とtext()を使ってパラメータ推定値を重ね書きすればいい。text()の表示位置が試行錯誤で決め打ちしたものなので汎用性がなくコードは示さないが,ご希望があればお知らせいただきたい)。このように下に凸な場合はthresholdの推定値が低めになり,逆に上に凸な場合は推定値が高めになりそうなことは,回帰の残差の算出法からいって予想できるが,要するに,閾値付近ではどちらの直線に乗るか判別不能なことを意味し,その辺りがこの方法の限界であろう。
- ●なお,やっぱりなあ,というか,青木先生謹製の関数が公開されていることに,後になって気づいた。
- 作図つき一元配置分散分析と多重比較(2004年5月21日;2007年11月5日修正)
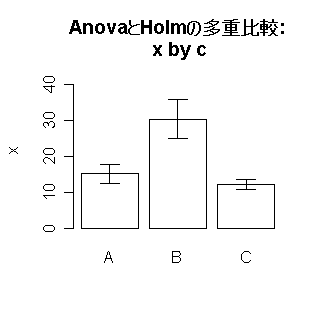 ●エラーバー付きの棒グラフを描きたいという相談があったので,とりあえずExcelでのやり方を説明したのだが,簡単なまとめ関数を書いてみた。場合としては,多群の平均値の比較をしたいはずだから,一元配置分散分析と多重比較の結果もついでに出すようにした。関数定義を公開しておく(2007年11月に久々に使ってみたら,2度目の実行でRがクラッシュするのでdeparse後のpasteを止め,結果を.Xのnamesに入れるのを止めて文字列型の変数に保存するように修正した。さらに,棒グラフの間を詰めるspace=0を消した)。
●エラーバー付きの棒グラフを描きたいという相談があったので,とりあえずExcelでのやり方を説明したのだが,簡単なまとめ関数を書いてみた。場合としては,多群の平均値の比較をしたいはずだから,一元配置分散分析と多重比較の結果もついでに出すようにした。関数定義を公開しておく(2007年11月に久々に使ってみたら,2度目の実行でRがクラッシュするのでdeparse後のpasteを止め,結果を.Xのnamesに入れるのを止めて文字列型の変数に保存するように修正した。さらに,棒グラフの間を詰めるspace=0を消した)。- ●例えば,
source("http://phi.med.gunma-u.ac.jp/swtips/autoaov.R") RNGkind("Mersenne-Twister") set.seed(1) png("autoaov.png",width=320,height=320) x <- c(runif(100,10,20),runif(100,20,40),runif(100,10,15)) c <- c(rep("A",100),rep("B",100),rep("C",100)) sink("autoaov.txt") auto.aov(x,c) sink() dev.off()のように使えばいい。すると,カレントディレクトリにpngファイルとして右のグラフが得られ,検定結果はカレントディレクトリにテキストファイルとして得られる。関数としての完成度はあまり高くないので,たぶんgregmiscライブラリのbarplot2に含まれている機能を使う方が賢いと思うが,目的が特化している分,こちらの関数の方が使い方は簡単だと思う。 - ●結果のテキストファイルの中身は次の通り。
AnovaとHolmの多重比較: x by c Df Sum Sq Mean Sq F value Pr(>F) .C 2 18982.9 9491.4 736.6 < 2.2e-16 *** Residuals 297 3827.0 12.9 --- Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 Pairwise comparisons using t tests with pooled SD data: .X and .C A B B <2e-16 - C 9e-09 <2e-16 P value adjustment method: holm A : N= 100 平均値= 15.17847 不偏標準偏差= 2.675848 B : N= 100 平均値= 30.34944 不偏標準偏差= 5.436329 C : N= 100 平均値= 12.17508 不偏標準偏差= 1.393722 - ●ちょうどR-helpで似たような質問が流れたので,生データから計算するのではなく,各群の平均値と不偏標準偏差が既にある場合の関数定義を作って返事を書いたのだが,直メールになってしまったのでここに置いておく(barwithdev.R)。
- ●その後,R-helpに流れたメールによって,barplotの返り値を使えば,棒の間隔をゼロにして位置計算するなんて無駄なことをしなくてもいいことがわかった(つまり,barwithdev2.Rでいい)。また,エラーバー端の横棒が不要ならarrows()関数の代わりにsegments()関数を使えばいいとわかった。
- barplot復活(2004年6月10日)
- ●1.9.0のところに追記したが,1.9.1alphaでbarplotの妙な挙動が直った。ただし,alpha版を常用するのはちょっと怖いので,もう少し待ちたい。
- R-1.9.1リリース(2004年6月21日~23日;7月1日追記)
- ●例によってPeter Dalgaardが1.9.1の正式リリースをR-announceで告知した。23日現在,Windows版バイナリも筑波大ミラーから既にダウンロード可能になっている。素晴らしい。なかまさんの日本語対応版は今度の週末に作業してくださるらしい。
- ●(7月1日追記)6月25日付けで日本語対応版も使えるようになっている。このバージョンではpdf出力でも日本語が使える。ついでに,教室セミナー資料(PDF形式,933 KB)としてR-1.9.1日本語対応版とR Commander 0.9-9をインストールして初歩的な解析を行う手順の図解を作ったので公開しておく。
- R-2.0.0リリース(2004年10月6日)
- ●4日付けで,R-2.0.0の正式リリースが告知された(CRANの筑波大ミラー|Windows版バイナリ)。で,既になかまさんが,Vine-3.0とWin32用の日本語対応版バイナリを公開されている。すばらしいという他はない。
- ●今回のバージョンアップは,これが目玉だというものがあるわけではなく,細々とした仕様の変更(barplot()のデフォルトの色とか)や,新機能(file.edit()とか)や,バグフィックスがたくさんあるようである。
- maptoolsで塗り分け地図(2004年11月3日)
- ●このページではアナウンスしなかったが,先月,Epi Infoによる塗り分け地図の作り方というページを公開し,その末尾で,maptoolsパッケージを使って塗り分け地図を作る方法を書いておいた。
- ●Rmapだとポリゴンの重心を得るにも関数を書かなくてはいけないが,maptoolsにはget.Pcent()という関数が用意されているので便利だ。
- 幹葉表示をグラフィック画面に出す(2004年11月3日;11月10日追記)
- ●最近,医学情報処理演習でRの演習をしているのだが,そのときに知った小ネタというか,ちょっとしたテクニックを,ここにもメモしておくことにする。
 ●最初は幹葉表示をグラフィック画面に出す方法から。要は,テキスト出力をキャプチャする関数さえあればいいと思って探してみると,capture.output()という関数が見つかった。後は空白のグラフィック画面を開いておいて,text()関数で適当な位置に書き出せばOKである。gstem()関数の定義は以下の通り(ファイルとしてはgstem.R)。これを,例えば,gstem(rnorm(100,20,2))のように用いる。
●最初は幹葉表示をグラフィック画面に出す方法から。要は,テキスト出力をキャプチャする関数さえあればいいと思って探してみると,capture.output()という関数が見つかった。後は空白のグラフィック画面を開いておいて,text()関数で適当な位置に書き出せばOKである。gstem()関数の定義は以下の通り(ファイルとしてはgstem.R)。これを,例えば,gstem(rnorm(100,20,2))のように用いる。gstem <- function (X,D=1) { .stem.out <- capture.output(stem(X,D)) .stem.len <- length(.stem.out) plot(c(1,2),c(1,.stem.len),type="n",axes=F,xlab="",ylab="") text(rep(1,.stem.len),.stem.len:1,.stem.out,pos=4) }- ●(追記)下のように実行すると,右のような画像出力が得られる(ここでは,png("gstem.png",320,480); gstem(X,2); dev.off()によって生成したが,サイズはもちろん可変である)。
RNGkind("Mersenne-Twister",normal.kind="Inversion") set.seed(123) X <- round(rnorm(200,170,5),1) source("http://phi.med.gunma-u.ac.jp/swtips/gstem.R") gstem(X,2) - 最頻値だけを表示する(2004年11月9日;24日追記)
- ●同数の値がある可能性を考えればあまりいい方法ではないけれども,次のようにすると変数Xの最頻値だけを表示することができる。
names(sort(table(X),dec=T))[1]
- ○(追記)R-helpに流れた情報によれば,
which.max(table(X))
というやり方もあるようだ。 - Gearyの検定(2004年11月9日;2007年10月5日追記)
- ●正規性の検定のうち,Shapiro-Wilkの検定は標準でshapiro.test()として提供されているけれども,Gearyの検定が提供されていないので考えてみた。データから計算したG統計量とともに,その分布の5%点としてg5,1%点としてg1を表示するので,G統計量がg5よりも小さければ正規分布よりも5%水準で有意に裾が長いとして帰無仮説「Xは正規分布からの標本」を棄却すればよい(注:gの近似式の出典は,柴田義貞「正規分布 特性と応用」東京大学出版会,1981年,pp.236である)。なお,Gearyの検定では,分布は左右対称であることを想定している。関数定義は以下の通り(ファイルとしてはgeary.R)。
geary.test <- function(X) { m.X <- mean(X) l.X <- length(X) G <- sum(abs(X-m.X))/sqrt(l.X*sum((X-m.X)^2)) g5 <- sqrt(2/pi)+qnorm(0.05)*sqrt(1-3/pi)/sqrt(l.X) g1 <- sqrt(2/pi)+qnorm(0.01)*sqrt(1-3/pi)/sqrt(l.X) cat("G=",G," / g(0.05)=",g5," / g(0.01)=",g1,"\n") } - ●(追記)自然な式変形からすると,たぶん以下のようにすれば有意確率が表示できるはず。
geary.test <- function(X) { m.X <- mean(X) l.X <- length(X) G <- sum(abs(X-m.X))/sqrt(l.X*sum((X-m.X)^2)) p <- pnorm((G-sqrt(2/pi))/sqrt(1-3/pi)*sqrt(l.X)) cat("Geary's test for normality: G=",G," / p=",p,"\n") }この関数定義の後で,geary.test(rt(1000,10))
などとすれば,自由度10のt分布に従う乱数1000個の分布は,多くの場合に正規分布よりも有意に裾が長いことがわかるだろう。 - ●(さらに追記; 2007.10.5)後で間違っていたことがわかったが,ここの記述を放置していたので訂正する。
geary.test <- function(X) { m.X <- mean(X) l.X <- length(X) G <- sum(abs(X-m.X))/sqrt(l.X*sum((X-m.X)^2)) p <- (1-pnorm((G-sqrt(2/pi))/sqrt(1-3/pi)*sqrt(l.X)))*2 cat("Geary's test for normality: G=",G," / p=",p,"\n") } - R-2.0.1リリース(2004年11月16日;19日追記)
- ●R-2.0.0のリリースからほぼ1ヶ月でR-2.0.1がリリースされた(CRANの筑波大ミラー|Windows版バイナリ(予定))。日本語対応版も,近々なかまさんのサイトでリリースされるだろう(11月16日11:43現在,既にVine3.0用のrpmは公開されている!)。
- ●今回のアップデート内容は,主にバグフィックスだそうだ。新機能は,library()のプラットフォーム等価性をテストする関数testPlatformEquivalence()ができたことと,split()関数への付値が再帰処理を許すようになったことで,新しいドキュメントとして,「Rの拡張を書く」に,移植可能なパッケージの作り方と,Rの新しいフロントエンドの書き方についての節が追加されたことである。フロントエンドの書き方については,R-2.1.0で新しいヘッダファイルが提供される予定とのこと。また,MacOS X用のaquaモジュールは廃止され,bzip2,GNOME,libz,PCREを扱う機能は廃止され,UNIX系プラットフォームでのGNOME GUIはRの一部としては廃止され(R-2.1.0で別の形で復活する予定),UseMethod()を引数無しで使うやり方(マニュアルには記載されていない)も廃止された。
- ●ちなみに,バグフィックスの中では,na.action=na.excludeでlm()を使うとlogLik()とAIC()が返す値がおかしかったのが直ったことと,Windows版でjpeg(),png(),bmp()が背景色を正しく処理できなかったのが直ったこと,(D)COMが無限ループに入ることがあるのが直ったこと,Tcl/Tkウィンドウでの制御キーが正しく処理されなかったのが直ったことなど,重要なポイントが多いので,少なくともWindows版ユーザは2.0.0でなく2.0.1を使うべきだろう。金沢に向かって拝まねば。
- ●16日の夜には日本語対応版win32版バイナリも公開されていた。なかまさんは偉大すぎる。
- ○(19日追記)個人的にはあまり使わないのだが,2.0.0から実装された(と思う)スクリプトエディタは,手に馴染んだエディタがとくにないという方には便利かもしれない。メニューバーのFileからNew scriptを選ぶと(注:実はR Consoleでedit()と打つのと同じであり,edit("スクリプトファイル名")とすれば先にファイル名をつけられるので,慣れればこちらの方がよいだろう),普通のエディタのような画面が開くので,そこにRのスクリプトを打ち込み,実行したい範囲を選んでCTRL+Rを押せば,選んだ範囲が実行される。
- 「Rによる統計解析の基礎」正誤表への追加(2004年11月17日;19日追記)
- ●var.test()のデフォルト動作についての説明がおかしかったので,「Rによる統計解析の基礎」の正誤表に(13)を追加。申し訳ありません。
- ○(19日追記)近々第3刷になるという連絡があったので,この点の修正を依頼したら,受け付けていただけたようだ。
- 多重共線性(Multicollinearity)について(2004年11月18日)
- ●某先輩から質問があったので調べてみた。結局その質問には答えられなかったのだが,Rでの扱い方の情報をメモしておく。もちろん,説明変数間に強い関連がある場合に重回帰分析の結果が不安定になってしまうという例のアレのことだ。
- ●Armitage et al. "Statistical Methods in Medical Research. 4th ed."によると,ある説明変数をそれ以外の説明変数の従属変数として重回帰分析したときの重相関係数の2乗を1から引いた値の逆数をVIF(Variance Inflation Factor; 分散増加因子とでも訳したらいいか?)として,VIFが10を超えたら多重共線性を考えねばならないという基準と,centringという調整方法と,DBPとSBPみたいに本質的に相関するものだったら片方だけを説明変数に使うという対処法が載っていて,この本では追及しないがリッジ回帰するといいと書かれていた。
- ●Maindonald and Braun "Data analysis and graphics using R"によると,Rでは,DAAGライブラリにvif()という関数があってVIFを計算でき,MASSライブラリのlm.ridge()関数でリッジ回帰ができる。リッジ回帰をするためには分析者がチューニングパラメータlambdaを選ばねばならないのだけれども,試行錯誤して最適なところを探すとよいとのこと。
- Rのbaseとstatsの関数マニュアル邦訳版(2004年11月24日)
- ●RjpWikiの「なんでも掲示板」の書き込みによると,間瀬先生が,baseパッケージとstatsパッケージに含まれているほぼすべての統計解析関連の関数のヘルプドキュメントの日本語訳を,近日公開されるとのこと(たぶんここを定期的にチェックしておけばいいだろう)。これは多くの日本人Rユーザにとって役に立つのではないだろうか。
- ●当該書き込みによると出版はうまくいかなかったらしいが,公開後でも出してくれる出版社はあるんじゃないだろうか。ぼくの「Rによる統計解析の基礎」もいまだに公開を続けながら(ただし公開版pdfファイル[919 kb]は内容を修正とか更新していないのだが)ピアソン・エデュケーションが出版してくれたし。
- オブジェクトのクリア(2005年1月19日)
- ●R-helpで流れていた話から。シミュレーションとかデータの加工で中間的なオブジェクトが大量に発生してメモリを圧迫するとき,明示的にオブジェクトをクリアするには,rm(オブジェクト名)とすればいいけれども,それだけではメモリ上にゴミが溜まるので,続けてgc()でガーベージコレクションをするとよい。オブジェクト名がたくさんあって一々指定するのが面倒で,全部消してしまいたければ,rm(list=ls())とすれば全部消える。
- ウィンドウズ版でクリップボード経由でデータを読み込む(2005年1月19日)
- ●Windows環境に限るが,例えばExcelでデータ入力をしたけれども,ファイルが使いにくい環境で,いったんテキストファイルに書き出して読み込むという手段を使いたくない場合,"clipboard"デバイスを使うと便利である。
- ●Excel上でデータの範囲を選択してコピーし,Rのオブジェクトに読み込むとき,コンソールでペーストするとタブコードが消えてしまうのだが,scan("clipboard")なら大丈夫である。ただし,what=オプションをつけてちゃんと指定しないと数値しか読めないので,カテゴリ変数を読ませたいときは,read.delim("clipboard")などとすればいい。
- ●例えば,以下の表
をブラウザ上で範囲選択してコピー(Ctrl+C)してから,Rのコンソールでgr val X 23 X 25 X 16 Y 30 Y 21 Y 27 dat <- read.delim("clipboard")と打てばデータ入力ができる。 - ●もっとも,R-2.0.1ならば,New Scriptを開いて,直接
gr <- c(rep('X',3),rep('Y',3)) val <- c(23,25,16,30,21,27) dat <- data.frame(gr=gr,val=val)としてからRun allさせてもいい。いや,これくらいのサイズなら,コンソールで直接打っても問題ないだろう。それ以前に,ファイルが使えない環境というのは,きわめて限定的な状況でしか生じないと思うが。 - AICについて(2005年1月23日)
- ●医学統計演習の第12回の講義資料を作っていて,今更ながらAICとextractAICが違う結果を返すことに気づいた。AICはかなり以前から標準実装されていて,extractAICは元々MASSライブラリにあったのが1.9.0辺りからS4メソッドとして取り込まれたものらしい。これまでAICの方しか使っていないので気づかなかった(定義どおりのAICを計算してくれるのはこちらである)。問題は,変数選択を自動的にやってくれるstep関数が,extractAICの方を使うことである(たぶん計算量が少なくて済むためだと思われる)。
- ●webで検索してみたら,東工大の下平英寿さんの講義「Rによる多変量解析入門」の第8回「モデル選択」の資料に,それぞれが使っている式の説明があった。
- ●要は,AIC関数は-2ln L + 2θ(Lは最大尤度,θはパラメータベクトルの次元)を計算する汎用関数であって,オブザーベーション数n,パラメータ数p,標準偏差σとして,線型重回帰の場合はn(1+ln(2πσ2))+2(p+1)を計算し(正規分布を仮定するから),extractAIC関数は線型重回帰のときだけ使える関数で,n ln(σ2)+2pを計算するため,AIC-n(1+ln(2π))-2に一致するということである。
- 『The R Tips -データ解析環境 R の基本技・グラフィックス活用集-』刊行(2005年2月10日)
- ●以前からwebで公開されていたR Tips(html版,pdf版: いずれも中央農業研究センターの竹澤邦夫さんのサイト内)をベースにして大幅に加筆訂正して作成された,誰もが待ち望んでいた本がついに刊行される。九天社,2005年
2月10日3月1日刊(注:ご恵贈いただいた本の奥付により訂正した),3675円とのこと。サポートページも既に準備されている。すばらしい。 - ●ありがたいことに,舟尾さんから,この本をご恵贈くださるというメールをいただいた。家と研究室と1冊ずつ置いておきたいので(ちょっと日常的に持ち運ぶには重そうだし),予定通り1冊は買うつもりだけれども,嬉しい。
- 欠損値のあるデータについての順位相関処理(2005年2月10日)
- ●RjpWikiのQ&Aへの青木先生の質問からわかったことだが,NAが含まれているデータについてRのcor関数でmethod="spearman"オプションをつけてスピアマンの順位相関を求めようとすると,useオプションをつけないと計算できないのだが,use="complete"とかuse="pair"とかすると,ペア単位の除去をする前に順位付けをしてしまうので,意図したものとは別の結果になってしまう。
- ●ぼくは,どうも関数内でのオプション指定による欠損値処理というものを信用できず(いや,本音をいうとオプションを覚えるのが面倒だったからというのもあるが),以前から,まず欠損値のないデータにしてから関数に渡すということをしていたので,とりあえず問題はない。つまり,青木先生の出されている例でいうと,
としておけば,とりあえず正しい結果が得られる。このやり方ならば,どういう関数に渡す場合でも大丈夫だと思う。x <- c(7, 9, 8, 0, NA, NA) y <- c(2, 3, 4, NA, 4, 3) non.na <- !is.na(x)&!is.na(y) xx <- x[non.na] yy <- y[non.na] cor(xx, yy, method="spearman")
- ●この件は,2月13日に青木先生(ですよね?)が[Rd]メーリングリストにレポートされたので,きっと何らかの対応が取られることと思う……と,すぐにPeter Dalgaardから返事が出て,わかっていてhelpに記載もされていることだが,ペア単位の除去を考えるとコードを書き直すのが大変だから対応していない仕様なのだ,もしコードを書いて貢献してくれるなら歓迎する,ということであった。実用上はペア単位の除去よりも,リスト単位の除去をちゃんとやってくれるように,順位付けと除去の順番を入れ換えるだけでいいと思うのだが,それだと不都合があるのだろうか?
- ●青木先生が新しいコードを書いて投稿してくださったので,次期バージョンから(?)それが採用されるようだ。素晴らしい。
- 続・maptoolsで塗り分け地図(2005年2月24日)
- ●EpiInfoによる塗り分け地図の作り方末尾に,maptoolsパッケージを使って,日本地図データから群馬県データだけを切り出して塗り分け地図を作る方法を追記した。RjpWikiに貴重な情報を投稿されたokinawaさんに感謝。
- R-2.1.0リリース(2005年4月19日;20日追記;21日追記)
- ●R-2.0.1のリリースからほぼ5ヶ月ぶりにR-2.1.0がリリースされた(CRANの筑波大ミラー|Windows版バイナリ)。
- ●今回の最大の目玉は国際化対応である。インストール時にチェックボックスがずらずらっと並ぶ画面で,"Version for East Asian Languages"の左側のチェックボックスにチェックが入った状態(日本語OS上ならたぶんデフォルトでそうなる?)でインストールを続けると,Rconsoleのメニューやメッセージが日本語になる(下のスナップショット参照)。なかまさん,舟尾さん,間瀬先生,青木先生,岡田さんら,RjpWiki有志の尽力のおかげである(ぼくも,ほんの少し,20個くらいのメッセージの翻訳をしたけれども,たぶん全体の0.1%にも満たないので恥ずかしい)。
- ●しかし,大きな変化だっただけに不具合もいろいろ出ていて,メモの方に書いたように日本語Windows XPでデフォルトフォントのままだとカーソルが若干ずれるとか,非英語環境では多くの場合,example()でエラーが出るとか(R-helpメーリングリストに,Prof. B. Ripleyから,コアチームは全員英語環境で使っているので,βテスト期間中に非英語環境のユーザによるテストが本当に必要だというメッセージとともに,R-patched版を使えばこのエラーはfixされているらしいことも書かれていた……21日に見たら,中間さんのサイトでWindows版patchedバイナリが公開されていて,example()のエラーはfixされていた),FreeBSD 4.*でBuildできないとか(RjpWikiで中間さんからご教示いただいたところによると,5.*でないとFreeBSDはC99な国際化関数の多くに非対応なのが原因だったらしい。./configureにFreeBSDのバージョンチェックを入れて,4.*だったら国際化関数を使わないでmakeするという形にできればいいと思うが,やり方がわからない……と書いていたら,中間さんに教えていただいた。./configure --disable-mbcsとしてからmakeすればBuildはできる。もっとも,Rを起動すると文字化けするが。日本語メッセージを扱わない設定でRを使うには,setenv LANG Cとしてから起動すれば英語版として使えるので,まあそれで問題ないか)。
- ●パッケージのアップデートは,日本国内のユーザは,update.packages(repos="http://cran.md.tsukuba.ac.jp/",ask=F,checkBuilt=T,destdir=".")とするといい。reposの指定が大事。destdir="."は,zipファイルのダウンロード先をカレントディレクトリにする指定なので,必ずしもなくてもいいが。
- R-2.1.1リリース(2005年6月22日)
- ●ソースは予定通り6月20日リリースだったが,Windowsバイナリも漸くCRANの筑波大ミラーからダウンロードできるようになった。
- ●上述の通り,R-2.1.0はbuggyだったので,可能な限り早くアップデートした方がいいと思う。
- ●日本語環境で文字化けが出る場合,RconsoleとRdevgaを書き換えれば直る(詳細はRjpWiki内のこのページを参照)。
- R-tips改定新版公開(2005年8月1日)
- ●舟尾暢男さんのR-tipsのpdf版が改訂され,第4版が公開された。スクリーンショットや説明が国際化後のRに対応している。いつもながらその凄い労力には頭が下がる。ダウンロード先。
- R-2.2.0リリース(2005年10月7日)
- ●昨夜,Peter DalgaardからR-announceに流れたメールにより,R-2.2.0のソースコードがリリースされた。Windows版バイナリも,既にCRANの筑波大ミラーにあって驚いた。これまでバイナリインストーラパッケージは,例えばrw2110.exeのような名前だったのが,このバージョンからR-2.2.0-win32.exeという名前になった。
- ●barplot()やplot(lm())の機能追加とか,cdplot()やspineplot()の追加など,作図関数関係の機能拡充が多いように思う。
- ●RjpWikiに紹介された闇パッチは凄いかもしれない。なかまさんのサーバの中を探すとある。これ,2.3.0でマージされるといいなあ。
- R-2.2.1リリース(2005年12月21日)
- ●昨夜,例によってPeter DalgaardがR-2.2.1のソースコードのリリースを宣言した。バグフィックスが主体のマイナーアップデートらしいので,日本のミラーに入ってからダウンロードした方がいいと思う。ぼくは中間さんの闇ビルドが出てからにしよう(……いえ,別にリクエストではありませんので,気にしないでください>中間さん)。先日のユーザ会の後の懇親会で聞いた話だとBrian Ripleyが2.3.0からは中間さんのパッチを正式に取り入れてくれるらしいので,ともかくR-2.3.0への期待が高まるのである。
- 舟尾暢男,高浪洋平『データ解析環境「R」』工学社(2005年12月21日)
- ●出版されることは先日のユーザ会で知っていたが,本日ご恵贈いただいた。ありがたいことだ。内容は少しだけ今日のメモに紹介したが,初心者向けに考え抜かれた入門書だと思う。
- R-2.3.0リリース(2006年5月10日)
- ●忙しくて書き忘れていたが,4月24日にR-2.3.0がリリースされた。予定通り,中間さんの国際化コードが取り込まれたものになったし,他にも変更点が多々あるので,暫くバージョンアップは待とうと思っていた。けれども,さっきインストールしてみたら,Windows版で作業ディレクトリを起動アイコンで指定する使い方をする限り,普通にインストールするだけで何ら支障がなかった(そこに設定ファイルが残っているので)。ただし,今回,PostScript出力でfont-familyを指定できるところが新しいポイントの1つであるはずだが,それはまだ試していない。
- 2.3.1リリース前情報(2006年5月17日)
- ●R-announceにPeter Dalgaardが流した情報によると,2.3.1は6月1日リリース予定とのこと。
- 中央値や四分位偏差は「小さい規模の集団」で信頼性が高いか?(2006年5月19日)
- ●上記の見慣れない記述が文部科学省の資料の用語解説にあったので検証してみた。ここで,小さい規模の集団と称しているのが母集団のことかサンプルのことか不明確なのだが,全国に敷衍するとかいう議論だから,サンプルサイズが小さい場合と判定した。
RNGkind("Mersenne-Twister") set.seed(1) # 平均70,標準偏差7点の正規分布に従う得点についての1000人の架空の母集団データを生成 pp <- as.integer(rnorm(1000,70,7)) x <- 1:500 dim(x) <- c(5,100) for (i in 1:100) { x[,i] <- sample(pp,5) } # xはppからの5人のサンプルを100回取ったもの xmean <- 1:100 xmedian <- 1:100 for (i in 1:100) { xmean[i] <- mean(x[,i]); xmedian[i] <- median(x[,i]) } xsd <- 1:100 xsiqr <- 1:100 for (i in 1:100) { xsd[i] <- sd(x[,i]); xsiqr[i] <- (fivenum(x[,i])[4]-fivenum(x[,i])[2])/2 } png("./mmss_sim.png",width=640,height=480) par(mfrow=c(2,2)) hist(xmean,main="平均値の分布") hist(xmedian,main="中央値の分布") hist(xsd,main="標準偏差の分布") hist(xsiqr,main="四分位偏差の分布") dev.off()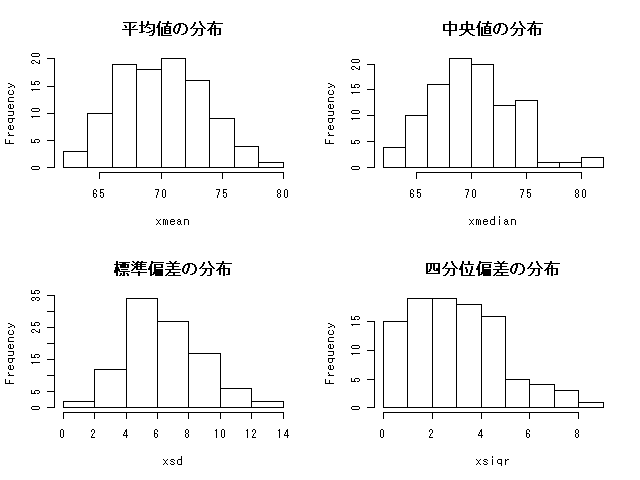 ●結果は右図。中央値や四分位偏差がとくに「小さい規模の集団」で「信頼性が高い」とは言えないと思われる。上のプログラムは母集団が1000人,サンプルサイズが5と極端すぎるので,もっと普通の数字で試した方がいいかもしれない。ともあれ,上記資料の文言は,必ずしも正しいとはいえないようである。どこかの教科書にそういう記載があるんだろうか? それとも,何かぼくが勘違いしているんだろうか。
●結果は右図。中央値や四分位偏差がとくに「小さい規模の集団」で「信頼性が高い」とは言えないと思われる。上のプログラムは母集団が1000人,サンプルサイズが5と極端すぎるので,もっと普通の数字で試した方がいいかもしれない。ともあれ,上記資料の文言は,必ずしも正しいとはいえないようである。どこかの教科書にそういう記載があるんだろうか? それとも,何かぼくが勘違いしているんだろうか。- Windows版2.3.1予報(2006年5月24日)
- ●Windows版R-2.3.1では,R ConsoleのGUI Preferenceでドロップダウンに出てこないフォントサイズも有効になるらしい(開発版の更新情報から)。以前,一時期そういう仕様で便利だったのだが,これが復活するとプレゼンというか実演に大変便利なので期待したい。
- 日本計量生物学会でのチュートリアルセミナープレゼンテーション資料(2006年5月30日)
- ●表記セミナーで講演したので,そのプレゼンテーション資料を公開する(pdf形式,約466 KB)。
- R News 2006年5月号(2006年6月1日)
- ●R Newsの2006年5月号が出たというアナウンスがEditor in ChiefのDr. Paul Murrellから流れてきた。RとGraphvizを使って家系図を描くという記事が面白そうだ。Paul Murrellといえばgridの開発者でR Graphicsという超マニア本の著者なので,R Newsも作図関係の記事が充実してくる傾向にあるのかもしれない。まあ,Rの大きな長所の1つが使いやすくて高度な作図機能にあることは確かだから,これは正しい方向性といえよう。あと,"Non-Standard Fonts in PostScript and PDF Graphics"というMurrell and Ripleyの記事にも痺れた。Table 2に... suggestions of Ei-ji Nakama.とあって,国際化は中間さんがいなくてはできなかったなあ,と今更ながらに思う。grid.text関数を駆使できれば人口ピラミッド作図関数(pyramid)はきれいに書き直せるんだろうなあと思うが,時間がない。
- R-2.3.1リリース(2006年6月2日)
- ●予定通りに,6月1日付けでR-2.3.1がリリースされた。いくつかの小さな改善と2,3のひどいバグを除去したということである。2バイト文字を扱えるプラットホームでは\uxxxx(xは16進コード)でUTF-8のキャラクタが指定できるようになった。たとえば,"\ufa11"で「崎」の旁の上が立の文字が表示できるし,"\u5d8c"で嶌が表示できるということだ。確かに2.4.0開発版でcat("\u5d8c\n")と打つと嶌が表示できるな。plot(1,1,pch="\ufa11")なんてこともできる(ただ,文字列として\uと16進4桁をcat()やpaste()でつないでもUTF-8とは評価されないようだ)。バグフィックスの中では,欠損を含む整数ベクトルについてのmean()のバグフィックス(ちゃんとNAを返すようになった)は大事だ。もっとも,最初から欠損値は除くか,常にna.rm=Tにしておけば問題ないわけだが。
- 統計数理研究所公開講座の配布資料(2006年7月26日)
- ●去る7月18日,19日と統計数理研究所で公開講座『医学統計におけるRの利用入門』をやってきたので,その際に配布した資料を(講義中に見つけた誤りを修正した上で)公開する(pdf形式,約700 KB)。
- リンク先変更(2006年8月23日)
- ●何日か前から,2chのスレッドが1000を超えて見えなくなっていたので,新しいスレッドにリンク先を切り替えた。
- R-2.4.0リリース(2006年10月4日)
- ●かなり大幅に更新・変更・追加が行われたR-2.4.0が10月3日付けでリリースされた。
- R News 2006年10月号(2006年11月1日)
- ●R NewsのVolume 6, No.4が出たというアナウンスがPaul Murrellから流れてきた。odfWeave,plotrix,rpanel,gsl,bsなど,いくつかのパッケージの紹介がメインコンテンツといえる。bsはBirnbaum-Saunders分布を扱えるようにするものだそうだ。新しく加わったパッケージのリストの中ではbiglmというのが目を引いた。要は,巨大なデータでも(一般化線型モデルも含めて)線型モデル分析ができるようなメモリ節約型のライブラリらしい。
- 『Rの基礎とプログラミング技法』(2006年11月1日)
- ●既に粕谷さんや三中さんのサイトなど各所で話題になっているが,U.リゲス(著),石田基広(訳)『Rの基礎とプログラミング技法』シュプリンガー・ジャパン,ISBN4-431-71218-6,税別3500円が刊行された。思いがけずご恵贈いただいてしまった(ありがとうございます)。
- ●原著はUwe Ligges (2004) Programmieren mit R, Springer-Verlag Berlin Heidelberg.である。ドイツ語からの翻訳ということだけでなく,訳者あとがきに『Rのプログラミング言語としての特質を活かすことによって,データ解析やグラフィックス作成の効率と可能性は飛躍的に増大するのだが,本書を除く他の「R本」ではこの点がほとんど強調されていない』とあるように,オブジェクト指向言語としての側面を強調した点に特徴がある。もっとも,これまでもそういう文献が皆無だったわけではない。例えば『The R Book』の第18章で高階さんがパッケージの作り方を解説しているし,竹内俊彦『はじめてのS-PLUS/R言語プログラミング』オーム社は,まさにS-PLUSやRでプログラムを書くことの解説書であった。しかし例えばPerlやCでプログラムは書けるので何となくRでのプログラミングもできるのだけれども,Rの特徴を生かしたプログラム技法が使えていないという,ぼくのような人間にとっては,バグの取り扱い方,第5章「効率的なプログラミング」におけるベクトル単位の演算子・関数群の解説,第6章のS3クラス,S4クラスごとのOOP技法,latticeグラフィックスの解説など,本書の内容の絞り込み方はピンポイントで役に立ちそうだ。
- 「Rによる統計処理」pdfファイル公開(2006年11月24日)
- ●本学社会情報学部の青木繁伸教授がpdf形式のテキスト「Rによる統計処理」(pdf形式,722.2 KB, 141 pp.)を公開された。これは凄いテキストだと思う。
- R 2.4.1リリース(2006年12月19日)
- ●R 2.4.1が12月18日付けでリリースされた。既にソースもWindowsバイナリも東大ミラーにも入っている。多くのバグフィックス(ただしたいていはマイナーなもの)を含むメンテナンスリリースとのこと。RjpWikiにアップデート情報の訳が載っている。
- R News 2006年12月号(2006年12月19日)
- ●R NewsのVolume 6, No.5が12月1日付けで出ていたのを書き忘れていた。ちゃんと読んでいないが,遺伝子解析にかかわるパッケージの紹介とか解説が多いように思う。
- メモ3つ(2007年1月11日)
- ●北大の久保さんの日誌にあったデータフレーム変換問題についてメモで触れておいたら,青木先生からwikiページに解決法をお教えいただいた。repをうまく入れ子にするのが鍵だった。
- ●ロジスティック回帰で独立変数に3水準以上のカテゴリ変数があるとき,そのまま投入すると1番目のカテゴリがreferenceになるのだが,2番目以降のカテゴリをreferenceにしたい場合があり,これまでは,いちいちコードを振りなおしていた。つまり,VILというカテゴリ変数があって,3つの村I, C, Rがあるときにstr(VIL)すると
Factor w/ 3 levels "C","I","R": 1 1 1 1 1 1 1 1 1 1 ...
のように表示されるわけだが,リファレンスカテゴリを"C"でなくて,敢えて"I"にしたいというような場合である。これまでだとrequire(car)してからVIL <- recode(VIL,"'C'='I';'I'='C';'R'='R'")
していたのだが,VIL <- relevel(VIL,2)
でいいのだ。 - ●教室セミナーで「RによるROC分析法」というミニチュートリアルをするので,配布資料(4ページ,pdf形式,106.2 KB)をアップロードした。この資料は教室のページにもアップロードする予定。
- 「Rによる医療統計学」発売(2007年2月11日)
- ●Peter Dalgaard著,岡田昌史監訳『Rによる医療統計学』,丸善,ISBN 978-4-621-07811-2(Amazon | bk1が発売された。一冊ご恵贈いただいたことに感謝>岡田さん。原著ISwRも名著だったから(かつて誰かRの質問に来た留学生に貸したまま行方不明なので,いま手元にはないが),たしかにこれを訳してテキストに使うのはいいアイディアかもしれない。
- ●原著タイトルからわかるように医療統計に特化した本ではないから,このタイトルだとかえって読者を狭めてしまう危険があるんじゃないかと思うが,日本の出版事情からすると,統計本はジャンルを絞ったものの方が出版されやすいということなんだろう。
- 「Rによる保健医療データ解析演習」(仮題)を公開(2007年2月16日)
- ●講義資料をcompileし,加筆修正して整合性をとっている途中段階だが,「Rによる保健医療データ解析演習」(仮題。なんか格好悪いので変えたいが,いい案が浮かばない)を公開した。感想,コメント等,ありましたら,よろしくお願いします。
- ●毎年大量に資料を印刷するのが辛いので,安い本になればいいなあという狙いです。まだ冗長なところがあるので切れるかも。
- 『Rで学ぶデータマイニング』(2007年4月24日)
- ●熊谷悦生・舟尾暢男『Rで学ぶデータマイニング:I.データ解析の視点から』九天社,ISBN 978-4-86167-176-0(Amazon | bk1)が出版された。
- ●ご恵贈いただいたのだが,これは面白い本だと思う。とくに18章「メディア等に溢れるデータ」や19章「合計特殊出生率と少子化」という目の付け所がいい。ちなみに脚注29に「元々の英語はTotal Fertility Rateであるので,訳したとしても全出生率にしかならないと思うのですが,いかがでしょうか」とあるのだが,これは歴史的な経緯で,人口当たりで計算される普通出生率がbirth rateであったのに対し,女性人口当たりで計算されるfertility rateを特殊出生率と訳したために,年齢別特殊出生率の合計という意味で「合計特殊出生率」という訳になったのだ。1994年に日本人口学会から,特殊を取って,たんに「合計出生率」としましょうと提案したのだが(国際人口学会編,日本人口学会訳「人口学用語辞典」厚生統計協会),一度人口に膾炙してしまった言葉はなかなか変わらないようだ。p.164は45歳から49歳ではなく15歳から49歳が正しいとか,p.168の箇条書きの2番目は分母と分子が逆だとか,コホートの定義が人口学的にはあんまり普通じゃないとか,図19.3は右すそを引いているのが明らかなので「正規分布で近似できそうな形状をしている」とは思えないとか,突っ込みどころはあるけれども,分布の当てはめとか回帰分析に展開したりするところなど,面白い。ただ,最後のOECDデータの分析は,地域相関研究であるが故の限界,という点にも触れてほしかったところ。以上,ざっと見た印象だが,楽しめそうな本をありがとうございました>舟尾さん。
- R-2.5.0リリース(2007年4月24日)
- ●かなり大幅に更新・変更・追加が行われたR-2.5.0が4月24日にリリースされた(R-announceにPeter Dalgaardが流したアナウンス"R 2.5.0 is released")。
- ●このバージョンは開発リリースで多くの新しい特徴をもっているという。codetoolsというパッケージが新しく推奨パッケージになったとか,新しいスクリプトエディタというかシェルというかよくわからないがRscriptが提供されたとか書かれていた。difftime()の仕様が拡張されたのも目を引いた。
- R News 2007年4月号(2007年6月5日)
- ●書き忘れていたが,R News Vol.7/1(リンク先はCRANの東大ミラー内にあるPDFファイル)が出ていた。
- ●バイナリファイルを十六進ダンプ表示するためのパッケージhexViewの解説があったが,その目的ならRを使わなくても,普通のバイナリエディタでいいような気がした。解説によると,memFormatとviewFormatを適切に指定すれば,どんなに複雑なバイナリデータでも正しく読める(らしい)ところが売りで,例えばDHS (Demographic and Health Surveys)のデータを貰ってきて分析したりするような場合に役に立ちそうだ。
- ●極値統計学のパッケージPOTの解説記事もあった。極値統計学は洪水やダム絡みで使えるかもしれないので押さえておくべきだろう。
- R-2.5.1リリース(2007年7月4日)
- ●これも書き忘れていたが,6月28日にR-2.5.1がリリースされた。メンテナンスリリースとのことだが,中間さんによって,sub()において日本語文字コードがCP932のときに一部の文字の置換に失敗する問題が解決されているので,Windows版のユーザは導入しておくべきと思う。
- ●ただ困るのは,R-2.5.0でRcmdr1.2-9では起こらなかった問題がRcmdr-1.3以降で起こることである。しかも,現在,Rcmdrを導入しようとすると1.3-3しか導入できない(古いバージョンはJohn Foxのサイトからも消えている)。例えば,散布図を描くダイアログのオプションが増えたのはいいのだが,x軸名,y軸名など<自動>がデフォルトになっているのをそのままにしておくとエラーが起こって散布図を描くことができない。線型モデルの当てはめで,モデル式を指定するときに,カテゴリ変数をダブルクリックして式に入れようとすると,変数名だけでなく,[要因型]という文字列も入ってしまうのでエラーになるのも問題である。手動で余計な文字列を削除すれば実行には問題ないので,要は,文字列をR本体に受け渡す部分にバグが入ったということであろう。自分はRcmdrを使わないから問題ないが,大学院生の演習でRcmdrを使ったので,この問題で苦しむ院生が大勢出て困っている。
- Microsoft Excel 97-2003形式.xlsファイルの読み書き(2007年8月17日)
- ●昨日知ったのだが,Microsoft Excelの.xlsファイルをRから直接読み書きするためのライブラリとして公開されているxlsReadWriteは凄い。テキストにも追記しようと思った。
- ●Excel97-2003の.xlsファイルをread.xls()関数で直接(何番目のシートを読むかは数字で指定。1枚目なら省略可),Rのデータフレームに読み込める。つまり,たくさんのフォルダに分かれた,たくさんのExcelファイルがあっても,list.files(".",recursive=T)関数を使って,Rから再帰的に全サブフォルダ内のファイルをリストにできるので,それを1つずつ自動的に直接読んでつなげていくコードが簡単に書けるし,そこでフォルダ名やファイル名を新しい変数として入れていくこともできる。日本語も大丈夫なようだ。
- ●ちなみに,xlsReadWriteライブラリは,元々delphiで書かれていたコードを援用しているらしく,Windows専用なようだ。LinuxやMacOS Xでは使えないのが残念。OOoのコードを参考にすればLinuxとかMaxOS Xでも行けると思うが。これまで,Excel形式ファイルを直接読む方法としては,RODBCライブラリでodbcConnectExcel()してチャンネルを作って云々と非常に面倒なやり方しか知らなかったのだが,xlsReadWriteライブラリのread.xls()関数なら,read.delim()とかread.csvのような,他のread.*()関数と同じく,ファイル名を指定するだけで中身がデータフレームに読み込めるので,非常に便利だ。
- ●有料のPro版もあるらしいが,上記の使い方ならフリー版で十分だと思う。
- 出版ラッシュ再び(2007年10月5日)
- ●このところ矢継ぎ早にR関連の本が出版されていて,多くはご恵贈いただいているので,メモには随時御礼を書いているのだが,このページで紹介していなかったので,まとめて書いておく。ありがとうございました>著者,訳者の皆様。
- ●B.エヴェリット(著)石田基広,他(訳)『RとS-PLUSによる多変量解析』シュプリンガー・ジャパン,3,500円+税,2007年6月28日発行,ISBN 978-4-431-71312-8(Amazon | bk1)。U.Ligges本を訳された石田さんが,またしても凄い本を訳された。さすがに『多変量解析』と銘打っているだけあって,内容も高度だ。初学者には薦めないが,この本で初めて知ったことも多かった。R本が増えてきたとはいえ,多変量解析に実際に使うための情報はまだ不足しているので,SPSSユーザを振り向かせるには,こういう本が必須だと思う。
- ●舟尾暢男(著)『R Commanderハンドブック』九天社,3,200円+税,2007年8月13日発行,ISBN 978-4-86167-191-3(Amazon | bk1)。舟尾さんの著作スピードには圧倒される。本業も忙しいだろうに。きっと余暇の全てをRに注ぎ込んでいるに違いない。本書は,Rcmdrの操作マニュアルである。第6章でカスタマイズ法まで説明されていて,これまでRを使ったことがなくて,Rcmdrを常用したいと思っている人には,とても役に立つ本だと思う。なお,R-2.5.1リリースの記事で書いた1.3以降のバグについては,予想通りサポートページで触れられていた。John Foxはこの問題,気付いてないんだろうか?
- ●樋口千洋,石井一夫(著)『統計解析環境Rによるバイオインフォマティクスデータ解析:Bioconductorを用いたゲノムスケールのデータマイニング』共立出版,4,300円+税,2007年9月25日発行,ISBN 978-4-320-05659-6(Amazon | bk1)。樋口さんは『The R Book』の著者の一人でもある。本書前半は,インストールの仕方から始まって『The R Tips』にもあるようなRの基本コマンド,オプションパラメータのマニュアルとして使えそうな感じだ。後半はタイトル通り,バイオ系の解析に必要なパッケージの導入の仕方とバイオ系データベースへのアクセスの仕方から始まり,マイクロアレイ解析やプロテオーム解析などが例示入りで説明されている。生物系の研究者が最初に買うR本としていいかもしれない。
- ●熊谷悦夫,舟尾暢男(著)『Rで学ぶデータマイニング:II シミュレーションの視点から』九天社,3,800円+税,2007年10月18日発行(→まだ書店にはない筈),ISBN 978-4-86167-198-2(Amazon | bk1)。またしても舟尾さんである。凄すぎる。今回の本は「シミュレーションの視点から」とのサブタイトルがついていて,扱われている題材は,選挙データ,ニューラルネット,株式売買データのようだ。とくに株式売買に割かれているページが多く,時系列解析の手法が多く説明されているようなので,そっち方面に関心がある人にお薦め。
- R-2.6.0リリース(2007年10月5日)
- ●以前から予告されていた通り,2007年10月3日付けでR-2.6.0がリリースされた(R-announceのアーカイヴ。リンク先ソースコードがR-2.5.0となっていて,P. Dalgaard自身によってすぐに訂正メールが投稿されたが,メールで一度流れたものはアーカイヴでもそのままなんだな。当然かもしれないが,P. Dalgaardはさぞや後悔していることだろう)。5日現在,既に日本のミラーサイトにもバイナリファイルまで行き渡ったようだ。パッケージは部分的にまだ2.6.0対応しおえていないものもあるらしい。
- R News 2007年10月号(2007年11月1日)
- ●またも書き忘れていたが,先月,R News vol.7/2(リンク先はCRANの東大ミラー内にあるPDFファイル)が公開されていた。
- ●一般化非線型モデルのパッケージgnmの解説とか,Rのスクリプト用にユーザーフレンドリなウェブインターフェースを作るためのウェブアプリRwuiの紹介とか,Crawley MJ (2007) "The R Book", Wileyの書評とか,目次を見ただけでも気になる内容が多い。
- 『Rによるデータサイエンス』(2007年11月1日)
- ●メモには書いたが,ここに載せ忘れていたので遅れ馳せながら紹介する。
- 金明哲『Rによるデータサイエンス:データ解析の基礎から最新手法まで』森北出版,ISBN 978-4-627-09601-1(Amazon | bk1)が出版された(ご恵贈ありがとうございました>金さん)。
- ●本書は,かの名著『宇宙怪人しまりす』がかつて連載されていたことで(一部には)有名な,『エストレーラ』に何十回にもわたって連載されている記事の一部に手を加えてまとめたものである。金さんの連載記事といえばRの玄人筋にもきわめて評判が高かったわけだが,『エストレーラ』を手に入れにくいこともあって,本書の出版は多くのR使いにとって待望のものだったといえる。きわめてコンパクトにまとまった第I部『Rとデータマイニングの基礎』に続いて,第II部に入るといきなり主成分分析,因子分析,対応分析,多次元尺度法,クラスター分析,と,ある意味よくわかる順番で多変量解析の手法が並んでいてニヤリとさせられる。t検定とかカイ二乗検定とか,統計解析入門には良く出てくる「検定」にはほとんど紙幅を割かずに,その分,生存時間解析ならパラメトリックモデル(加速モデル)まで説明されているし,サポートベクターマシンとかランダムフォレストとか樹木モデルとかカオス時系列とか,非常に新しい手法までスコープに入っている割り切り方が素晴らしい。これはじっくり読まねばなるまいと思うし,それだけの価値がある本だと思った。なお,本書のサポートページはここになるそうだ。
- R-2.6.1リリース(2007年12月4日)
- ●書き忘れていたが,11月26日付けでR-2.6.1がリリースされていた(R-announceのメッセージ)。基本的にはバグフィックスを主とするマイナーバージョンアップだが,Windowsユーザにとって重要なポイントはsave-to-postscriptのfixだと書かれていたので,過去の[Rd]を見直してみたら,以前メモしたpar(family="Japan1GothicBBB")にしないとダメなケースと同じところの問題だったのかもしれない。
- 『Rによる保健医療データ解析演習』出版関連情報(2007年12月4日;6日追記)
- ●詳細はこちらを参照されたいが,昨日無事に印刷所に入ったようで,12月25日刊行予定となり,版元サイトに紹介記事が掲載された。
- ●(6日追記)版元サイトの記事中,価格が税込み2,940円(予定)だったのが,税込み3,150円になってしまった。税込み3,000円未満に抑えてほしかったのだが,出版社の方にもいろいろ都合があるらしく仕方がない。なお,購入希望の群馬大学学生には著者割引(2割引なので,税込み2,520円となります)で買って再販売してもいいとのことなので,直接連絡ください。
- いくつかの情報(2008年2月2日)
- ●間瀬 茂『Rプログラミングマニュアル』数理工学社,ISBN 978-4-901683-50-0(Amazon | bk1)を買ってみた。雰囲気としてはRjpWikiに載っているようなtipsの書籍化という色合いが強いが,Rのプログラムを書くとき,やりたいプロセスに該当する部分を目次から探して読むというのが正しい使い方であるように思う(実は,カバー裏の「本書の特色」にも,「●関数・リスト等の項目ごとに章・節を設け,目次自体が諸機能の索引になるように工夫」と書かれていた)。普通にRを統計処理に使うだけの人が手を出す本ではないとは思うが,深い記述が多くて勉強になる,マニア垂涎の書。
- ●Rに組み込まれているデータフレームInsectSpraysのhelpには間違いがあって,Sourceが,Beall G (1942) The Transformation of data from entomological field experiments, Biometrika, 29, 243--262.となっているのだが,正しくはvol.29ではなくてvol.32であることを見つけた。報告するべきなんだが暇がなくてやっていない。
- ●R News Vol.7/3(リンク先は筑波大のCRANミラーにあるpdfファイル)。自分で使う予定はないが,SpherWaveというパッケージは凄いと思った。あとは,John Fox自身が書いた「プラグインパッケージでRコマンダーを拡張する」(Extending the R Commander by "Plug-In" Packages)も興味を引かれた。新しいライブラリでnonbinROCというのも気になった。
- ●R-2.6.2が2月8日にリリース予定。バグフィックスが主らしい。
- ●(New!! and Unique!!)レーダーチャートを描く関数とサンプル実行コードを作ってみた。radarchart.R。より良いサンプルコード,関数自体の改良,ドキュメント作成などしてくれる人がいたらいいなあ。
☆(2008年2月13日追記)コメントはメールか,2月8日のメモへお願いします。 - ●R-2.7.0 Win32版ではR consoleでMS-IMEをONにしたときにインライン変換ができるようになった。開発版で確認できる。
- ●統計数理研究所のサイトで公開されている,2007年12月のRユーザ会の資料は実に有用だと思う。
- ●RjpWikiに発表されているR AnalyticFlowは,将来的には大規模なコード開発に役立ちそうな気がする。今はそれよりむしろ教育用途で使えるかも。
- ●2008年2月1日に,useR! 2008の発表申込と参加登録の受付が始まった。何か出したいところだが,さすがにレーダーチャートを描く関数を開発しましたってくらいじゃ無理か。
- R-2.6.2リリース(2008年2月8日)
- ●2008年2月8日にR-2.6.2がリリースされた(リンク先はR-announceへのPeter Dalgaardの投稿)。
- ●メンテナンスリリースであり,多くの(ほとんどがマイナーな)バグを訂正したとのこと。
- rglライブラリ(2008年3月17日)
- ●割と古くからあるライブラリだが,あまり使ったことがなかった。3つの変数の関係を層別で図示すると,普通にlibrary(scatterlplot3d)するよりも,library(rgl)してグリグリとマウスで見やすい角度を探す方が便利なこともあることがわかったので,使い方を簡単にメモしておく。
- ●サンプルとして,Fisherのirisのデータで,花弁の長さ,花弁の幅,萼片の長さという3つの変数の関係を,品種別に色分けしてプロットし,マウスで見やすい角度に調整してからpngファイルに保存する場合を書いておく。
attach(iris) library(rgl) open3d() plot3d(Petal.Length,Petal.Width,Sepal.Length,col=as.integer(Species)) detach(iris) # マウスで見やすく操作してから次を。 snapshot3d("irisdata.png") - ●古いRだとattach(iris)の前にdata(iris)が必要だったが,少なくとも現在のWindows版では直接attach()できる。library(rgl)はrglライブラリをロードする。このライブラリを使うときはMDIよりSDIにしておく方がいい。open3d()でOpenGLの三次元描画デバイスが開く(閉じるときは右上の×をクリック)。このデバイスはウィンドウ端のドラッグで拡大縮小でき,最後にスナップショットを撮るときもそのデバイスサイズで撮れる。plot3d()で実際の描画が行われるので,その後マウスで図を動かして見やすい角度にしてから,最後のsnapshot3d()でpng形式で画像を保存する。ファイル名はフルパスで与えることもできるが,パスを指定しなければ作業ディレクトリに保存される。
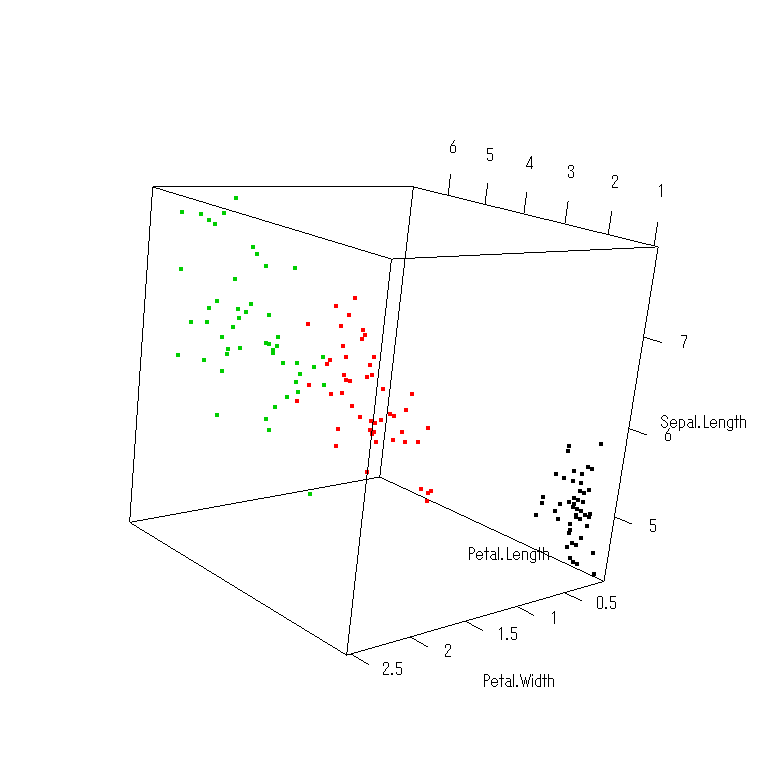
- R-2.7.0リリース(2008年4月23日;6月5日追記)
- ●2008年4月22日にR-2.7.0がリリースされた(リンク先は例によってR-announceへのPeter Dalgaardの投稿)。筑波大学のCRANミラーには既にWindows版バイナリのR-2.7.0-win32.exeがあった。
- ●ノンインタラクティブモードでのデフォルトのグラフィックデバイスがpostscriptからpdfに変わったそうだ。他にもいろいろ変わっているようだ。なお,Windows版は,ついにWin2000以降でないと動作しなくなったらしい。
- ●Windows環境でのpdfへの日本語出力にバグがあったのだが,R-2.7.0 Patched Build for Windowsのr45688以降でfixされた。そのため,Windows環境でのR-2.7.0のインストールには,2008年5月16日以降のR-2.7.0pat-win32.exeを用いるべきといえる。
- R News Vol.8/1公開(2008年6月5日)
- ●5月末にR News Vol.8/1(リンク先は筑波大のCRANミラーにあるpdfファイル)が公開されていた。segmentedというライブラリは以前このページでも考えたことがあるホッケースティック回帰を一般化した状況で使える回帰モデルのようである。巻末のR Foundation Newsに『Rによる保健医療データ解析演習』出版時に送金したdonationが掲載されていた。
- R-2.7.1リリース(2008年6月24日)
- ●2008年6月23日にR-2.7.1がリリースされた(リンク先は例によってR-announceへのPeter Dalgaardの投稿)。筑波大学のCRANミラーには既にWindows版バイナリのR-2.7.1-win32.exeがあった。CHANGESファイルによると,Rguiが当該localeでinvalidな文字を受け取った場合に\uxxxx形式に自動変換してRに渡してくれるようになったとのことなので,「高」の異体字の問題も解決するかもしれない。
- ●メモに中間さんから頂いたコメントにより,「高」の異体字がpdf出力できない問題は,内部的に一旦EUCに変換するため,EUC-JPにない文字は出ないせいだということがわかり,中間さんから教えていただいた回避法(source("http://r.nakama.ne.jp/AI/AI_UCS2.R")をやっておく)で無事に出力できた。いつもながらありがとうございます>中間さん。
- R-2.7.2リリース(2008年8月27日)
- ●2008年8月25日に予定通りR-2.7.2がリリースされた(リンク先はR-announceメーリングリストへのPeter Dalgaardからの告知メール)。既に筑波ミラーにWindows版バイナリもあった。
- ◎このページ内の「なぜRを使うべきなのか」の記載を若干改めた。
- R-2.8.0リリース(2008年10月21日)
- ●2008年10月20日にR-2.8.0がリリースされた(リンク先はR-announceメーリングリストへのPeter Dalgaardからの告知メール)。既に筑波ミラーにWindows版バイナリもあった。
- 『Rデータ自由自在』(2008年10月31日)
- ●出版されたばかりの,P. スペクター(石田基広,石田和枝訳)『Rデータ自由自在』シュプリンガー・ジャパン,ISBN 978-4-431-10047-8(Amazon | bk1)をご恵贈いただいた。いつもありがとうございます>石田先生。
- ●R本もいろいろ増えてきたが,本書のように思い切ってデータ操作に焦点を絞ったものはこれまでなかった。データ操作の仕方がまとめて解説されていることが本書を読みやすくしている。また,データベースと連携した操作の仕方は,ある程度Rに慣れた人にも役立ちそうだが,これだけではまだ情報が不十分なので,RMySQLの使い方だけで独立した1つの本があってもいいくらいだと思う。データベースということで言えば,いまOpenOffice.orgのbaseとRを連携して使ってみようかと思っているのだが,RjpWikiのデータベースとRでも「未確認」となっているので,trial and errorが必要だろう。本書でもさすがにbaseには触れられていなかった。
- R News Vol.8 No.2公開(2008年11月5日)
- ●昨日,R-announceで告知があったが,R News Vol.8/2(リンク先は筑波大のCRANミラーにあるpdfファイル)が公開されている。
- ●主な記事は,GGobiというデータ可視化ソフトとのインターフェースを提供するrggobiパッケージ,生態学的ネットワークを分析するパッケージbipartite,(ざっと見ただけではよくわからないが)線型予測子をもつモデルのオブジェクトのプロファイリングを行うらしいパッケージprofileModel,テキストマイニングのためのtmパッケージ入門,プレゼンに使うと驚かれるであろうanimationパッケージ(HTMLとJavaScriptとか,GIFアニメとかFlashでムービーを作れる),Vector Generalized Linear and Additive ModelsのためのパッケージVGAMなどの紹介記事と,R-2.8.0での変更点一覧,CRANの新着パッケージ情報,useR! 2008の報告とuseR! 2009の案内(7月8日から10日までフランスのRenneで行われる),DSC 2009の案内といったところであった。
- R-2.8.1のリリース予定発表(2008年12月11日)
- ●一昨日告知されたところによると,R-2.8.1は12月22日にリリース予定とのこと。
- R-2.8.1リリース(2008年12月22日)
- ●予告通り,R-2.8.1のリリースがアナウンスされた。
- ●difftime()関数の結果に適用可能な関数が増えたとか,自由度1未満でも(正なら)t分布の分位点関数が機能するとか,legend()関数でtitle.colが指定できるようになったとか,いくつかの新しい機能に加えて,多くのマイナーバグフィックスがあったらしい。
- multcompライブラリについて(2009年2月5日)
- ●去年の3月18日付けでメモしていたのを,ここには書き忘れていたが,R-2.6.2以降というか,multcompライブラリの0.993以降,Dunnettの多重比較をsimtest()で実行することができなくなっている。
- ●実はかなり前から,ヘルプには「simtest()は古いユーザインターフェースなので,glht()とsummary.glht()を使え」と書かれていたが,simtest()がわかりやすいので放置していた。
- ●コントロールと複数の実験群の比較というデザインで使うDunnettの多重比較の実行方法は,とりあえず,example(recovery)するとわかる。有意確率を出すにはglht()の結果のオブジェクトのsummary()をとればいい。
- ●ごく簡単な実例を載せておく。例えば,5人ずつ3群にランダムに分けた高血圧患者がいて,他の条件(食事療法,運動療法など)には差をつけずに,プラセボを1ヶ月服用した群の収縮期血圧(mmHg単位)の低下が5, 8, 3, 10, 15で,代表的な薬を1ヶ月服用した群の低下は20, 12, 30, 16, 24で,新薬を1ヶ月服用した群の低下が31, 25, 17, 40, 23だったとしよう。このとき,プラセボ群を対照として,代表的な薬での治療及び新薬での治療に有意な血圧降下作用の差が出るかどうかを見たい(悪くなるかもしれないので両側検定で)という場合に,Dunnettの多重比較を使う。Rでこのデータをbpdownというデータフレームに入力してDunnettの多重比較をするためには,次のコードを実行する。
bpdown <- data.frame( medicine=factor(c(rep(1,5),rep(2,5),rep(3,5)), labels=c("プラセボ","代表薬","新薬")), sbpchange=c(5, 8, 3, 10, 15, 20, 12, 30, 16, 24, 31, 25, 17, 40, 23)) summary(res1 <- aov(sbpchange ~ medicine, data=bpdown)) library(multcomp) res2 <- glht(res1, linfct = mcp(medicine = "Dunnett")) confint(res2, level=0.95) summary(res2) - ●結果の見方は自明であろうから書かないが,代表的な薬も新薬も有意水準5%でプラセボと血圧降下作用に有意差があったと言える。
- R-2.9.0予告と新刊情報(2009年3月25日)
- ●ここに書くのが遅くなったが,3月6日付けでPeter Dalgaardがannounceしたメールによると,R-2.9.0は4月17日リリース予定で,3月17日からプレリリース版のソースコードがダウンロードできるようになるそうだ。バイナリは3月20日頃からの予定らしい……ということで確認したら,既にWindows用alpha版もダウンロードできる(リンク先は筑波大学ミラー)ようになっていた。
- Rの開発者サイトからリンクされている最新版ニュースをみると,中間さんが開発された,pdf()とpostscript()でカーニングする機能がR-2.9.0で取り入れられたことが書かれていた。boxplot()の引数として行列を取れるようになったそうだ。つまり,これまでは,行列(MATRIXというオブジェクトだとしよう)の縦ベクトルを並べて1つの層別箱ひげ図の形でプロットしたければ,boxplot(data.frame(MATRIX))とする必要があったわけだが,boxplot(MATRIX)で済むそうだ。また,いきなりboxplot()で描画させずにいったん何か変数に付値しておき,bxp()関数を使って描画させることで,箱ひげ図の細かい制御ができることを知った。というか,example(bxp)とかexample(boxplot)をすると,これまで考えていたよりも,boxplot()が遥かに強力であることがわかった。率と率比の正確な検定のための関数poisson.test()がstatsパッケージに新規導入されたというのも興味深い。
- ↑と,メモに書いておいたら,中間さんからコメントいただいた。奥村さんのコメントがきっかけで開発が始まり,コーディングそのものはR教授による貢献が多大だったそうだ。
- ●RjpWikiのトップページで新刊情報を知った。青木繁伸先生の待望の著書『Rによる統計処理』(オーム社)と,金明哲先生の編集によるシリーズ本『Rで学ぶデータサイエンス』(共立出版)である。どちらも期待大。
- 『Rによる保健医療データ解析演習』の正誤表に第5章の訂正を追加(2009年4月17日)
- ●暫く前に人類生態の後輩であるたけしょうから指摘メールが届いていたのだが確認する暇が無く放置していた,表題のタイプミスを確認したので,サポートページの正誤表に追記した。読者の皆様,申し訳ありませんでした。
- ●青木繁伸先生の『Rによる統計処理』オーム社,ISBN 978-4-274-06757-0(Amazon | bk1)は先生自らお持ちくださり,ご恵贈賜ったのだが,pdfで公開されていたものよりも数段パワーアップしていると思う。固定長データの読み込みとか,table()のexclude=NULLとか,factor()とcut()の詳細な解説,あるいは分割表から元のデータを復元する方法の記述,さらには付録Aの行列計算の取り扱いなどは間瀬先生のマニア本『Rプログラミングマニュアル』数理工学社,ISBN 978-4-901683-50-0(Amazon | bk1)を思わせるけれども,その一方では統計処理や作図について,実にエレガントかつ広範な(非線型回帰とか数量化I類,II類,III類までも)解説が加えられているので,これ1冊を読みこなせばRによる統計解析がマスターできると言っていい本に仕上がっていると感じた。なお,版元サイト内のページには詳細目次や本書で使われているコードなどが置かれている(この項,数日前のメモに書いていたものを転載した)。
- R-2.9.0リリース(2009年4月17日)
- 予定通り,R-2.9.0のリリースがアナウンスされた。まあ,バイナリが国内ミラーに行き渡るまでは待ちだな。
- レーダーチャートを描く関数アップデート(2009年4月22日)
- ■昨年公開したレーダーチャートを描く関数だが,いろいろと不備があった。2つ以上の変数に渡って欠損値が続く場合でも正しく線をつなぐことができ,かつとりうる最小値と最大値の間を均等分割できるようにデータフレームの中に最小値も入れることができるように,データ形式も変更してversion 2を作成したので公開する。
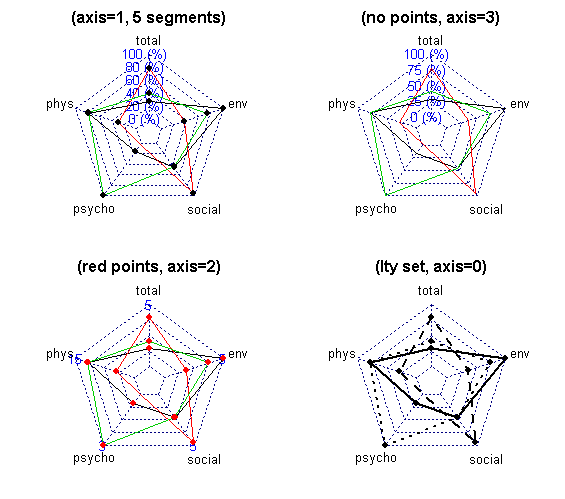
- (2013年3月11日追記)その後,大幅に書き換えて,fmsbライブラリに入れた。マニュアルはこちら。日本の都道府県について,主要死因別損失余命データを使ったプロファイル表示をする用例はこちら。
- カプランマイヤの仕様変更(2009年5月30日)
- 昨日のメモには書いたが,RjpWikiのQ&A(初級者コース)/11の情報から,survivalライブラリに入っているsurvfit()関数の仕様変更を知った。
- いつから仕様変更になったのかは定かでないが,R-2.9.0(survivalライブラリ2.35-4)では, 2.8.1まで許されていた,survfit(Surv(time,event))という表記法が許されなくなり,survfit(Surv(time,event)~1)と書かなくては動作しなくなった。1群しかないのに~1と書くのは冗長な気がするが,論理的一貫性が保たれることを重視したのかもしれない。
- R基本統計関数マニュアル(2009年6月17日)
- 6月4日のメモに書いたのだが,間瀬先生が(まだ作成中とのことだが),『R基本統計関数マニュアル』を公開された。このマニュアルの主目的は,『基本パッケージ中の統計関連関数の全体をカテゴリー別に紹介すること,およびそのヘルプドキュメントの「ほぼ忠実な」和訳を提供すること』だそうで,見事に目的を達成されていると思う。その意味で,時系列,MDS,クラスタリング,非線型回帰についても説明がある。また索引の付け方が参考になった。機能別に大きく分けておいて,その中をアルファベット順+五十音順に並べるというやり方は,使いやすそうだ。
- R-2.9.1リリース予定(2009年6月17日)
- 昨日のメモに書いたが,R-2.9.1が6月26日にリリース予定というメールが,R-announceで月曜に流れていた。バージョン番号から考えて,バグフィックスメインのメンテナンスリリースと思う(2.10.0ではfactor()の水準が重複しないように自動調整されるとか,KendallとSpearmanの順位相関係数の検定が,正確な確率を計算できないときにオプションで連続性の補正を使えるようになったなど,いろいろ変わるようだが)。
- R-2.9.1リリース(2009年8月24日)
- 書き忘れていたが,R-2.9.1のリリースは予定通り6月26日だった。リリースノート。
- 舟尾暢男『[R流!]イメージで理解する統計処理入門:データ解析の初歩から,シミュレーション,統計アプリの作成方法まで』カットシステム,ISBN 978-4-87783-229-2(Amazon | bk1)(2009年8月24日)
- 著者からご恵贈いただいたから褒めるわけではなく,いい本だと思う。
- 第12章「HTMLアプリケーションを用いた簡易Rツールの作成」は,javascriptを駆使してhtmlで作ったフォームからRのスクリプトファイルを書き出し,次いでRを呼び出してそのスクリプトファイルを実行させるという2段構えのアイディア。自分でも思いつかないでもなかったが,自作メニューを考えるならRcmdrを書き換える方が簡単そうなので,自分で実装しようとは思わなかった。実際に作られたものを見ると,実は以外に応用が利いて面白いかもしれないと思った。
- 内容的にはRのインストール方法を丁寧に(画面イメージも多く掲載してあってわかりやすく)OS別に解説するところから始まり,Rによるデータ解析の流れ,2群間の平均値の比較,2つの連続変数データの関係,2群間の割合の比較,イベントが起こるまでの時間,3群以上の群間比較,で「データ解析の初歩」は終わりで,残りが例数設計,乱数とシミュレーション,最後に既にふれた第12章という構成になっている。
- 各章ごとに参考文献と練習問題が充実していて,自習にも使えると思った。とくに,共分散分析と二元配置分散分析の交互作用について詳しく丁寧に解説されているのが素晴らしい。これくらいイメージ図を使って説明するとわかりやすいんだろうとは思うが,こういうのは意外に作るのが面倒で,自著では簡略に流してしまうところなので,舟尾さんの丁寧さには頭が下がる。いい本をありがとうございました>舟尾さん。
- R-2.9.2リリース(2009年8月24日; 26日追記)
- 予定通りR-2.9.2のリリースがアナウンスされた。目に見える大きな変化はあまりない模様。
- (26日追記)R-2.9.2のWin32版バイナリが筑波ミラーに入ったのでダウンロードした。インストールに際して,ライブラリすべてをダウンロードし直すと数時間かかるのでどうしようかと思ってCRANを眺めていたら,いい情報があったので,そのやり方でやってみた。まずこれまで入っていたRをアンインストールし,次いでR-2.9.2をインストールし,これまでのバージョンのディレクトリに残っているlibraryディレクトリの中身を全移動(ただし既に存在するディレクトリは移動しない……この操作はdk/wなら簡単かつ高速にできる)してから,R-2.9.2を起動して
update.packages(checkBuilt=TRUE, ask=FALSE)
してみたら,20分弱で完了した。 - IQR()関数が存在したこと(2009年10月27日)
- これまで,四分位範囲を求めるためにはfivenum(X)[4]-fivenum(X)[2]を関数定義して使っていたが,IQR()という関数がいつの間にかできていたのだった。ただしIQR()関数は,内部的にはquantile()で0.25と0.75を求めて差を出しているので,fivenum()を使う場合と結果がわずかに異なる場合があることに注意せねばならない。通常はほとんど差がなく,演習課題では男性で0.025の差が出たが,これくらいなら無視しても差し支えないだろう。
- R-2.10.0リリース(2009年10月27日)
- 10月26日夜,Peter Dalgaardによって,R-2.10.0のリリースがアナウンスされた。多くの新しい特徴を備えた開発リリースで,htmlベースの新しいダイナミックなヘルプシステムはとくに注目だそうだ。
- R-2.10.0のWindowsバイナリ版が,既に筑波大学ミラーに入っていたのでダウンロードした。変更点・追加点については,例によって,Windows版だけのこと,すべてのプラットホームに共通のことに分けて公表されている。64ビット版を含むWindows2000以降のOSで動作可能なようだ。グラフィックデバイスとしてbmp()が使えるようになったとも書かれていた。
- それで早速,R-2.9.2のときと同様に,まずR-2.9.2をアンインストールして,R-2.10.0をインストールし,R-2.9.2のディレクトリに残っていたライブラリを上書きなしで全移動し,その後でupdate.packages(checkBuilt=TRUE, ask=FALSE)をRの中で実行するという手順でのインストールを試みた。インストーラに少々問題があるようで,インストールに使う言語として日本語を選ぶと,インストールする中身を選ぶところから文字化けした。仕方ないのでEnglishでやったら文字化けはしなくなったが,ヘルプの設定のところで,"Please specify plain text, CHM help or HTML help, then click Next"と出ているのに選択肢は"plain text"と"HTML help"の2つしかないという不備があった。しかしそれ以外はとくに問題なくインストール作業は完了した。もっとも,アップデートが必要なパッケージは2.9.1から2.9.2にしたときよりもずっと多く,それだけ時間がかかったが。
- 舟尾さんのThe R-Tipsがオーム社から第2版として再刊(2009年11月20日,12月4日追記)
- 舟尾暢男さんから,『The R Tips 第2版』オーム社,ISBN 978-4-274-06783-9(Amazon | bk1)をご恵贈賜った。今は無き九天社から出ていた第1版は紫色基調のデザインだったが,オーム社に移った第2版は白ベースの中にRの大きな青い文字があり,しかも良く見るとただの青ではなくて海中の写真がRの形に抜かれている深いマリンブルーという凝ったもので,ぼくは第2版のデザインの方が好きだ。第1版と違ってCD付録はついていないのだが,Rのアップデートの速さから考えるとCD付録はすぐに古くなってしまうので,つけなくて正解だと思う。面映ゆいことに(初版のときのまま)謝辞のトップに挙げてくださっていて恐縮してしまう。参考文献もぼくの本が最初2つに挙げられていて有難い限り。かなり網羅的に書かれたRのマニュアルっぽい本なので,統計学はわかっている人がRの使い方を知るために1冊だけ本を買うというのなら,本書が一押しだと思う。
- それにしても舟尾さんの執筆能力は凄いと思う。いつ眠っているんだろう?
- 追記(2009年12月4日):ただの再刊というわけではなく,全体にわたって修正・加筆されている。見やすくなったし,表記も「沢山」が「たくさん」に変わっているなど,出版物として普通にされている表記になったと思う。第1章の「セットアップ」を「インストール」にしたのもいい判断だと思う。内容も増え,大幅に増ページされている。とくにデータハンドリングのところが大幅に拡充され,RODBCライブラリを使ったAccessからの読み込みの説明なども付いた。Rのバージョンも初版出版時には1.9.1だったのが2.8.1になっている。実に有効なアップデートがされたなあと感じた。
- 石田さんの新しい翻訳物(『自由自在』シリーズ)出版(2009年12月4日)
- D.ショーカー著,石田基広/石田和枝訳『Rグラフィックス自由自在』シュプリンガー・ジャパン,ISBN 978-4-431-10069-0(Amazon | bk1)をご恵贈いただいた。いつもありがとうございます>石田先生。この本の原題は,"Lattice - Multivariate Data Visualization with R"であり,latticeライブラリの活用法が書かれた本である。北大の久保さんが訳された"R Graphics"と合わせると,Rを使った高度な(とくに多変量の)グラフ作成は,ほぼ完全にカバーできるだろう。
- Rで数学をやってみる(2009年12月4日)~最近のメモからのまとめ
- ※この項,長すぎるので「統計処理ソフトウェアRについてのTips」の下の方に移しました。12月9日に追記しています。12月11日にも追記しています。
- R-2.10.1リリース(2009年12月15日)
- 予告されていた通り,12月14日付で,R-2.10.1がリリースされた。マイナーバージョンアップなので,それほど急いで更新しなくてもよさそう。
- pairwise.fisher.test開発(2009年12月24日;12月28日追記)
- ●群馬大学医学科2年生の統計演習の課題解答例を作っていて,期待イベント数が5未満になる場合の比率の差の多重比較をする必要があり,PWFT.Rを開発した。
- ●使い方は,pairwise.prop.test()と同様,pairwise.fisher.test(numevents, numtotal)とするだけで良い。第一種の過誤の調整方法はHolmの方法に固定した。
- ●メモの方でコメントのやり取りをした後で,青木先生から素晴らしいコードをいただいた。許可をいただいたので,PWFT2.Rとして掲載しておく。
- ●同じサンプルデータを分析した場合,PWFT.Rの出力は
となるのに対して,PWFT2.Rの出力は** Exact pairwise comparison of proportions with ** ** Holm's adjustment for multiplicity ** p.adj 1組-4組 0.03347455 2組-4組 0.48411122 1組-3組 0.50111361 3組-4組 0.58352932 1組-2組 0.47080405 2組-3組 0.72972614
となる。1組と2組の比較のp値が異なるが,本来は有意でなくなったところ以降はすべて保留とすべきなので,2組と4組の比較以降のペアについてのp値は意味がなく,それ以前の比較より小さなp値にしないという意味では,PWFT2.Rの方が妥当な調整だと思う。検定の多重性の調整は本来,第一種の過誤を調整するのであってp値を調整するのではないが,第一種の過誤の調整値とp値を両方表示して有意性を判定していくのは見難いため,Rの出力は便宜上p値の方を調整して見せていること(その点は,pairwise.t.testやpairwise.prop.testも同様)にも注意されたい。Pairwise comparisons using Pairwise comparison of proportions (Fisher) data: flu out of pop 1 2 3 2 0.584 - - 3 0.501 0.730 - 4 0.033 0.484 0.584 P value adjustment method: holm - 人口ピラミッド関数書き換え,パッケージ化,このページの再構成(2010年1月5日-6日,8日追記)
- ●こんなことをしている場合ではないと思いつつ,思いついた時にやっておかないとできないので,人口ピラミッド描画関数を低水準関数だけで描くように全面書き換えし,パッケージ化もしてしまった。
- ●ついでに,このページを再構成してみた。大項目へはページトップから飛べるようにした。
- ●(1月8日追記)無事CRANにacceptされたので,その関連のことを追記した。
- 緒賀郷志『Rによる心理・調査データ解析』東京図書(2010年1月11日)
- ●このページに載せるのは遅くなってしまったが,数日前に,緒賀郷志『Rによる心理・調査データ解析』東京図書,ISBN 978-4-489-02067-4(Amazon | bk1)をご恵贈いただいた。ありがとうございます。
- ●心理学分野でのデータ解析方法の教科書として評判が高いという,小塩真司『SPSSとAmosによる心理・調査データ解析』『研究事例で学ぶSPSSとAmosによる心理・調査データ解析』(ともに東京図書)を底本として(小塩氏の許諾を得て),SPSSではなくRで解析できるように「初めてRに触れる人向けに」解説した本だということである。
- ●画面キャプチャ図が多く,確かにR初学者に向いているように思うし,尺度構成などは心理学にフォーカスした本書ならではの内容で,これまでのR本には少なかったコンテンツかもしれない。ただ,使っているバージョンがR-2.8.1なので,2.9,2.10と進むにつれて内部構造がかなり変わりつつあることを考えると,今後画面や操作が変わってしまって新しいバージョンでの操作とは合わなくなる可能性もあるが,その辺はこの種のソフトウェア初心者向けの解説書の宿命だろう。
- 参考になるサイト"One R Tip A Day"(2010年2月8日)
- ●1月28日のメモから以下採録。
- ●One R Tip A Dayというサイトに,Rでレーダーチャートを描く例が紹介されているのを見つけた(このサイト自体,いい企画だと思うけれども,よくネタが続くなあと感心する)。実はplotrixというパッケージに入っているradial.plot関数を使うと,自分で関数を開発なんてことをしなくても,普通のレーダーチャートを描けるのだった。ふと気になってplotrixパッケージのヘルプを探してみたら,pyramid.plotという関数が存在して,自分で開発してパッケージ化したpyramid関数よりも高度な人口ピラミッドの描画ができるのだった。うーん,負けたという感じ。しかしまあ,どちらも若干違うからいいか。なお,plotrixパッケージは,他にもいろいろ凝ったグラフ作成関数を含んでいるようなので,次に何か作りたいグラフができたら,まずはplotrixにないかを調べることにしよう。
- Onkyo BXに最低限のR開発環境をセットアップ(2010年2月8日)
- ●R-2.10.1patをダウンロードしてインストールしたら普通にできた。
- ●パッケージビルドのためには,2010年2月4日のメモに書いたように,RtoolsのRtools210.exeをダウンロードしてインストールすれば,それ以外に必要なことは,RのbinとRtools内の各binにパスを通すだけだった。つまり,マイコンピュータのプロパティの詳細設定タブ中にある環境変数の最後に,;"C:\Program Files\R\R-2.10.1\bin";C:\Rtools\bin;C:\Rtools\MinGW\bin;C:\Rtools\Perl\binを追加してOKするだけで良かった。BXのCドライブにworkというディレクトリを作ってpyramidサブディレクトリをコピーしてから,コマンドプロンプトを起動してcd c:\workし,そこでRcmd build pyramidとやったら,見事にtar.gzがビルドできた。もちろんTeXを入れていないのでpdfはできないし,htmlヘルプもできないが,とりあえず開発環境としては十分だろう。
- Cronbachのα係数を求める関数の1行定義(2010年3月8日)
- ●R実践活用勉強会でWHOQOL-BREFを解析する方法を説明する一環で作ってみた。
alpha <- function(X) { dim(X)[2]/(dim(X)[2]-1)*(1-sum(apply(X,2,var))/var(rowSums(X))) }- ちなみにCronbachのα係数については,BMJのサイトで全文公開されている,Brand and Altman (1997)の説明が非常にわかりやすくて参考になる。
- 人口ピラミッド作成パッケージの更新(2010年3月11日)
- ●1月末からリクエストをいただいていたのだが,漸く実装できたのでバージョン1.2とした。
- 塗り分け地図についての注記(2010年3月31日)
- ●maptoolsライブラリがS3クラスをサポートしなくなったという,かなり前に行われていたらしい変更をやっと知ったので,『Rによる保健医療データ解析演習』サポートページに情報を追加した。ここにも解決策だけ掲載しておく。
- ●RjpWikiに牧山さんが県ごとに分割後,圧縮して掲載されているjapan_ver62.zipをダウンロードし,展開してできるファイルのうちるgunma.dbf, gunma.shp, gunma.shxと,agedprop2006.txtを作業ディレクトリにおき,classmap2.Rを実行すれば,gunmaagedprop2006.pdfができあがる。コードはS3クラスを使う場合よりすっきりしているから,下位互換性が保たれなかったのは仕方ないのかもしれない。
- R-2.11.0のメッセージ日本語訳開始(2010年4月5日;4月23日追記)
- ●4月3日にRjpWikiで岡田さんによるアナウンスがあり,pootleで当該作業が始まったことがわかった。しかし,この時期は異常に忙しいので,どれくらい貢献できるか微妙。
- ●(4月23日追記)結局,今回はまったく貢献できないでいるうちに作業完了となってしまった。
- 『ExcelでR自由自在』ご恵贈御礼(2010年4月5日;4月23日追記)
- ●Heiberger RM, Neuwirth E "R Through Excel"を石田基広さんと石田和枝さんが翻訳された『ExcelでR自由自在』シュプリンガー・ジャパン,ISBN 978-4-431-10088-1(Amazon | bk1)をご恵贈いただいていた。いつもありがとうございます>石田さん。
- ●ExcelのアドインからRの全機能を使えるようにするパッケージを開発した人たち自身が入門的な使い方を書いた本を翻訳されたものらしい。Rcmdrとも連携しているようで,これが広まると,ますますRの敷居が低くなるのではなかろうか。言語の障壁を下げるという意味で,本書の翻訳の意義は大きいと思う。ただ,入門書としては,4500円という値段が心理的な障壁になるかもしれない。もちろん,これに類した機能をもつソフトの値段に比べたら,タダみたいに安いのだけれども。
- ●既にRを使っている環境でこれをインストールするのが難しくて,いろいろと悪戦苦闘中。
- ●(4月23日追記)悪戦苦闘の原因はR本体がR-2.10.1 Patchedだったせいらしく,R-2.11.0をインストールしてから同じ手順でやり直したら,あっさり使えるようになった。
- R-2.11.0リリース(2010年4月23日)
- ●昨日,Peter Dalgaardからアナウンスが流れたR-2.11.0だが,既に筑波ミラーに入っていたのでWin32版をXP Pro+SP3環境でインストールしてみた。手順は,(1)R-2.10.1 Patchedのアンインストール,(2)R-2.11.0のインストール(インストールに使う言語はEnglishにすること),(3)R-2.10.1 Patchedのディレクトリに残っているlibraryディレクトリの中身をR-2.11.0のディレクトリ内のlibraryディレクトリに全移動(ただし既に同名のサブディレクトリがある場合は移動しない),(4)R-2.10.1 Patchedに残っているファイルを全削除,(5)R-2.11.0の起動,(6)update.packages()を実行,でうまくいった。
- ●上記の通り,こうしてR-2.11.0環境を構築してからRExcelのインストールに再挑戦したら,あっさりうまくいった。見つかったバグへの修正対応が最も迅速にされたバイナリがPatchedなわけだが,こういうことがあると,Patchedは勧め難いなあ。
- ●(追記)しかし,この状態だとRの起動に時間がかかり過ぎるので,結局アンインストールしてしまった。
- R-2.11.1リリース(2010年6月1日)
- ●予定通り昨日5月31日にリリースされ,Peter Dalgaardから告知されたR-2.11.1だが,既に筑波ミラーに入っていたのでWin32版をXP Pro+SP3環境でインストールしてみた。手順は例によって,(1)R-2.11.0のアンインストール,(2)R-2.11.1のインストール(インストールに使う言語はEnglishにすること),(3)R-2.11.0のディレクトリに残っているlibraryディレクトリの中身をR-2.11.0のディレクトリ内のlibraryディレクトリに全移動(ただし既に同名のサブディレクトリがある場合は移動しない),(4)R-2.11.0に残っているファイルを全削除,(5)R-2.11.1の起動,(6)update.packages(ask=FALSE)を実行,でうまくいった。
- ○update.packages(ask=FALSE)が一度でうまく行かないときは,もう一度tryしたら,失敗したパッケージからインストールを継続してくれてうまく行った。
Correspondence to: minato-nakazawa@umin.net.