- 新しい入門記事,動画など(2010年7月23日;8月6日にリンク先修正)
- ●山口大学教育学部の教育心理学教室から,Rオンラインガイドとして,10回構成の動画チュートリアルが公開されている。
- ●バクフー社長の柏野雄太さんが,実践!Rで学ぶ統計解析の基礎という連載を始められた。大学教員が書くものとは一味違っていて興味深い。
- 大学院統計演習のテキストを更新(2010年8月17日)
- ●大学院医学統計演習のテキストpdfファイルを更新した。和文と英文でほぼ同じ内容を提供すること,統計解析の基礎について簡単な原理とRコンソールでの処理法とRcmdrでの操作を併記すること,が必要だったので自作するしかなかった。
- ●完成度が低いので恥ずかしい気もするが,もし読まれた方は,お気づきの点があればお教えいただければありがたい。
- CRANにfmsbパッケージを投稿してみた(2010年8月20日)
- ●『Rによる保健医療データ解析演習』で作った関数群は,かなり前にパッケージ化しておいたのだが,サポートページの関数群と整合性をとっていなかったため,ローカルにしかアップロードしていなかった。今日,サポートページの関数群の方を,fmsbパッケージを使うように書き換えたので,パッケージとしてCRANに投稿してみた。
- ●もし通れば,pyramidに続き2つ目のパッケージとなる。大学院統計処理演習テキスト英語版でもこのパッケージを使った説明があるので,CRANにあった方が何かと便利だと思って仕上げてみた。
- ●ただ,英語をもっとbrush upしたいのだけれど。Nativeの方からコメントが貰えたらいいなあ,という期待も密かにある。
- Maternity History Chartを描く関数の開発など(2010年10月5日)
- ●9月14日にPeter Dalgaardからのアナウンスがあったが,R-2.12.0は10月15日リリース予定だそうだ。
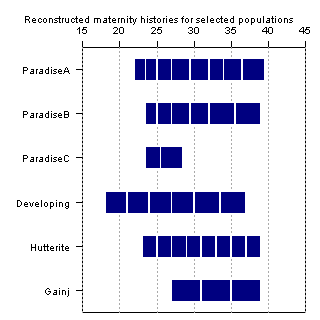
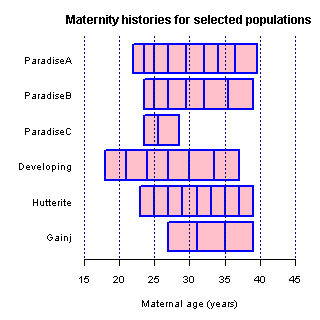
- ●日本地理学会のシンポジウムでソロモン諸島の高出生力について発表するとき,以前はOpenOffice.orgのDrawでマウスを使って描画していた,母親の再生産歴のグラフ(Dr. James William Woodが"Dynamics of Human Reproduction"で提示したものをmodifyした)をプレゼンに使う必要があり,きれいに作り直そうと思ったのがきっかけで,それを関数化してみた。2通りのやり方を思いついたので,両方やってみた(考え方は作った日のメモに書いた)。Rのコードはmhchart.Rである(実行すると作業ディレクトリにpngファイルが2つできてしまうので注意されたい)。グラフを下に示すが,plotrixライブラリを必要とせず,枠線がある方が見やすいと思うので,たぶん右のスタイルの方がいいように思う。もう少し整理して人口分析用のライブラリ(これから開発しようと思っている)に入れたい。
- R-2.12.0リリース(2010年10月16日~18日;22日追記;27日追記)
- ●予定通りに10月15日付で,R-2.12.0がリリースされた。Peter DalgaardがR-announce MLに流したアナウンスをざっと見た限りでは,print.lmやprint.glmで長い行は自動改行するようになったことが目についたくらいで,それほど大きな変更点はないようだ。
- ●Windows版に限ると大きな変更点があって,このバージョンから64bit版と32bit版が統合された。インストーラファイルも,これまでR-2.11.1-win32.exeなどだったのが,R-2.12.0-win.exeとなった。32bit版Windows環境では32bit版だけがインストールされ,64bit版Windowsでは32bit版と64bit版のRのどちらをインストールするかを選ぶことができる(デフォルトは両方インストールする),と書かれている。CRANの兵庫教育大ミラーには既にあって,インストーラが約37 MBと書かれていたが,ダウンロードがうまくいかなかった。まだミラーが完全ではないのかもしれない。
- ●CRANからR-2.12.0-win.exeをダウンロードしたら,Firefoxのダウンロードマネージャでは33.5 MBと表示された。ダウンロード済みのファイルは,35,134,098バイトだったので,確かに33.5 MBだった。なお,インストールに使う言語を日本語にすると途中から文字化けする症状は変わらなかったので,Englishでインストールした。しかし,%Program Files%\R\R-2.12.0\bin\R.exeは存在するのだけれども,CRANの説明に書かれていることが正しいなら,\binの下にi386というディレクトリとx64というディレクトリができて,それぞれ32bit版バイナリと64bit版バイナリが入るはずなのに,そのどちらのディレクトリも存在しなかった。これは32bit環境のXPでのインストールに問題が起こるということか,またはインストーラの作成ミスであろう。R-usersメーリングリストでも同様な指摘メールがあって,Duncan Murdockが,「ご指摘ありがとう,確かにこのビルドは何かが間違っていたようだ……」と返事をしていたので,インストーラの作成に問題があったということだろう。まだ待ちだな。
- ●(2010年10月17日追記)R-develメーリングリストで出た上記現象についての質問にDuncan Murdockから返事があって,10/15のタイムスタンプのものは,確かにi386以下が欠けているので,ビルドし直してタイムスタンプが10/16となったものを再アップロードしたとのこと。筑波大ミラーは反応がなく,兵庫教育大ミラーにあるものは,Firefoxのダウンロードマネージャでダウンロード開始時に33.5 MBと出てくるので10/15バージョンと思われたのでキャンセルした。CRAN本体からダウンロードしたら36.5 MBと出たので,今度は大丈夫だろう。
- ●(2010年10月18日追記)朝,兵庫教育大ミラーを使って,R-2.12.0にR-2.11.1のディレクトリに残っていたlibraryをコピーして(上書きはしない)からupdate.packages(ask=FALSE),というライブラリアップデートを実行したら,Rcmdrを含むパッケージがちゃんとアップデートできて動くようになったので,当初の問題は解決して,ミラーも完了したと考えていいと思う。なお,Windows自体が32bit環境の場合,binディレクトリ下にi386ディレクトリはインストールされるが,64bit版の実行ファイルが入っているx64ディレクトリはインストールされない(当然のことだが念のため書いておく)。
- ●(2010年10月22日追記)三中さんの日記からのリンクにお答えしておくと,昨日メモした通り,上の手口だけでパッケージの更新がうまくいかないときは,当該パッケージを,例えばdateパッケージだったら,install.packages("date",dep=TRUE)などとしてインストールし直すだけでうまくいくはず。Rcmdr自体の呼び出しには成功するけれども,途中でMASSパッケージを呼び出そうとしてエラーがでる場合なら,install.packages("MASS",dep=TRUE)でMASSパッケージをインストールし直せばいいはず(ただ,MASSはrecommendedだから,本体と同時にインストールされるはずで,このエラーは起こらないと思うが……)。少なくとも,ぼくはR-2.12.0でRcmdrが使えている。
- ●(2010年10月27日追記):今日のメモのくっつきbbsにいただいた,通りすがりさんからのコメントによると,update.packages(checkBuilt=T)が解決策になりそうです。お時間あればお試しください>三中さん。
- 統計数理研究所の共同研究集会(2010年10月18日)
- ●例年,中野教授が中心になって実施されている,統計数理研究所のR関係の共同研究集会が,今年も11月25日から27日に実施される。プログラムをみると,海外ゲストによるチュートリアル講演がそれぞれ1日がかりと充実していて,25日にWickhamがggplot2を,26日にLiggesが(たぶん)パッケージの作り方をやるのだと思われる。27日は恒例の国内ユーザ会のようで,今年の発表者には社会情報学部の青木先生も入っているし,三重大の奥村先生による「TeX+Rによる美文書・美グラフ作成」には激しく心惹かれる。25日と26日は大学院研究討論発表セミナーがあるし,26日午前には講義もあるので無理だが,27日土曜だけでも行きたいなあ。
- フォアグラウンドカラー指定(2010年10月19日)
- ●pyramidライブラリを使っているという海外の方から,暗い背景のプレゼンテーションに貼り付けたいので,文字や軸の黒で描かれている部分をもっと明るい色に変更できないかという要望があった。
- ●関数定義内部で対応するには相当な手間がかかりそうだが,pyramidライブラリは標準のグラフ機能だけを使って書いてあるので,この問題への対処は,描画前に,例えば,par(fg="yellow")などとしておくだけでいい。描画後にウィンドウズメタファイルとして保存し,暗い背景の上に貼り付ければ,それだけでうまくいく。
- ●その旨,質問者へ返事したら,ご満足いただけたようだ。
- 『Rで学ぶベイズ統計学入門』(2010年11月29日)
- ●J.アルバート著,石田基広/石田和枝訳『Rで学ぶベイズ統計学入門』シュプリンガー・ジャパン,ISBN 978-4-431-10238-0(Amazon | bk1)をご恵贈いただいた。原著の"Bayesian Computation with R"は出版された年に買って,時々拾い読みしていたのだが,通して読むには時間がなかった。人気が高い本のようで,既に原著は第2版になり,本書のために開発されたLearnBayesパッケージも大幅にバージョンアップされているそうだが,本書はその第2版の方の翻訳である。「ベイズ統計学の基礎知識と実践的技法を学ぶテキスト」と銘打たれている通り,MCMCとかGibbs Samplingの解説も含まれているので実践的にも使えると思う。大変有難い献本であった。ありがとうございました>石田先生。
- ご恵贈御礼:『R初心者のためのABC』(2010年12月8日)
- 徳島大学の石田基広先生から,A.ジュール/E.イエノウ/E.ミースターズ(著)石田基広/石田和枝(訳)『R初心者のためのABC』シュプリンガー・ジャパン,ISBN 978-4-431-10220-5(Amazon | bk1)をご恵贈いただいた。ありがとうございます>石田先生。ざっと眺めてみたところ,本書はRに触るのもほぼ初めてという人を対象にした,本当のR操作の入門書と位置付けられていて,統計処理とRの操作に同時に入門するのは大変なので,統計処理には敢えて触れないことにしたのだそうだ。統計処理よりもRの操作をメインに据えたという意味では,舟尾さんの「The R Tips」(オーム社)や,高階さんの「Rプログラミング&グラフィックス」(九天社が潰れたので,現在では「プログラミングR:基礎からグラフィックスまで」と改題かつ加筆修正してオーム社から販売されている),間瀬先生の「Rプログラミングマニュアル」(数理工学社),本書と同じく石田先生が翻訳されたU.リゲスの「Rの基礎とプログラミング技法」(シュプリンガー・ジャパン)に近いか。
- しかし,これまで出たこれらの本が,どちらかといえば中級~上級者向けであったのに対して,初心者にターゲットを絞って,Rの操作に関する部分を丁寧に説明することにフォーカスした本書の狙いは,いい目の付けどころかもしれない。
- なお,一読して,なぜ翻訳なのにこんなに? と思うほど,「第1章 最初の一歩」の辺りは日本のユーザへの配慮が行き届いているのが不思議だった。画面キャプチャによる図が日本語版の新しいものと差し替えられているのはわかるが,本文自体,日本のユーザをターゲットにしたとしか思えない記述がされているところがいくつもあった(RjpWikiが出てきたり)のだ。もしかすると日本向けに石田先生が加筆しているのだろうかと思い,Springerのサイトで見ることができた原文の一部と比べてみたら,当該部分はやはり石田先生による翻案になっているようだ。例えば,原文で"If you click on the CRAN link, you will be shown a list of network servers all over the planet. Our nearest server is in Bristol, England. Selecting the Bristol server (or any of the others) gives the webpage shown in Fig. 1.2."とある部分が,この訳書では,「CRANのリンクをクリックすると,地球上で利用可能なネットワークサーバーの一覧が表示されます.日本の場合,たとえば筑波大学Japan (University of Tsukuba: http://cran.md.tsukuba.ac.jp/)を選ぶとよいでしょう.選択すると,図1.2のサイトが開きます.」(太字で強調した部分が,訳ではなくて翻案)となっている。「超初心者向け」であることを考えると,このような,本質を損なわず,かつ読みやすくしてくれるような翻案はありだと思う(でも,訳者あと書きには,そのことに触れておく方が,より親切ではないかと思ったが)。実は統計の演習をしていても,本書で扱われているようなところは,学生が引っ掛かりやすいので,今年はテキストとは別に関数のまとめを作って公開している(当該講義のページを参照)が,その辺りだけ先に本書でマスターしておく手はあるかもしれない。
- R-2.12.1リリース(2010年12月16日)
- 予定通りにR-2.12.1がリリースされた。恒例のPeter Dalgaardのアナウンスを見る限り,概ねbug fixで大きな変更はなさそうだ。自分の使い方で関係してきそうなのは,reshape()の微妙な変更とか,data.frame()でのformat()の制限緩和とか,predict()でtermsとintervalを両方指定してはいけないとかいった辺りか。あと,pdfマニュアルが圧縮1.5形式になったので容量が従来の半分くらいになったのは,ハードディスク容量の節約という意味では歓迎したい。
- R-2.12.2リリース(2011年2月28日)
- 2月25日にR-2.12.2がリリースされた。Peter Dalgaardのアナウンスによると,R-2.10.0以降,C99複素数サポートが無いコンパイラ環境(CygwinやFreeBSDなど稀)では,複素数演算が不正確になっていたのを直したということだ。Cygwinということは,Windows版が該当するので,Rで数学をやってみるなどしたい方は,バージョンアップは必須であろう。
- 理由はわからないが兵庫教育大ミラーからのWindows版インストーラのダウンロードがうまくいかなかったので,筑波大学ミラーからダウンロードした。インストーラ実行時の言語選択は,これまでと同じで日本語だと文字化けするのでEnglishを選ばねばならない。ライブラリのアップデートは,これまでのバージョンをアンインストールして残っているlibraryディレクトリの中身をR-2.12.2のlibraryディレクトリの中に全移動してから,update.packages(checkBuilt=TRUE,ask=FALSE)で済みそうだ。
- メタアナリシスのパッケージについて(2011年3月9日)
- 最近,R実践活用勉強会で,丹後俊郎先生の『メタ・アナリシス入門:エビデンスの統合をめざす統計手法』朝倉書店(ISBN4-254-12754-5)をテキストにして,Rでメタアナリシスを実行する方法を演習している(英文資料pdf:1回目,2回目,4回目;3回目は資料なし)
- Rのメタアナリシスのパッケージはrmetaとかmetaなどもあるが,metaforというパッケージがかなり充実している。詳細な説明として,48ページもある論文がダウンロードできる。
- PETOの方法については,metaforパッケージのrma()関数を使う。感度分析については,(1)モデルの違いの影響,(2)研究データの質の影響,(3)研究のサンプルサイズの影響,(4)中間解析の結果から途中で止めた研究データを除外することの影響を見るべきだが,metaforパッケージのrma()関数の中で,method="FE"で固定効果モデルにした場合と,methodを指定しないでランダム効果モデルにした場合の違いをみる他は,すべて,subsetでデータフレーム自体を分けてしまえばできる方法である。今回,実際に演習できたのは,トライアルのサイズが小さいときは効果が大きいものしか統計的に有意にならないのでpublication biasが起こりやすいのではないかという点で,subset()の中で,死亡数の合計が50以下か,50を越えて100以下か,100を越えているかという条件により,データフレームを3つのサブセットに分けておき,rma()関数のdata=オプションでそれぞれのサブセットを指定することで分析が完了し,Eggar et al.(1997)が指摘する通りの結果が得られた。metaforパッケージは良くできていると思う。
- 人口学のパッケージについて(2011年3月9日)
- 拙作pyramidパッケージを使った人口ピラミッドの作り方について,web上で言及されていることに気付いた。ありがたいことだ。同じblogの次の記事では,demogRの生命表作成機能について触れられていたが,去年の人口学会のテーマセッション資料に書いた通り(この資料へのリンクは当時のメモからしか張っていなかった),生命表作成の関数を書くのはそんなに難しくないので,自作にチャレンジされると良いと思う。また,たぶんdemogRが消えたのは,人口学のパッケージの決定版ともいえるdemographyパッケージが去年の夏からCRANに入ったからではないかと思う(単なる想像だが,自分も細々と人口分析で使える関数群を書いていたのだけれども,demographyパッケージを見てからは開発意欲が衰えてしまった)。
- 実数の多倍長計算・表示について(2011年3月9日)
- 柏野さんがRでのpiの表示が普通にやると小数点以下16桁目から狂うことを書かれている。
- 確か多倍長演算ライブラリについて以前触れたなあと思ってメモを調べたら,gmpライブラリについて書いてあって,as.double.bigq(pi)ということはできるけれども,そもそもpiというオブジェクトの定義が3.141592653589793までしかないので,piというオブジェクトを使う限り,これ以上の精度は出ないのだった。
- しかしCRANのパッケージは奥が深くて,Rmpfr(R Multiple Precision Floating-Point Reliable)というパッケージをCRANからインストールして(普通にinstall.packages("Rmpfr",dep=TRUE)でOK),library(Rmpfr)としてロードすると,mpfr()という関数で高精度オブジェクトができ,そのまま計算ができるのだった。
- とくにpi,gamma,catalan,log2については,Const("pi",100)などとすれば高精度で計算してくれるのが便利だ。ちなみに,この結果はasin(mpfr(1,100))*2と一致するが,mpfr(pi,100)とは一致しない。つまり,mpfrになった値に関数を適用すると自動的に高精度計算になるが,逆では単なる型変換になってしまうので下位の桁は適当に補われるだけになることに注意が必要で,100桁のexp(1)が欲しい時は,mpfr(exp(1),100)ではなくて,exp(mpfr(1,100))でなくてはいけない。
- R-2.13.0リリース(2011年4月13日;●4月15日追記)
- Peter Dalgaardから,R-2.13.0がリリースされたというメールが流れた。
- これは"development release"で,数多くの新しい特徴を含み,大部分はマイナーだけれども2.12.2で出てしまった大きなバグも含む,数多くのバグフィックスもなされているとのこと。
- IQR()関数がquantile()に渡すためのtype=というオプションを備えたとか,chisq.test()関数が返すオブジェクトが標準化残差を含むようになったとか,Rの内部形式データファイルを明示的に扱えるsaveRDS()関数とreadRDS()関数ができたとか,factanal()関数が"promax"のような回転が使われた場合には回転行列を返すようになったとか,多くの変更点があるようだ。ミラーサイトに入ったら速攻でインストールしよう。
- (4月14日追記)台湾のミラーサイトに入ったのでダウンロードしてインストールしてみた。インストール時の使用言語でJapaneseを選ぶと途中から文字化けする現象は相変わらずなので,Englishを選ぶ必要がある。また,Windows2000のサポートは打ち切られたらしいが,現在使っているマシンのOSは全部XP Proだから,とりあえず個人的には問題ない。インストール終了後,スタートメニューからuninstall R-2.12.2を選び(なお,R-2.13.0以降,このスタートメニューのアンインストール用ショートカットは無くなり,たぶん「プログラムの追加と削除」からアンインストールすべきということになったようだ),残ったlibraryの中身をR-2.13.0のlibraryに追加移動してから,R-2.13.0を起動してupdate.packages(checkBuilt=TRUE,ask=FALSE)を実行することで,使っているパッケージのアップデートも完了する。本体はまだ兵庫教育大ミラーに入っていなかったが,パッケージは既に入っているようで,上手く行きそうだ。
- ●(4月15日追記)上記の手順で問題なくインストールは完了した。R-2.13.0ではcompilerライブラリが標準インストールされるようになったので,Rでシミュレーションに掲載してあるマラリア感染シミュレーションを使って試してみた。条件を変えるのは面倒なので,p=0.3,beta=0.7に固定し,乱数だけを変えて50回繰り返す操作を,(1)コンパイルなし,(2)1回のシミュレーションをする関数をlibrary(compiler); cse <- cmpfun(simexec)のようにバイトコンパイルし,simexec(0.3,0.7)の代わりにcse(0.3,0.7)を50回呼び出す,(3)(1)の全体をバイトコンパイル,(4)(2)の全体をバイトコンパイル,の4通りで比べてみた(コードはcompile-malsim.R。グラフィックウィンドウが4分割されてグラフが4回描画される。時間はsymtem.time()関数で計測した)。すると,(1)(3)に比べ(2)(4)が高速だが,(2)と(4)がほぼ同等という結果だった。このテストでは描画時間がボトルネックなので,それほど劇的な効果ではなかったが,目に見えて速くなったし,ほとんど手間はいらないし,得られた結果はまったく同じだったので,今後積極的に使ってみようと思う。
- 『Rパッケージガイドブック』刊行(2011年4月13日)
- 東京図書の編集の松永さんと筑波大の岡田さんから,『Rパッケージガイドブック』東京図書,ISBN 978-4-489-02097-1(Amazon | bk1)をご恵贈いただいた。買うつもりだったのでありがたい。
- 本書は,以前,やはり岡田さんの企画で作られ,ぼくも寄稿した『The R Book』同様,既にやりたいことが決まっている人向けというよりも,Rを使って何ができるのかという広がり・可能性を知りたい人に向いている。RjpWikiで執筆者が募集されてからほぼ1年で完成にこぎつけたのは凄いと思う。R本体の機能を概観するだけでも大変なのだけれども,パッケージときたら世界中のさまざまな分野の多様なニーズをもった人が別々に開発したものが何千も公開されているのだから,その全容を知ろうというのは無理だと思う。本書の狙いはパッケージの全体像を紹介するのではなく,日本でRのパッケージを開発したりバリバリ使っている人たちが,自分の使っているパッケージのセールスポイントをコンパクトにまとめた小論を,50本束ねて紹介することである。これだとパッケージの全容は当然わからないが,こういうことにも使えるパッケージがあるのか,という実例がある程度まとめて示されているので,パッケージとは何ぞや? という感覚をつかむのに向いていると思う。もちろん,ここに紹介されている50のパッケージのどれかを使いたい人にも役に立つだろう。
- ただ,説明がコンパクトにまとめられているので,多機能なパッケージについては,本書の説明だけでは紙幅が不足かなあと思われるものもあった(Rcmdrなどは独立した書籍がいくつも出ているようなパッケージだから,そもそも本書では取り上げられていないし,survivalのような多機能なパッケージを数ページで説明しきれるわけもない。これくらい書いてもごく一部なのだから)。将来的には,本書のようなものがある程度分野別に10パタンくらい提供され,それぞれの別冊として個別パッケージについての解説書がハンドブックとして入手できるような感じになれば便利だと思う。
- ただし,一時期かなり使われていたdemogRがdemographyのリリース後にはCRANから消えてしまうなど,パッケージは栄枯盛衰が激しいので,もしかすると書籍として整備するよりも,web上で使いやすいカタログサイトを作る方がいいかもしれない。
- fmsbパッケージをバージョンアップ(2011年5月7日)
- 作図依頼を受けたデータをレーダーチャート作成関数radarchart()に渡したところ,途中で止まってしまったので調べてみた。その結果,最初の軸の値が欠損値のときの例外処理で配列の添え字が0になってしまうことがあることが判明したので,そこを修正した。ついでなのでJvitalデータフレームに,2011年1月1日に公表されていた平成22年人口動態統計の年間推計値から,年次(YEAR)の末尾に2010を加え,粗出生率(CBR),粗死亡率(CDR),自然増加率(NIR),死産率(SBRPB),婚姻率(MR),離婚率(DR)の末尾にそれぞれの値を追加した。他の変数の末尾は未発表なのでNAを入れた。
- 以上2点の変更があったので,fmsbパッケージのバージョンを0.2から0.2.1に上げ,ドキュメントの関連部分も書き換えてから,R CMD check fmsbしたら無事に通った。そこで,R CMD build fmsbしたら,Windows XP Professionalのコマンドプロンプトでやっていたために,パス名(C:で始まる)がWindows形式だという警告メッセージが出たけれども,無事にfmsb_0.2.1.tar.gzが構築できた。ついでR CMD build --binary fmsbしたらzipも無事にできたが,--binaryはdeprecatedになったという警告メッセージが出た。調べてみたらR-2.13.0からそうなったようだ。今後はR CMD INSTALL --build fmsbとすることが推奨されるそうだ。やってみたら無事にfmsb_0.2.1.zipができた。これからCRANにsubmitする予定。
- 翌日無事にアクセプトされてCRAN上でも更新された。
- R-2.13.1リリース(2011年7月8日)
- R-2.13.1が予定通りリリースされた(リリースノート)。リリースノートをざっと読んだ感じだと,慌ててインストールしなくてもよさそうだ。
- 実は7月4日に届いたR-develメーリングリストのメールで,Prof. Brian Ripley大先生が,R-2.14.0の10月31日リリース予定と,このバージョンからはパッケージのすべてを動的にロードするようになること,それとも関係するがそれぞれのパッケージがNAMESPACEをもつように仕様変更すること(ない場合はデフォルトのNAMESPACEが自動的に付加されるが,現在NAMESPACEを用意していないパッケージ――全体の42%だそうだ――はNAMESPACEを作って含めることを推奨するのだそうだ。pyramidとfmsbにもNAMESPACEを用意するべきだろうか),R本体のコードがバイトコンパイルされた状態になること,などがアナウンスされていた。3ヶ月でそんなに大きく変わるなら,R-2.14.0まで(あるいはそれが安定するであろうR-2.14.1まで)アップデートしないのも選択肢の一つかもしれない。
- EZR(2011年7月14日)
- 自治医大さいたま医療センター血液科で開発されているEZR on Rcmdr(β版)は凄い試みだと思う。基本的にはRcmdrをベースにして,日本語メニューで医学統計で良く使われる処理を(オプションまで含めて)フルカスタマイズしたものといえる。ここまで作り込んであれば,医学系の普通の研究者や大学院生が使うには十分ではなかろうか。メタアナリシスなども組み込まれている。
- 32bit版Raを組み込むためのWindows版Rビルド(2011年8月22日)
- Ra拡張が,以前は32bit版Windowsでも動いたようだが,現在では64bit版しかバイナリが提供されないので,Rそのものをソースからビルドする必要に迫られた。以下Windows版Rをビルドする手順を記す。ただし,make manualsの途中で頓挫したので,ビルドそのものはできたが,インストールファイルはできていない。
- RtoolsをフルインストールするとできているC:\Rの中に,R-2.13.1.tar.gz(CRANからダウンロードする)をtar --no-same-owner -xvzfで展開する
- 予めR-2.13.1上にinstall.packages("jit",dep=TRUE)でjitを入れておき,そのディレクトリ("C:\Program Files\R\R-2.13.1\library\jit")をC:\R\src\libraryにコピーする
- tar -xvzfでra_1.3.0.tar.gz(http://www.milbo.users.sonic.net/ra/index.htmlからダウンロードする)をC:\Rに上書き展開する
- 環境変数TMPDIRを適当な書き込み可能なディレクトリにしておく必要があるので(それをやらないと途中までうまくいくが,baseパッケージをビルドするところで致命的エラーが出て止まってしまう),マイコンピュータのプロパティの詳細設定の環境変数のユーザ環境変数で新規ボタンをクリックし,TMPDIRを空き容量が大きいe:\tempに設定した(再起動が必要)
- C:\R\src\gnuwin32でコマンドプロンプトを開いて,make cleanしてからmake all recommendedする……数十分待ち
- pngとかjpegとかtiffといったビットマップ作成ライブラリはall recommendedには含まれていないので,make bitmapdllする
- recommendedなパッケージ群も含めてちゃんとビルドできたかチェックするには,make check-allする……5時間以上待ち(朝起きたら終わっていた。mgcvのドキュメントのクロスチェックのためのネットアクセスがうまくいかなかったらしく1件だけ警告が出ていたが,まあ問題なかろう)
- "C:\Program Files\R\R-2.13.1\library\jit"をC:\R\libraryにディレクトリごとコピーする(これでビルドされたRにjitがインストールされた状態になる)
- raがちゃんとできたかをチェックするために,ra\testsディレクトリに入り,..\..\bin\i386\Rterm --vanilla LANG=C LC_ALL=C <test-jit.R > test-jit.Rout 2>&1する(Raの説明テキストには..\..\bin\Rtermと書かれているが,R-2.13.1では32ビット版は..\..\bin\i386\Rterm.exeになることに注意。また,LANG=CとLC_ALL=Cをつけないと,メッセージが日本語版になってしまうので,次のdiffで余計な違いが報告されてうまくいかない)。
- diff test-jit.Rout.save test-jit.Routでビルドした日以外は差が無いことを確かめる(raのtarボールに入っているtest-jit.Rout.saveは英語版Rで実行された結果なので上述の注意が重要)
- pdf版のマニュアルはmake manualsで作れる。1878ページのpdfファイルができる。が,UseExternalXrefs絡みのエラーが出て終わってしまう。その前にC:\R\doc\manualでmake -f Makefile.win infoをやっておく必要があるのか……と思ってやったのだが,その後も状況は変わらず。このままではmake distributionも同じ所で止まるので,ここで頓挫中
- make distributionによりインストーラを作る(予めInno Setupをインストールしておく必要がある)
- ちなみに,jitの性能チェックもしてみたので,結果を書いておく。jit-check.Rを素のR-2.13.1で実行した結果がjit-check-with-R.outで,R-2.13.1+Ra-1.3.0で実行した結果がjit-check-with-Ra.outである。素のRではjit(1)とかjit(2)にすると若干遅くなるが,Raでは,確かに20倍くらいに高速化されている。普通の一重ループではjit(1)の方がjit(2)より速いようだ。しかし,バイナリコンパイルしてしまうと,Raの場合,jit(0)の時に高速化されるのはいいのだが,jit(1)やjit(2)では逆にかなり遅くなってしまうことがわかった。結果は全部正しく出ているけれども,このテストは先にやっておくべきだった。昨日投入したjobではjit(1)を含む関数をバイナリコンパイルして実行させていたので,逆に実行速度を落としてしまっていた(たぶん)。なお,もちろん,素のRの場合は,バイナリコンパイルした方が,しないよりずっと速くなっている。
- barplotの縦軸について(2011年10月12日のメモから)
- MDPhDコース学生のW君から,ylimを指定してもbarplotで描かれるY軸がbarの最大値より小さい場合がある問題(切りのいい数字までしか描かれないので)を解決する方法を質問された。最初はオプションまたは別パッケージでどうにかなるかと思い,gregmisc(またはgplot)のbarplot2関数やplotrixのbarp関数を調べてみたが,どれも同じだった。検索したところ,barplotCoveredという関数を定義して,Y軸が必ず最大値より大きいところまで描かれる方法を開発した方がいた。これはこれで1つの解決法なのだが,逆にあまりに軸が長すぎて格好悪い。そこで暫く考えてみた。問題の本質は,barplotでylimを指定すると,bar自体は正しくylimの範囲に収まるように描かれるが,Y軸が短くしか描画されないという点にあるので,例えば,dat <- c(10,20,161,35); names(dat) <- c("a","b","c","d"); barplot(dat,ylim=c(0,175)); axis(2,0:7*25)のようにすれば解決だろう。ちょっと面倒か。いや,むしろ後半はxpos <- barplot(dat,ylim=c(0,175),axes=FALSE); axis(2,0:7*25); axis(1,xpos,names(dat),lty=0)か。問題は,max(dat)が161のときに175まで25刻みの軸目盛を付けるという判断をどうやって自動化できるかだな。ついでに書いておくと,fmsbパッケージには多様な関数を入れてあるのだが,英語helpしか説明文が存在しないため,学生に紹介しづらい。折を見て日本語解説pdfを作ろうと思う(いつになるかわからないが,忘れないため書いておく→(追記)作成開始した)。
- R-2.14.0リリース(2011年10月31日のメモから)
- R 2.14.0 is releasedというメールがR-announceで流れてきた。予定通りだ。このバージョンから,すべてのパッケージが名前空間(namespace)を持たねばならなくなったのだけれども,ソースにない場合はインストール時に自動生成されるらしいので,pyramidとfmsbは慌ててバージョンアップしなくても大丈夫そうだ。なお,Rコードを含まない,データだけのパッケージは再インストールしなくてもいいが,それ以外の名前空間をもたないパッケージは,R-2.14.0で使うためにはlibraryディレクトリ内のコピーをしてupdate.packages()という方法ではなく,install.packages()で再インストールする必要があるというわけだ。むしろこの際,全部のパッケージを入れるのではなく,必要なものだけを入れ直す方がいいかもしれない。なお,現在やっている計算からすると,Raがこのバージョンにならないと,vaio-saにはインストールできないのだけれども,マルチコアでの並行動作をサポートするパッケージparallelというのが新たにできたとか,かなりいろいろな新機能や改善点があるので,なるべく早く入れたいところではある。
- 反復測定分散分析について(2011年11月20日のメモから)
- 講義資料として反復測定分散分析(Repeated Measures ANOVA)についての補足資料を作成した。Prof. John Foxがcarライブラリの中でAnova()関数にオプションとしてidataとかidesignとかを与えることでSphericity TestとかG-G補正とかいった計算ができるようにしてくれているのだが,サンプルサイズが繰り返し数より小さいとエラーが起こる(ある意味当然のような気もするが)ので,『SASによる実験データの解析』に載っている例題が計算できなくて困った。webを検索していたら,Dr. Peter Dalgaardがanova.mlm()でなら計算できると説明していて,確かにそれで問題が解決した。Anova()におけるRepeated Measures ANOVAの実装方法を根本的に変えないと,たぶんこの問題には対処できないのだろう。
- R本新刊メモ(2011年12月6日のメモから)
- Matloff R (2011) "The Art of R Programming", No Starch Press, ISBX978-1-59327-384-2がAmazonから届いた。カバーデザインがすばらしい。"Chapter 8: Doing Math and Simulations in R"はそれほど濃くなくて(パッケージ紹介などは参考になったが),当サイト内のRで数学をやってみるとかRでシミュレーション(ちょっと古いが)の方が濃いくらいだったが,"Chapter 13: Debugging"以降,"Chapter 14: Performance Enhancement: Speed and Memory","Chapter 15: Interfacing R to Other Languages","Chapter 16: Parallel R"は,計算の高速化が必要な状況にある現在,とても役に立ちそうだ。
- R降臨暦(2011年12月12日のメモから)
- R Advent Calender 2011は,「R降臨暦」という名前の通り,Rをネタにしたブログを交替で綴っていく試みなわけだが,どれもレベルが高い。統数研での懇親会のときにお誘いいただいてメールも受け取ったのだけれども,忙しかったのとATNDへユーザ登録するのが心理的敷居が高かったのとで放置していたら25人枠が埋まってしまったのだった。しかし読んでいるだけでも興味深い。
- fmsb-0.2.4とか(2011年12月18日)
- fmsbパッケージを0.2.4に更新した。0.2.1に日本の人口動態データの残りを追加し,mhchart()関数を追加し,NAMESPACEを追加した0.2.2が12月11日で,2010年センサスデータを追加した0.2.3,NAMESPACEの書き方の誤りを修正した0.2.4になるまで1週間しかなかったが,その都度CRANに登録してしまったのは間抜けな更新の仕方で申し訳なかった。
- 英文と和文の両方を含むマニュアルページを作成中。
- EZR for Rcmdr 0.99(2011年12月21日)
- 自治医大さいたま医療センターの方からメールがあり,EZR on Rcmdrが0.99で英文に暫定対応したことを教えていただいた。これは留学生に薦めるのにいいかも。とりあえず全てが英語仕様になっているDellのノートマシンでの動作確認をしてからだな。
- fmsb-0.3.0(2011年12月28日)
- 地球研での発表とか人口学の講義などでグラフを示すために使ったデータや作った関数を整理してRのパッケージに入れることにした。生命表もHuman Mortality Databaseから入手できるものは独自の補正が施されたもので,それはそれでいいのだが,日本政府が公式に発表している完全生命表も使えた方がいいので,それも入れることにした。
- 将来的にはRで人口分析をする入門書を書こうと思っていて,それ専用のパッケージを作ってもいいのだけれども,fmsbに組み込んでバージョンアップし,0.3.0として,12月28日にCRANにsubmitした。
- R-2.14.1リリースなど(2012年1月4日)
- 書き忘れていたが,予定通り2011年12月22日付で,R-2.14.1がリリースされていた。メンテナンスリリースなので,とくに大きな変化はないようだ。
- fmsbのマニュアルページからリンクしてある日本の国勢調査データの説明の下の方に,人口ピラミッドの描かせ方や,単純な人口予測をするためのコードなどを掲載した。
- 『R言語逆引きハンドブック』(2012年1月25日のメモから)
- 石田基広先生の最新刊『R言語逆引きハンドブック』C&R研究所,ISBN 978-4-86354-093-4(Amazon | bk1 | e-hon)が届いた。いつもご恵贈くださり,ありがとうございます>石田先生。
- この本はやりたい内容ごとに下記のように章立ててRの関数がまとめられており,ここが知りたいというポイントを絞って探して読めるように作られている。
- CHAPTER 01 R言語の基礎
- CHAPTER 02 オブジェクトの基礎
- CHAPTER 03 ベクトルの基礎
- CHAPTER 04 ベクトルの操作
- CHAPTER 05 行列
- CHAPTER 06 データフレーム
- CHAPTER 07 リスト/配列/表
- CHAPTER 08 関数の作成
- CHAPTER 09 ファイル/データベース
- CHAPTER 10 基本統計解析
- CHAPTER 11 応用統計解析
- CHAPTER 12 基本グラフィックス
- CHAPTER 13 多変量グラフィックス
- CHAPTER 14 Rの応用
- ざっと見た感じ,とても見やすく作られていて,内容も濃い本だと思った。例えば,Excel形式ファイルにデータを保存するために64ビット版だとxlsReadWriteパッケージが使えないのでどうしようと思っていたが,ファイル関係だからCHAPTER 09を見ていくとExcelファイルについての説明がいくつか載っていて,最後にLinux環境でExcelなしでもExcelファイルが作れるパッケージとして紹介されていたXLConnectが見事に使えた(ただしインストールはdep=TRUEにしなくてはいけないがそうなっていなかったし,ワークシートにデータを書き込む関数writeNamedRegion()関数が実行例に含まれていなかったので,使うのに少し手間取ったが)。大まかなやりたいことがわかっているときに,基本関数だけでは到達し得ない情報まで書かれているのは,とても役に立つ。4,600円+税とちょっと値が張るが,663ページもある大著にしては頑張った値付けだと思う。
- R-2.14.2リリース(2012年2月29日;3月15日追記)
- R-announceメーリングリストで,2.14系の最終版となるR-2.14.2のリリースのアナウンスが流れてきた。しかし,そのメールに書かれていた,"This release also marks the 3rd anniversary of R-1.0.0."ってのは,どういう意味なんだろう? R-1.0.0なんて,3年なんてものではなくて,ずっと前にリリースされた……と考えて,やっと今日が閏日であったことを思い出した。つまり12年前ということか。長いような短いような12年だった。
- (2012年3月15日追記)2.14.1まで続いてきた,日本語Windows環境で,インストール時使用言語を日本語にすると,カスタムインストールなどの選択肢が文字化けするという現象が直っていた。素晴らしい。Windows-specific changesをみると,bug fix PR#14816の副作用で直ったようだ。UNICODE版Inno SetupがメッセージにBOMを要求するという問題だったようだ。
- サイト移転(2012年3月5日)
- 都合により,このページは,http://minato.sip21c.org/swtips/R.htmlに移転します。
- fmsbとpyramidパッケージを更新(2012年3月15日)
- サイト移転にともない,パッケージ内のURLを書き換えたため,パッケージをバージョンアップした。
- R-2.15.0リリース(2012年3月30日)
- 予定通りにR-2.15.0がリリースされた。リリースノートにある通り,データのみのパッケージにも名前空間が必要になったとか,pdf()関数がパイプ処理を許すようになったとか,legend()関数にtext.fontというオプションができたとか,summary()関数の動作が少し変わって,数値変数についてのNAの数が実数ではなく整数として表示されるようになったとか,多数の変更点はあるが,とりあえずpyramidパッケージもfmsbパッケージも書き換える必要は無いようだ。
- EZR本出版(2012年4月14日)
- 神田善伸(著)『EZRでやさしく学ぶ統計学~EBMの実践から臨床研究まで~』中外医学社,2012年4月刊,ISBN 978-4-498-10900-1(Amazon | bk1 | e-hon)をご恵贈いただいた。
- EZRはRcmdrのプラグインとしてではなく,Rcmdr自体を大幅に改造して作られていて,たぶん分離はできないと思う。少なくともWindows版は,R本体まで含んだインストーラになっていて(だから,この形ではたぶんCRANには入らないだろう),作業ディレクトリの設定なども含めて,とりあえずデフォルトのままで良ければ,何も考えなくてもインストールが完了し,起動アイコンをダブルクリックするだけでR本体と同時にEZRまで起動するように作られている。元々のRcmdrのメニューも「標準メニュー」として残っているが,通常は「アクティブデータセット」というメニューでデータハンドリングし,「グラフ」で様々なグラフを作り,「統計解析」というメニューで日常的に使う解析はほぼ網羅された医学統計解析ができるようになっているので,操作体系はRcmdrからほぼ独立している。本書はたんなる操作マニュアルではなく,解析方法の仕組みや意味まで書かれているので,医学統計演習の教科書として使えると思う。学生に買わせるにはやや値段は高めだが,このボリュームなら仕方ないところか。
- R-2.15.1リリース(2012年6月23日;25日,26日追記)
- ■今回も予定通りにR-2.15.1がリリースされた。バグフィックス主体のメンテナンスリリースのはずだが,リリースノートを見ると,かなり多くの変更点があるようだ。
- ■Windowsバイナリは23日のうちにhyogoミラーからダウンロードできたので,インストールしてから,アンインストールした旧版のディレクトリに残っているlibraryの中身を全コピーし,update.packages(checkBuilt=TRUE, ask=FALSE)としてライブラリを更新したところ,何の問題も無くスムーズに完了した。起動してみて知ったが,R-2.15.1のコードネームは「ローストしたマシュマロ」であった。
- ■RjpWikiのトップページにコメントされたリンク先は,Rbloggersに入っているRevolutionsのエントリなのだが,大変興味深いものだったので,以下,ざっと内容をメモしておく。先日のuse!Rでプレゼンされた,GoogleのRユーザ(500人以上!)が3年以上使ってきたdataframeパッケージ(開発者がGoogleのTim Hesterberg)は,インストールするとdata.frame()などの関数を置き換え,Rが内部で作るデータフレームのコピー数を減らすことによって,Rを高速化するもので,R-2.14.2にインストールした場合だと,データフレームを作ったり列の部分操作をする際には21%,行の部分操作では14%の高速化になる。R-2.15.1では,Core TeamのLuke Tierneyがこのデータフレーム操作法を取り入れた(一時的な内部コピー作成数を減らし,メモリの使い方を改善した)ので,形の上ではマイナーリビジョンだが,基本操作部分が効率化され,かなり多くの関数のパフォーマンスが改善したはずだという。Revolutionsのエントリでは,検証コメントが求められているので,大規模データを扱ったりしていて高速化を実感できた方は,コメントしてみてはいかがだろうか。
- ■(実験結果)マラリア伝播シミュレーションコードで検証した結果は以下の通り。無駄な代入やループが多いコードではあるが,確かに高速になっているようだ(ちなみに,plot()とlines()で描いていたのをmatplot()で一気に描かせるようにしたコードでも実行時間はほぼ不変だった)。なお,3番目の(with jit)では,simexec()関数のfor()ループの前後でjit(1),jit(0)した。これはさすがに速いが,jitのON/OFFのタイミングによって逆に遅くなったりすることがあるし,ベースのRが2.13.1というのが残念な点だ。また,4番目のR-2.14.1はEZRとともに配布されているものである。
Executed platform Elapsed time (sec) User Sys Total R version 2.13.1 (2011-07-08), x86_64-pc-mingw32/x64 (64-bit) 4.26 0.00 4.26 R version 2.13.1 (2011-08-27 Ra 1.3.1), x86_64-pc-mingw32/x64 (64-bit) 3.98 0.02 4.12 R version 2.13.1 (2011-08-27 Ra 1.3.1), x86_64-pc-mingw32/x64 (64-bit), (with jit) 3.28 0.02 3.29 R version 2.14.1 (2011-12-22), x86_64-pc-mingw32/x64 (64-bit) 4.01 0.02 4.25 R version 2.15.1 (2012-06-22) -- "Roasted Marshmallows", x86_64-pc-mingw32/x64 (64-bit) 3.60 0.02 3.62 - R-2.15.2リリースなど(2012年11月2日)
- ■8月3日付けで鵯記にはメモしていたことだが,群馬大学大学院医学系研究科の統計演習のため,群馬大学の演習室でEZR on Rcmdr英語版を使って統計解析をする際に参照できる資料pdfを公開した。今年は英語だけで講義したので,資料自体英語版のみ作成した。EZRの操作を留学生に教えるには役に立つかもしれない(群馬大学演習室ローカルだったり,その後修正されたEZRのtypoについての記述が入っていたりするが)。なお,日本語が読める人がEZRを使う場合は,この資料なんかではなく,開発者である神田先生の本『EZRでやさしく学ぶ統計学~EBMの実践から臨床研究まで~』中外医学社,ISBN 978-4-498-10900-1(Amazon | bk1 | e-hon)を読むことを強くお薦めする。
- ■8月17日付けで鵯記にはメモしていたことだが,C.P.ロバート,G.カセーラ(著),石田基広,石田和枝(訳)『Rによるモンテカルロ法入門』丸善,ISBN 978-4-621-06527-3(Amazon | bk1 | e-hon)をご恵贈いただいた。いつもありがとうございます>石田先生。
- ■10月19日付けで鵯記にはメモしていたことだが,たぶん日本で一番多くのR本を出版されている石田基広先生から,新刊『Rで学ぶデータ・プログラミング入門:RStudioを活用する』共立出版,ISBN 978-4-320-11029-8(Amazon | bk1 | e-hon)をご恵贈頂いた。いつもありがたいことだ。本書はRcmdrと並び称されるR用のGUI環境であるR Studioの(まだ数少ない)日本語説明書という側面ももつが,データ構造やデータ操作の詳細にかなり紙幅が費やされており,狙いどころが明確だと思う。
- ■予告通り10月26日にR-2.15.2がリリースされた。コードネームが"trick or treat"というのは,もちろん時節柄ハロウィーンに引っかけているのだろう。クッキーの代わりにRを上げようってことか。
- R研究集会2012(2012年12月1日)
- ■統計数理研究所で表記研究会(RjpWikiでのアナウンスとフォローアップ)が行われた。詳細はhttp://minato.sip21c.org/RWS2012/(メモを参照されたい)。
- ■ぼくはR本体をそのまま使うことが多いのだが,現在では,多種多様なGUIの統合環境(リンク先はR GUI ProjectsというSciViews内のプロジェクトサイト)が開発・提供されている。今年の研究集会のスペシャルゲストとして11月29日~30日にご講演くださったProf. John Foxが開発したRcmdrや,それを自治医科大学の神田善伸先生が医学統計向けにカスタマイズしたEZRのように(弘前大学の対馬先生が公開されている改変Rコマンダーもそうだ)メニューから選んで操作するものに加え,データ操作のしやすさを主眼にしたRzパッケージもあるし,デバッグ機能やコーディング補助機能を充実させたGUI環境がいくつも開発され,広まっていることを実感した。岡田さんくらいRStudioを使いこなすと生産性が上がりそうな気がするし,もうすぐ大幅に機能強化した待望のVersion 2が公開されるR Analytic Flowへの期待も大きい(R Analytic FlowはSciViewsのサイトのOverviewでも取り上げられていたが,ライバルはorangeか)。
- R AnalyticFlow 2.0リリース(2012年12月17日)
- ■R研究集会の2012年会合で発表され,リリースが待ち望まれていたR AnalyticFlow 2.0だが,13日にリリースされた。Windows用の64ビット版をインストールして少し使ってみた感じでは,最大の特徴と言える,フローチャート形式でコーディングできる点に加え,select.list()の動作が素のRと同じという点はRStudioより優れているし,コードの編集は常用しているエディタが開く(たぶん,*.Rに関連づけされているアプリケーションが開く)のも利点だと感じた。プロジェクト管理方式やパッケージビルドの容易さではRStudioに一日の長があるかなあ,とは思うが,普通にコーディングする分には,これも便利なツールだと感じた。ありがとうございます>ef-prime様。
- EZRがRcmdrPluginとなってCRANに登録されたこと(2013年1月8日)
- ■自治医大の神田先生が医学統計用にRcmdrを大幅にカスタマイズ&機能追加して作られたEZRは,神田先生ご自身によってBone Marrow TransplantationというJournalに英文での紹介論文が書かれ(オープンアクセスなのでリンク先は当該論文のpdf),医学統計の世界では国際的に普及するポテンシャルをもっていると思うが,これまではR本体を含めたバイナリパッケージという形でのインストールが標準だったので,ベースにしているRやRcmdrのバージョンが最新でないという問題があった。
- ■年末のR研究集会でProf. John Foxにお会いした時に,EZRの話をしたら,それならRcmdrPluginにすればいいんじゃないかと神田先生に伝えて欲しいと言われた。仲介したところ,お二人の間でとんとん拍子に話が進み,1ヶ月も経たないうちにRcmdrPlugin.EZRが誕生し,1月8日にはCRANで公開された。実に素晴らしい。
- ■1月2日に入ったニュースにも触れておこう。R-annouceメーリングリストで,Peter Dalgaard師から流れたメールによると,Rの次期バージョンを3.0,0と予告していたが,そのリリース予定は4月1日であり,1ヶ月前に2.15.3をリリースする予定になったとのこと。Rにおけるメジャーバージョンアップは機能が大幅に増えた時というよりも,コードが十分に熟成したときに行うのだそうで,1.0.0はフル機能実装の統計ソフトとして十分な安定性に到達したと判断した時,2.0.0はSweaveを含むいくつかの大きな新機能実装に加え,メモリ管理サブシステムを強化した後で,今度の3.0.0は,2^31-1より長いベクトルを扱えるようになったことや,すべてのプラットフォームで64ビットをサポートするようになったこと,並列処理のサポート,Matrixパッケージ等々により,新しいレベルに到達したと判断したからということだ。おそらく2^31-1より長いベクトルを扱えることは,ビッグデータ処理に不可欠であろうから,この判断はもっともだと思う。
- ■1月7日に,fmsbライブラリに入れてあるレーダーチャート描画関数radarchart()について,多角形内部を斜線で塗りつぶしたいという要望が海外からあった。polygon()関数の引数として元々density=NULLとcol=NAがあり,これらを適当な値にするだけで実現できたので,関連ドキュメントも更新してfmsbを0.3.6にした。0.3.5からほぼ1ヶ月経ったから許してもらえるだろう(アップデートの頻度については,CRAN Repository Policyに,安定するまでの最初の数回を除けば"no more than every 1-2 months" seems appropriate.と書かれているように,あまりに頻繁なのは宜しくないとされているのだ)。1月8日にCRANにsubmitしたところ,即日掲載されたようだ。
- fmsbを0.3.7に更新したことなど(2013年2月11日)
- ■radarchart()関数で最小値が中心の1点に揃うようにしたいという要望メールが来たので,centerzeroというオプションを追加した(デフォルトはFALSEなので,オプションを付けなければ動作は不変)。また,Rothman KJ (2012) Epidemiology: An Introduction. 2nd Ed.を参照し,rateratio(),ratedifference(),riskdifference()という3つの関数を追加し,fmsbを0.3.7にアップデートした。CRANにアップロードしたら即日掲載されたようだ。
- ■CRANからインストールできるRcmdrの最新版は1.9-5だが,R-Forgeでの最新版は1.9-6だし,それとは別にRcmdr2というものが開発中だった。大きく変わるんだろうか。
- ■三重大学の奥村先生がRでExcelのデータを読む方法というページを公開された。Excelも入っている環境であれば,Windowsでは一番簡単なのはclipboard経由だと思うが,奥村先生が紹介されている方法はExcelが無くても使えるのが強みだ。
- 都道府県別生命表で発表されたデータを図示するためにfmsbを0.3.8に更新(2013年3月1日)
- ■fmsbライブラリに入れてあるradarchart()関数は,こころのチェックシートの結果を返すために群大にいたときに開発したのが原型だが,その後,世界中からやってきた意見を取り入れて,比較的頻繁に機能追加している。今回は,眠っている間に,わかりやすい軸ラベルを付けたいという要望がメールで届いていたのだが,現在のところ,変数名をそのまま軸ラベルに使う仕様なので,例えばスペースや改行を含む軸ラベルを付けたければ,パワーポイントなどに貼り付けてから編集するしかない。たぶん簡単に改良できるだろうと思ってやってみたら,コードは30分でできたのだが,ドキュメントの方を直すのは意外に大変だった。
- ■要は,新しいオプションとしてvlabels,caxislabels,paxislabels(どれもデフォルトはNULL)を追加し,is.null()がTRUEなら従来通りのラベルを付け,FALSEならそれぞれのtext()に与えていた文字列を,このオプションで与える文字列に置き換えるだけのこと。CRANにsubmitするにはRcheckを通らなくてはいけないので,文法エラーなどは無いことが確認できるし,radarchart()のような簡単な描画関数の場合は,実際に動作させてみればバグってないか一目でわかるのが楽だ。結局,バグ取りを済ませてCRANにsubmitし,マニュアルページを更新したら11:30を過ぎていた。
- ■CRANをチェックしたら,2月26日付けでEZRがバージョンアップされていた。以前と違ってパッケージになっているので,update.packages(ask=FALSE, checkBuilt=TRUE, dep=TRUE)でアップデートできて楽だ。
- ■ちなみに,都道府県別生命表のページからダウンロードしたExcelファイルからデータを取り出して作図する具体的な方法は,「都道府県別生命表掲載データからの作図法(How to make charts by prefecture data)」というページにまとめたので,詳しくはそちらを参照されたい。
- R-2.15.3リリース(2013年3月1日)
- ■かねて予告されていた通り,R-2.15.3がリリースされた(R-announceでPeter Dalgaardからのメールも読めるが,このR-bloggersの記事の方が見やすいので,こっちをリンクしておく)。
- ■4月になるとR-3.0.0がリリースされることになっているので,これが最後のバージョン2系のリリースとなる。細かい改良がほとんどのようだ。例えば,最初の改良点"lgamma(x) for very small x (in the denormalized range) is no longer Inf with a warning."は,これまでlgamma(1e-307)は706.8936を返すけれどもlgamma(1e-308)が警告メッセージとともにInfを返していたのが,1e-308よりゼロに近い値でも数値を返すようになったということか。Windowsユーザにとっては,Windows環境でも十分にRAMを積んでいれば,64ビット版ではMacOSやLinuxと同様,R_allocが32GBを確保できるようになったことは大きいかもしれない。バグフィックスでqt(1e-12,1.2)がNaNを返していたのを修正したとあるが,自由度1.2のt分布ってどういう場合に意味があるのか想像できないくらいレアケースだと思う。良く見つけたな,というレベルのバグ。
- 津田メルマガにおけるRの紹介記事(2013年3月1日)
- ■特別企画:インターネット世論調査はどうあるべきか?(津田大介の「メディアの現場」Vol.66 より)で,RjpWikiと,Rを使ったゼゼヒヒのコメントの分析が紹介されていたので,RjpWikiのトップページに書き込んできた。
- ■いい記事なんだが,「しかし現在は、R Commander [*22] やR Studio、Rz [*23] 、R Excel [*24] などといった、Rの利用環境を向上させるツールも開発されるようになっている」という部分,R StudioではなくてRStudioなので念のため。あと,ここまで書くなら,EZRにも触れて欲しかったところ。なお,当初この記事では岡田昌史さんの肩書きが間違って記載されていたが,ご本人からの指摘により,現在は修正されている。
- 日本の人口データを楽に作図したい方へ(2013年3月11日)
- ■公務員が公開するネ申Excelが日本の生産性を落としている話の最初の方の派生tweetとして,@tetsutarouさんがe-Statで公開されているExcelファイルから人口ピラミッドを描こうとした時の落胆を表明されていたので,以下をtweetした。
「国勢調査人口なら数値としてRで使えるように勝手に変換してパッケージ化しています。2010年なら,library(fmsb); library(pyramid); pyramids(Jpopl$M2010, Jpopl$F2010)」
「(承前)もう少し見栄えを良くするには,最後をpyramids(Jpopl$M2010/1000, Jpopl$F2010/1000, Jpopl$Age, Laxis=0:6*200, Cstep=10, main="日本の人口構造(2010年,単位:千人)")」
- ■fmsbパッケージには国勢調査人口Jpoplだけでなく,人口動態統計データJvitalや年齢別出生率データJfertも単純な数値データとして入れてある。他の人が自分と同じ苦労をしなくても済むようにしたくてやっているのだが,本当は元データ自体を余計な空白や文字列を入れずに作ってくれたら,こんな風にパッケージに入れる必要すらなくなるわけで,将来的にはそうなるといいなあと思っている。
- ■(以下余談)そういえば,『Rで学ぶ人口統計解析の基礎』(仮題)という本を書き始めてから数年たつが,暇が無くていつ完成するか見えない。先日久々にファイルを開いたら,最初の頃に書いたことが古すぎて書き直す必要があった。せっかく4月から大学院で人口学の講義をすることにしたので,この際,ついでにテキストも完成させよう。問題は,英語でやる講義なので,テキストも英語で書かねばならないということだ。先に英語で書いてから和訳すればいいのか? とも思うが,昨年の夏に群大で非常勤でやった統計演習のテキストもそのつもりだったのに,和訳版は作らないままになってしまっている。つまり,問題は,先に英語で書くと,個人的には和訳するメリットが皆無なので(院生は英語くらい読めと思うし),結局は和訳しないままに終わってしまうことなんだよなあ。
- お薦めパッケージなど(2013年3月22日)
- ■RでMicrosoft Excelのファイルを読むためのパッケージにはWindowsだけのものとか32bitのみのものもあるが,XLConnectはWin/Linux/MacOS全部で32/64bit両対応とのこと。
- ■たけしょうのRTで,R-2.1.5.2版のWriting R Extensionsの邦訳をして公開された方がいることを知った。
- R-3.0.0リリース(2013年4月5日)
- ■4月3日に久々のメジャーバージョンアップとなるR-3.0.0(コード名:Masked Marvel)がリリースされ(詳細はkohskeさんが公開されたNEWSの日本語訳参照),4月4日には統数研ミラーにWindowsバイナリが入ったので,インストールしてみた。
- ■R-3.0.0本体のインストールはこれまで通り,CRANミラーからR-3.0.0-win.exeをダウンロードしてダブルクリックして実行,適当な方を選んでいくだけ(相変わらずデフォルトだとMDIでRcmdrやEZRに向かないので,オプション選択のときYesにしてSDIを指定する)で完了する。これまで通り旧バージョンは残るので併用可能なのは,ある意味利点だが,不要ならWindowsのコントロールパネルのプログラムの管理のところからアンインストールしなくてはならない。なお,コマンドプロンプトなどから直接Rtermを呼び出すために必要なPath(環境変数の)の設定などは,自動では更新されない。これもこれまで通り。
- ■追加パッケージは,新規インストールすることとされているので,マイナーバージョンアップの時にこれまでやってきたような,Program FilesのRの旧バージョンのディレクトリのlibrary(アンインストールした後でも残っている)をコピーしてから新しいバージョンのRを起動してupdate.packages(checkBuilt=TRUE, ask=FALSE)というやり方はしなかった。Kazuki Yoshidaさんが書かれている,旧バージョン上でinstalled.packages()を使って既インストールパッケージリストを取得し,R-3.0.0にデフォルトで入っているパッケージとの差分リストを取ってインストールさせる方法もあるが,既に使わないパッケージも多いので,この際,日常的に使っているパッケージだけのリストを作って,source("http://minato.sip21c.org/swtips/instmyusuallibs.R", encoding="UTF-8")で自動インストールさせた。RcmdrやEZR on Rcmdr(RcmdrPlugin.EZRとして)を含め,すべてエラーなくインストールできたし,ちょっと試してみた限りでは無事に動作した。
- ■Windows上でのパッケージ開発やソースコードからのRのbuildに必要なソフト群であるRtoolsもR-3.0.0用にはバージョンアップが必要で,CRANミラーからRtools30.exeをダウンロードしてインストールしなくてはいけない。これはダブルクリックするだけで上書きインストールされ,Pathを含む環境変数も書き換わるが,ぼくの環境ではPathの途中にあったRtools関係のPathのチェックが不十分で,重複してしまった(不都合はないが)。
- ■R Consoleの代わりにGUIフロントエンドとして使える,RAnalytic Flowは,既に入っていた2.0.0を起動したらRが存在するパスの変更を求められ,変更した後で起動シークエンスに入るとJavaJDパッケージのインストールを求められるので,ともに普通に済ませると正常動作した。2.0.1が公開されているという情報も表示されたので,ダウンロードしてダブルクリックしたら,普通に上書きインストールできた。
- ■パッケージ作成には非常に便利なGUIフロントエンドであるRStudioだが,これまで入れていたバージョンをそのまま使おうとしたらfatal errorが出て起動しなかった。0.97は最新のはずと思って,次のバージョンが出るまで待つしか無いかと諦めかけたが,柏野さんがtwitterで最新版なら動作するという情報をくださったので,改めてRStudioのサイトに行って最新版をダウンロードしてインストールしたら無事に動作した。0.97だから最新版だと思っていたが,どうやらこれまで使っていたのは0.97.248で,最新は0.97.336なのだった。3月22日付けで公開されていた。
- R-3.0.1リリース(2013年5月18日)
- ■一昨日だったと思うが,R-3.0.1(コード名:Good sports)がリリースされた。メンテナンスリリースとはいえ,R-3.0.0のリリースから約1ヶ月で次のリリースとは早いなあ。
- ■ついでに,この1ヶ月の間にメモしたR関係記事も掲載しておく。
- 裏RjpWikiさんがoneway.test()推奨のブログ記事を書かれたことを,多くのRユーザがtweetしていたので,「拙著『Rによる保健医療データ解析演習』http://minato.sip21c.org/msb/medstatbook.pdfp.102に書きましたが,青木先生がシミュレーションでoneway.testの優位性を示しています。http://minato.sip21c.org/medstat/it2011-07t.htmlではcarのAnovaも紹介」とtweetした。日本の統計解析ユーザにとって,青木先生がされている貢献は計り知れないくらい大きい。(4月24日)
- 三中さんのtweetで知った,非線形の関係も含めて2つの量的変数間の関連性を検討できるMICという指標と,それを計算するためのRパッケージであるminervaについての,林さんのブログ記事と,hiroki itoさんのブログ記事は大変興味深い。やっぱりRは凄いと思う。(5月1日)
- 何日か前にtweetしたが,同じものについて2つの方法で測定した時の一致具合を調べるための標準的な方法として知られるBland-Altmanプロットを行う関数BA.plot()が,Epiパッケージの開発で知られるCarstensenらによって開発された,MethCompパッケージに入っている。以前存在を知ったときより,大幅に機能が増えていた。(5月19日)
- fmsbパッケージを0.3.9に更新など(2013年6月18日)
- ■fmsbパッケージだが,人口学の講義をしていて,Jvitalに妊産婦死亡が入っていなかったことに気づいたので追加して,バージョン0.3.9としてCRANにアップロードした。ついでにhtml版マニュアルの人口分析関連部分に日本語の説明を付けた。
- ■Dr. Bendix CarstensenのMethCompパッケージがR-3.0.1で動かない問題は,先週行われたショートコースで,パッケージメインテナのDr. Carstensenが使うのに困ったのであろう,対応したバージョン1.22をリリースしてくれた。6月19日現在,まだCRANには入っていないが,リンク先からzipやtar.gzをダウンロードすれば,ローカルからインストールできる。BA.plotがR-3.0.1でも使えるようになった(example(BA.plot)すると,最後にエラーが出るが,プロットには支障ない)。
- fmsbパッケージを0.4.0に更新など(2013年6月29日)
- ■人口学の講義のおかげでfmsbパッケージへの機能追加が増えていく。今回はlifetable()関数でaxとnを自由に設定できるように機能追加した。下位互換性を保ちながら機能追加するという原則にしているので,整合性を取るのがなかなか難しい。なんとか1日でアップデートが完了し,CRANにsubmitしてメール連絡したら,20分で"Thanks, on CRAN now"という返事が来た。素早い。Windows用のzipファイルが作られ,ミラーサイトに行き渡るには,その後2日程度かかったと思う。
- ■一度別の方法でインストールしてしまうと,update.packages(checkBuilt=TRUE, ask=FALSE)ではアップデートできなくなってしまう(警告が出る)ので,今回,開発中にアップデートせざるを得なかったfmsbと,CRANでないところからダウンロードしてzipからインストールしたforecastとMethCompを,install.packages()し直してみた。
- ■Windows環境の場合,*.RをRstudioに関連づけしておくと,Explorerなどで*.RをダブルクリックするだけでRstudioが起動し,*.Rが内蔵エディタに読み込まれた状態になって,すぐに編集できる。この際,とくに設定していない限り,作業フォルダは*.Rがあったフォルダになるのが便利だ。
- ピアソン桐原の技術書販売停止への対応(2013年8月9日)
- ■桐原書店からのニュースリリースでは曖昧なのだが,当初ピアソン・エデュケーションから刊行された『Rによる統計解析の基礎』(2003年)(正誤表),『Rによる保健医療データ解析演習』(2007)は,ピアソンの桐原書店との経営統合によりピアソン桐原から販売されてきたところ,今度は出版部門が切り離されて桐原書店として独立することになり,その際,コンピュータ関連書籍の刊行を全部廃止することになった,ということだ。
- ■同じシリーズ本(Computer in Education and Research)なので,2冊とも現在出回っている分しか入手できないことになる。編集の方からは引受先の出版社を探すように勧めていただいたが,どちらも情報として古くなっている部分も多く,全面的に書き直す時間は取れないし,草稿pdfは当時からずっと公開したままなので(それぞれの本のリンク先参照),必要な方は,とりあえず,それらのダウンロードで対応していただきたい。もっとも,別の角度から考えてみれば,これは公開版pdfの内容をアップデートするチャンスかもしれないが。
- R-3.0.2リリースなど(2013年10月7日)
- ■2013年9月25日付けで,予定通りに,R-3.0.2(コード名:Frisbee Sailing)がリリースされた。新しい特徴は,NEWSファイルの再構成,sum()関数が2の53乗を超えるようなレアケースでも正確な結果を返すようになったこと,str()関数の高速化など。
- ■徳島大学の石田基広先生からご恵贈頂いた(ありがとうございます)『とある弁当屋の設計技師(データサイエンティスト):データ分析のはじめかた』共立出版を読了したので,書評を書いた。サポートサイトには,Rのインストール方法を始めとして,役に立つ情報が多い。必要なコードをパッケージの形でインストールできるようにしてくださっているのが素晴らしいと思う(さすがにCRANではなく,repos="http://rmecab.jp/R"オプションで石田先生のサイトからのインストールだが)。
- 第8回R研究集会(2013年12月3日)
- ■第8回R研究集会に参加・発表したので日記にメモを掲載した。ここにも採録しておく。
- □合崎英男さんによる「RによるBest-Worst Scaling」。support.BWSというパッケージを開発しCRANで公開されている。maximum difference scalingという言い方もあるそうだ。BWSはコンジョイント分析などでも使われる,複数の項目からの選択の手法。(例)澤田ら(2010)国産牛の飼料自給率向上の利点に対する消費者評価 *国際価格,安定供給,エサ安心,環境負荷,CO2削減,低価格の6項目から実験計画により5項目を取り出す。最も重視する項目と重視しない項目のペアを選んで貰うことを繰り返す。他にもcorrosdesとかDoE.baseとかsurvivalといったパッケージを要する。最近だとmlogitというパッケージを使うと離散選択モデルが使える。crossdesパッケージはBIBD (釣り合い型不完備計画)向け。例として紹介されたのは,support.BWSパッケージのexampleのres2のデータをただの記号ではなく野菜名に変えたもの。(質疑から)BWSは個々の項目を評定するのに比べ,「みんないい」とか「みんな中間」といった回答になりにくいので,相対的重要性を判定しやすい。強制順位付けに比べるとBestとWorstだけ答える方が答えやすい。スライドは研究集会サイトに公開予定。
- □第2報告は中間さんと中野先生の報告で,ハイパフォーマンスコンピューティングのためのRhpcパッケージの紹介。統数研のスーパーコンピュータで使えるような並列計算のためのパッケージとして開発中。snow(Rで書かれているので若干非効率),Rmpi(MPIのAPIへのアクセスなのでRとの対応がいまいち), multicoreのような既存パッケージは一長一短。multicoreはSimon Urbanekが開発し,LinuxとWindowsで動く(でもスーパーコンピュータでは使えないということ?)。snow並みに使いやすく,かつ制限の無いパッケージとしてRhpc開発に着手した。並列計算の説明を丁寧にしてくださっていて,細かいところはわからないが,何となくイメージは掴めた……ような……掴めないような。Rhpc_lapplyLB()関数でロードバランスをとりつつ実行させるとか。プロセスをworkerとして複数並列で動かす感じ。RhpcBLASctlという派生パッケージはwindowsでも使えるし,CRANにも登録済み。たしかにinstall.packages()できた。Rmpiは2GBを超えるデータを扱えないが,Rhpcは大きなデータも小分けして扱える。snowのclusterExportは順次workerを1対1通信で呼ぶのでworkerが多いとリニアに遅延発生,RhpcはMPIの集団通信なのでworkerが増えても大丈夫。RhpcはMPIにかなり依存。まだ開発途上で,統数研内の中間さんのサイトから入手可能。そのうちCRANにも登録予定(だが,WindowsとかMacOSに対応させるのが難しい? ので悩み中らしい)。
- □第3報告は奥村さんで,TeX Liveと美文書第6版とRについて。 昨日のDuncan Murdockさんの話ともつながりありそう。日々やっているネ申退治(?)というか,Reproducible Researchのために実践している話。『美文書』はだいたい3年ごとに改訂。そのときの最新の知識を詰め込んでいる。pTeXに限ってもずいぶん変わっている。pTeX+ε-TeX拡張+upTeX拡張(内部ユニコード)他にもたくさん。これまではpTeXは世界では知られていなかったが,TeX Liveに入ったので世界に広まった。upTeXもTeX Liveに入ったので,ソースをUTF-8で書けば変な文字(半角カナとか丸数字とか)も扱える。 \documentclass[uplatex]{jsarticle}のようにプリアンブルに書き,uptexでコンパイルする(12月1日追記:uplatexを呼ぶ)。注意としては,ウムラウトをキレイに出力するためにはおまじないが必要だったりする。けれども,XeTeXよりキレイ(一般に)。グラフィックエンジンについては,元のpicture環境は低レベル。TikZが驚異的。マニュアルが726ページ。美文書ではTikZの章が11ページにまとめてある。RからTikZに出したい(TeXの本文と同じフォントでの作図)→tikzDeviceが現在使えないが,knitrの作者たちが復活試み中。ベータ版が公開されている(12月1日追記:devtoolsパッケージをインストールすると使えるようになるinstall_github()関数で,"yihui/tikzDevice"を指定する。インストール時にgccを呼ぶので,Windows版の場合,Rtoolsをインストールしておかないとインストールできないかもしれない)。マイナスがハイフンになってしまうとか,色指定がrgbでされるとかいったところ,若干手作業で修正が必要。
- □第4報告者,中谷さんはCVMのためのパッケージDChoice。ラマンチャのuser!2013で発表された内容とのこと。ちょうど昨日リスク論の講義をしてきて,CVMも解説したばかりなので,細かいところが気になった(WTPに特化した説明だったが,WTAには敢えて触れないのか? とか,直接数字を聞き取る方法と,候補額を提示してWTPとして同意するか否かを聞くのと,どっちがいいのか? とか)。Whitehead, 1995の例。水質改善に関するWTP,提示額に対してYes/Noを聞き取る方法。Yesの人には倍額も聞く。Noの人には半額を聞くという二段階。二段階二肢選択法というそうだ。分析はパラメトリックモデル/ノンパラメトリックモデルがある。パラメトリックのとき,一段階データは二値選択モデル(logit/probit),二段階データは区間打ち切りデータに対応する尤度関数が必要。尤度関数が面倒なのでパッケージ化。ノンパラの場合,WTPを寿命のように考え,生存分析。KMT推定量とSK推定量でどちらがいいか論争あるが,両方計算できるパッケージを作った。DCchoice。二肢選択型CVMに特化したもの。既存研究で利用されたデータをexampleに含んでいる。DCchoiceのインストールは,レポジトリとしてR-Forge,bioconductor,CRANの3つを指定しなくてはいけない。DCchoiceはR-Forgeにあり,bioconductorにしか入っていないパッケージintervalに依存しているため。ロジスティック回帰で得られたパラメータを使って平均値,中央値とその信頼区間を求める関数も定義済み。krCI(?)またはブートストラップで実行できる。(質疑から)被害総額を求める際に,この方法で求める単価が中央値がいいのか平均値がいいのかは決まっていない(らしい)。
- □午前中最後の発表は,東京大学小池さん,野村さんによる「Rによる確率過程の統計解析」 yuimaパッケージ(東京大学吉田教授,ミラノ大学Iacus教授が中心となって開発され,最先端の理論が日々実装されている)を利用。主な関数4つ
- simulate:確率微分方程式のシミュレーション(パスを離散近似で生成)
- qmle:確率微分方程式のパラメータ推定
- asymptotic_term:解の汎関数の期待値を漸近展開により計算
- cce:二系列の非同期観測データ間の共分散を推定
- □午後の報告は谷村さんから。Rによる多変量疾病地図。疾病地図:地域集積性を検出,リスク要因の仮説を立てる→空間統計を援用した空間疫学モデル。市区町村別年齢調整死亡率と社会経済指標をそのまま回帰モデルに投入するのは不適切。少数問題や空間構造を加味したモデルが必要(経験ベイズ平滑化疾病地図)。今日はどうやってグラフィカルに複数の疾病情報を載せるかという話。(例)Snowのコレラの疾病地図,2011年の人口10万対の結核死亡率を使ったコロプレス図(日本,都道府県別)=library(Nippon)を使った日本地図。色分けにはlibrary(RColorBrewer),階級区分はlibrary(classInt),都道府県並びは,通常JISコード順なので,気にしなくていい。しかしこれらは基本的に単変量。複数の変数は複数の地図にするのが普通。同時に見たいときどうする? というのが今日の話。いくつかの手がある。
- 2つの指標を1つに統合
- 形と色に別々の指標を割り当て→人口と結核死亡率なら色と円の大きさでプロットできる(比例シンボル図)
- 異種の地図をオーバーレイ(同じパッケージでコロプレス図に比例シンボル図を重ねることもできる)
- カルトグラム(地図の形を変数に応じて歪める。連続カルトグラム,非連続カルトグラム,円形カルトグラム)Rcartogramパッケージをomegahatからインストール(コードはかなり長くなる):人口に従ってカルトグラム,結核死亡率をコロプレス図にすると,東京のように人口の多いところが大きく表示されて,そこの色で東京の結核死亡率がどれくらいなのかわかる。円カルトグラムだと都道府県名を表示しないとどこがどこかわからなくなるのが欠点(これはまだRcartogramには実装されていない)。
- チャート化:条件付きコロプレス図など。条件変数でスライスを作り,複数の地図を実現。maptoolsとlatticeで可能(例:人口密度で区分した老年化指数。日本人口ならNipponパッケージも使う)。
- 複数の図をアニメ-ション:時系列に限らない。いろいろな連続量でスライスしてつなげることができる。風疹のアウトブレイクの例。
- 彩色工夫:2つの系統の色の混合で2変量を表現maptoolsとhogeパッケージを使うとオーバーレイ法の色の合成が楽。αチャンネルを使って3色混合とか。変数が多くなったら,地図上にチャートを重ねるしかないかも。
- □自分の発表。Hyndmanのdemography, forecastの他は,fmsbに定義した関数のみ利用して,HMDとHFDからデータを貰い,人口のパラメタライズドモデルを当てはめてパラメータ推定し,それを時系列解析して今後50年のパラメータの変化を予測し,そこから将来の年齢別出生率,死亡率を構成し,センサスデータからコーホート要因法でウクライナの人口予測をした話(プレゼン資料改訂版)。(質疑で中谷さんコメント)Rsolnpを使うと局所最適に陥らないで初期値をいろいろ変えて最適化してくれる。収束も早い。→fit*()の中でoptim()を使っているところを置き換える? (ただ,fmsbを書き換えるのは,依存パッケージを作ることになるので避けたいかなあ)
- □中野さん(関西学院大)による,日刊新聞読者投稿欄の計量テキスト分析。新聞社がデータベース化しているので,容易に分析できる?? と思ったら,利用規程(リンク先は朝日新聞)があり,4.に分析してはいけないと書かれている。分析したい人は? 126000円/年とかで別途売っている(朝日新聞の場合)→購入した。朝日と読売の読者投稿欄(「声」と「気流」)を分析した。職業,名前,住所,年齢が載っているのが特徴。売られているテキストデータは,タグ付けされたテキストデータ。\ID\***から次の\ID\***までが1つの記事(朝日の「声」は1988年~1990年は \A2\に「5面」,\T1\の末尾に「(声)」など決まったタグがある。1994年以降は\A2\が「オピニオン」となった。が,Rで自動的にフィールドが抜き出せた。読売の気流は\Y2\が気流,\T1\が[気流]と規則的だが,職業,名前,年齢,住所などの入り方が滅茶苦茶。気まぐれのように変わる。→フィールドの加工は手作業した。「声」総記事数52,346件。総投稿者数32,798(同姓同名の識別はせず)。最大72回出現する名前があった(年次につれて年齢が上がっているのでおそらく同一人物)。年齢6~99歳,中央値50歳。職業は最多は主婦,次が無職,次が会社員(ただし自称)。3134種あった。「気流」総投稿者数20,826。最多投稿は92件。1歳~102歳だったが,1歳は誤植。4歳も誤植だったことが確認できた。職業は朝日より主婦が多く教員が少ない。形態素解析:年齢などとの相関をみたりできる。頻出名詞上位100を比較すると,朝日100にあって読売100にない言葉はいろいろあるが,戦争もそう。「戦争」を含む記事数は4,211件。8月が断然多い。職業別比率,年代別比率も求めた。「戦争」関連語の変遷(声)は,2000年前後から急に「テロ」が増えたり,戦争責任は1990年頃まで多くてその後減ったり。「戦争」の語りは変化しているか?→△。WordCloudというパッケージがあって,それを使った。共起ネットワークの方がいい? →ぐちゃっとして見えない。が,間引く方法がある
- □藤野友和さん(福岡女子大;twitterアカウントはnonki1974。Rによるインタラクティブグラフ生成とその応用。目的:Multiple linked viewsをggplot2の出力により,Webブラウザ上で実現。コロプレス図も。GGobiがスタンドアロンソフトとしては有名。それっぽいものはできた。背景:福岡県における人口動態,死因別死亡数データ(市町村別,死因別,年齢階級別)の活用~かなり莫大なデータ。福岡県保健環境研究所との共同研究であり,県や保健所職員の利用を想定している(去年報告した,rubyでサーバにコマンドを送り,svg出力しているもの。これをRでやることと,インタラクティブにすることが今回の目的。インタラクティブなコロプレス図:シェープファイル→タグ付け→gridSVGでSVGに変換→javascript追加。Export grid graphics as SVG。CairoによるSVG出力では構造は反映されない(図形情報のみ)。散布図におけるidentificationの例。grid.script(paste("var x=",toJSON(...),";",sep=""))。grid.getit()してgrid.garnish()してgrid.export()。grid,ggplot2,gridSVG,rjson,GGally,maptools,rgeosパッケージが必要。データはShapefileとCSVのみ。作成可能なグラフは,散布図,ヒストグラム,並行座標プロット,コロプレス図。wrisp.scat(x, y, data, name, tag, ...)。MLWのための散布図をSVG形式+JavaScriptで出力。地図をなぞるとその地区の折れ線に色が付くとか散布図に色が付くような事ができる。SVGなので,拡大縮小が自由にできるところが利点。(質疑から)ぜひパッケージ化してほしいという要望が出た。
- □次はef-primeの鈴木了太さん。もちろんR AnalyticFlowの話「データ解析のためのR GUIフロントエンド」。Javaで開発。RとはJRI経由で接続。BSDライセンス。自動バックアップ機能,復元機能,充実したチュートリアル,インストールの簡便さが売り。R AnalyticFlow 2.1を昨日リリース済みで,新機能は,オブジェクトの種類別表示,エディタ機能(形式を選択して貼り付けが便利),フォントサイズの変更ができるので,プレゼンテーションでもコードが見やすいこと。開発中のバージョン3の話(資料は非公開)が刺激的だった。仕様はまだfixじゃないそうだが,ドラッグドロップでデータファイルにリンクできるとか,テキストファイルはクリック一発自動判定して表形式表示(巨大データのときは部分表示。zipされていても中身も見える)とか,そこから入出力メニューがあって,実行すると実際にRに読めるとか,カラム選択もチェックしていくだけでOKとか。JMPに勝ったな。すべて,裏でRのコードが生成されて実行されている。グラフ作成とかモデリングとかもメニューから選んでできる。実行したもの全部が自動的にフローチャートになる。将来的には,マークダウンっぽいユーザ定義によるGUIの拡張までやりたい→Rcmdrに似てきた? 凝ったことをしたいときはjavaの知識も必要? 分析手法を選ぶと自動的にパッケージがダウンロードできるようにとか?
- □次は神田先生。もちろんEZRの話。メールでは何度もやりとりしていたが,失礼ながら思っていたより若くて驚いた(後で話したところ,駒場でぼくの1学年下とのこと)。神戸出身とのことで,釈迦に説法,チャカは鉄砲とか,エビデンスと海老ダンスとか,スライドが関西人だった。EBMと臨床研究の間でClinical Questionsを挟んで行ったり来たりする。臨床医に統計学が必要か? というと,国内の生物統計かの数は圧倒的に不足しているので,EBMの実践のために,臨床研究の実践のために,生物統計家と話すために最低限の知識は必要。ただ,統計学全般が必要なわけではなく,日常必要な手法は限られている。ソフトとして臨床医に一番使われているのは? StatView(2002年にSAS社に敵対買収され,消滅した)がユーザー最多。Stataはかなりポピュラー。7万円と高価。スクリプトを書く必要があり,かつ機能が足りない。SPSSは高すぎる。JMPは8万円。Rなら問題解決。でもマウスで操作できないと臨床医にとっては壁が高い(スクリプトは書けない)。開発の動機は,日本造血細胞移植学会WGでのニーズ。競合リスクをちゃんと扱える,生存解析に強いソフトが必要ということ,時間依存性変数への対応も必須であり,マウスでメニュー操作するだけで解析でき,解析ログを記録できることも必要。かつ無料であってほしい。そこで,Rcmdrに機能を加えることにした。機能追加しているうちに長大なコードになり,現在のスクリプトは13,934行ある。(質疑)フランス語で使いたいニーズがあるが,対応の可能性はある? Rcmdr自体は対応しているし,.poを訳せばいいので,フランス語がわかる人が開発協力してくれれば可能(というわけで,谷村先生の人脈で何とかなるのであろう)。survivalは突然返ってくるオブジェクト内の変数名や構造が変わるので,pluginからインストールする場合,バージョン不整合が起こらないように追随するのが大変。1.20からはpluginでインストールしても標準メニューが崩れなくなったとのこと。朗報。MacOS版でWindows版のような簡単な独自インストーラはできないのか? 尋ねたら,Macの達人が協力してくれれば可能ではないかというお答えだった。留学生などのマックユーザに使わせるのが楽になるので,将来対応されると良いなあと思う。
- □最後はLT大会(Japan.Rの前哨戦)として,5名の若手による報告。Japan.Rとは,日本各地のR勉強会の参加者が集まって開催される年一度の勉強会。今年で4回目。去年まではこの研究集会と同時開催だったが,両方出たいという人が多く,今年は12月7日(土)にYahoo六本木で,13:00~開催。250人がもうほぼ埋まっているが,今日箕田さんに言えば何とかなるとのこと。以下概要。
- 箕田高志「商用ツールとRの連携」。Magic Quadrant(各DBベンダー,BIベンダー)箕田さんのTwitterアカウントは,aad34210。仕事はyahooのネット広告アナリスト。商用ツールベンダーはRを脅威に考えている? 例示:SAS/IMLでRと連携,MicrosrategyはBIツールの中では老舗。Rを取り込んでいる(パッケージ経由),TableauもRを連携させ,積極的に関数やグラフィクスで使えるようになっている,CognessとかBusinessObjectsはRとの連携はとくに言及無し,OracleはRを独自拡張したOracle R Enterpriseを無料で提供,TeradataはDWH最大手で,teradataRを提供しているがCRANには非公開(R3.0で使えないのでサポートサイト炎上),ネ申SQLServerはRとの連携は言及無し。連携は一部ベンダーで進行。今後拡大しそう。
- 田中ひでかずさん「SlidifyとrChartsの話」japan.R主催者。RMarkdownでスライドを作成する。Slidify:knitrベース。開発者はインド人。Rコードと実行結果を埋め込むことができる。LaTeXやMathMLの記法で数式を書ける。CRANには入っていない。githubからインストール。author()して,index.Rmdを頑張って編集するとひな形ができるので,あとは簡単。slidify('index.Rmd')とか。rChartsはJavaScriptの可視化ライブラリをRから操作するパッケージ。開発者はSlidifyと同じインド人。インタラクティブ。インストールはinstall_github('rCharts','ramnathv')とする。グラフはggplot2を使って作っている。データが大きいとrChartsは非実用的なので。
- 和田計也「Shinyサーバの話」 Twitterアカウントはwdkz。サイバー系企業勤務。Rのコーディングだけでブラウザ上で動く,javascriptで作ったようなインタラクティブなアプリが作れるのがShiny。ui.Rとserver.Rだけ書けばいい。Shiny-Serverを利用してサーバにデプロイするのが配布のいい方法。Twitterアカウントhoxo_mさん作成のOpenShinyを利用してユーザにShinyアプリを配布することもできる。ただしOpenShinyは.netを使っているのでWindowsマシン限定。複数ユーザの同時接続に弱いという致命的何か(落ちてしまう)。作者も問題は認識している。Node.js自体は大丈夫だが,そことRをつなぐところがネック。解決方法は複数Rを起動するとか(@mtknnktmさんがどこかできっと発表するとのこと),ロードバランサを噛ませて複数台のサーバでnode.jsとRのセットを動かす,等。nginxというApache HTTP serverのようなソフトがロードバランサ機能をもったhttpdを使う。開発元は,Shiny Server Proという商用をリリースする計画あり。値段はあと数週間で発表されるが,RStudioの会社が作っているので,かなり高い感じ。
- 「妹ができました~僕とBotとRPubs~」Twitterアカウントhoxo_mさん(Tokyo.Rのノリのタイトルだが内容は真面目とのこと)。某ECサイトでデータ分析をしている。RPubsRecentというbotの中の人。Easy web publishing from Rを狙ったのがRPubs。Rのソースコードと実行結果を簡単に投稿できて公開できる仕組み。Rに関する優良記事が多数投稿されている。トップページは人気エントリーなので,新着記事を流すbotを作った。@RPubsRecentをtwitterでフォローすればいい。@RPubsHotEntryは,@RPubsRecentで流れたtweetのうち,お気に入りを誰かがつけたエントリだけが流れるbot。なお,投稿言語の半分は英語だが,日本語の投稿も若干ある。
- 里洋平「2013年のTokyoRとデータサイエンス活用事例」。Twitterアカウントyokkuns。TokyoR主催者。データサイエンティスト養成読本執筆。TokyoRは,最初の頃は20人くらいだったが,最近は100人超。データサイエンティストブームが引き金。TokyoRの構成は,前半:初心者セッション,後半:応用セッション,LT:各人5分,懇親会(その会場でピザパーティ)となっている。これまでのプログラムでは,plyrパッケージで君も前処理スタという第30回の発表がお薦め。今月あったのが第35回。続いてyokkunsのデータ分析環境の話。Hadoopに各サービスのDBと行動ログを集約。R言語を徹底活用して分析/レポーティング。分析用サーバが2台:片方はRStudioサーバー,もう片方はR Batch Server。後者で定常業務。HDFS上のデータ取得や独自アルゴリズムをパッケージ化している。DrecomHdfsパッケージとか。EasyHTMLReport/Shinyで各種KPIをHTMLメールで配信。いろんな軸でドリルダウンしたいようなものはShiny。ユーザー・セグメンテーション:行動ログを用いてユーザーのセグメンテーション。各セグメントの行動特徴を主成分分析で確認し,クラスタリングで最適クラス多数を算出し,クラスタの行動特徴をハマっている順にならべてプロット。ユーザをよりハメたい。クラスタ変化=ユーザの成長。キーとなっている行動の変化を促進させる戦略。自動化とレポーティング:前週のクラスタと今週のクラスタのクロス集計などをメール配信。
- R-3.0.3リリースなど(2014年3月24日)
- ■【ご恵贈御礼】石田基広『とある弁当屋の統計技師(2)因子分析大作戦』共立出版,ISBX978-4-320-11082-3をご恵贈頂いた。因子分析なんて高度な分析法をラノベ仕立てにできるんだろうかと危ぶんでいたのだが,実はQ and A形式で進めるのに向いているネタなのかもしれない。表紙イラストが,ラノベでありながらネットワーク管理やシステム構築の世界におけるSEの実情を如実に描いたと評判の『なれる!SE』シリーズのイラストを描いているIxyさんになった。絵柄を見ただけでそうじゃないかと思ったが,やはりそうだった。表紙の2人など,桜坂兄妹のようだ。かなり詳しい書評をここに載せた。ありがとうございました>石田先生。
- ■Rothman教授から返事があって,p値関数を描くpvalueplot()で使っていた式が不適切だったことが確認できた(RRやORの点推定値の点と,帰無仮説RR=1やOR=1の点では正しくp値を計算するのだけれども,それ以外はnested confidence intervalsとズレてしまう。テキスト8章では「RR=1の点だけでなく,あらゆるRRについてのp値が計算できる」と書かれているが,その式が与えられておらず,9章の式を援用しようとしたのだが,Rothman教授によるとRR=1やOR=1の帰無仮説以外にその式を使うのは不適切なので,Rothman教授自身は,先にp値を与えて信頼区間を逆算し,nested confidence intervalsとしてp値関数を描画しているとのことであった)。そこでfmsbのコードをRothman教授と同様の計算方法に修正し,バージョン0.4.3としてCRANにアップロードした。これまで何年も講義をしているのに,p値関数がおかしいのではという疑問点は,今年の学生から初めて指摘された。もし既にpvalueplot()を使ってしまった方がいらしたら,大変申し訳ありませんでした。
- ■あのforecastパッケージの作者Rob Hyndmanさんが2013年に実施した,Rによる時系列予測の12時間コースのプレゼン資料が公開されている,というR-bloggersの記事を見て,参照せねばと思っていたが,続報で,Hyndmanさんご自身のblogでforecastパッケージのバージョン5リリース(1月末にリリースされたそうだ。リンク先は変更点のまとめ。欠損値と外れ値の処理とか)を知った。
- ■R-bloggersに載っていたので知った,Rob Hyndman教授のブログ記事,Free books on statistical learningで紹介されている統計学のテキストは700ページ以上あって,さまざまなトピックをカバーしていて,無料のpdfファイル。素晴らしい。ぼくが公開している入門テキストより遙かに専門的なところまでカバーしている。
- ■Rと人口学に関心がある人は必読のRob J. Hyndman教授のBlog,Hyndsightの記事Computational Actuarial Science with Rから,この新しい本でHyndman教授が共著者になっている章である"Prospective Life Tables"がpdfでダウンロードできてしまう。Rコード自体はすべてGitHubからダウンロードできるようになるそうだ。この章は将来の生命表の予測方法について,日本でも非常によく使われているLee-Carter法に始まり,いくつもの方法が計算例入りで丁寧に紹介されている。Hyndman教授自身が開発されたHyndman-Ullah法とそのバリエーションは,まだ知名度は低いが良さそう。こうやって簡単に使えるパッケージになっているのは素晴らしい。練習問題もついているので,時間ができたらやってみようと思う。
- ■元々英語版を作って公開していたのだが,2月28日に日本語版を作ってsemパッケージでCFAする方法なども加筆し,Rで因子分析:入門編を完成させた。
- ■2014年3月6日付けで,予定通りに,R-3.0.3(コード名:Warm Puppy)がリリースされた。アナウンスメール。
- ■4月10日リリース予定のR-3.1.0(コード名:"Spring Dance")のα版ソースコードが3月13日から公開された。
- ■useR!2014 in LAへの発表呼びかけ文。
- ■ネットワークメタアナリシスについて調べたら,Rだとnetmetaというパッケージがあった。他にもCRAN Task view: meta-analysisに,メタアナリシス関係のパッケージ情報がたくさんある。
- ■semについて豊田さんの本の[Amos編]をRでやってみたというブログ記事と,本家から[R編]が出ることを,このtweetで知った。
- ■Rで書かれたアッカーマン関数のコードを見て,
とtweetした後で数値入力して調べたら,(3, 5)までは計算できたが,(3, 6)や(4, 1)はスタックが溢れて計算できないことがわかった。options(expressions=500000)としておくと,デフォルトのoptions(expressions=5000)では計算できないack(3, 6)は計算できるようになるが,それでもack(3, 7)やack(4, 1)は計算できない(ノードスタックが溢れる。ちなみに1行でifelse()を使う代わりに複数行でif () else ()という形で書くと,使うスタックが変わるようだ。いずれにせよ溢れるが)。柏野さんから,Haskellなどではスタックを食わない末尾再帰(tail recursion)が普通というご指摘があり,調べたところ,2012年時点ではRではサポートされていないとのこと。現状では,ループを使って非再帰で書くしかないようだ。エレガントでないが仕方が無い。Rは素直な再帰でも1行で,
ack <- function(m, n) { ifelse(m==0, n+1, ifelse(n==0, ack(m-1,1), ack(m-1, ack(m, n-1)))) } - ■RでAckermann関数を書く話の続き。あのシュールな巨大数寿司屋漫画の作者の方が作られたのであろうページに掲載されているC++版なら,Rに移植できそう。途轍もなく遅そうだけれど(なお,考えてみれば,ack(4, 1) = ack(3, ack(4, 0)) = ack(3, 13)なので,m=4のハードルの高さは自明だった)……と書いたら,柏野さんから,移植では無くRcppでそのまま使う方がいいのでは? というsuggestionをいただいた。確かにその通りかもしれない。Rで末尾再帰は絶対に無理かというと,このPythonコードのように,アルゴリズム自体を工夫して末尾再帰にしたものは,Rに移植できた。つまり,フィボナッチ数列を素直に再帰定義するコードは,
となるが,これだとn=20程度でもスタックが深くなりすぎて計算不能になってしまうところ,fib <- function(n) ifelse(n<=1, 1, Recall(n-1)+Recall(n-2))
と書けば,無駄な計算をしなくなりスタックが深くならないので大きなnでも高速に結果が出る。奥が深い。ちなみに,関数定義内でRecall()と書くのと定義される関数名をそのまま書くのは同じことだが,Recall()だと別名にコピーして元のオブジェクトをrm()しても大丈夫だが,定義される関数名をそのまま書いてしまうと,同じ操作で使えなくなってしまうので,Recall()の使用がお勧めらしい。結局,3月24日に東に向かう新幹線の中で,前述のC++で書かれた非再帰版アッカーマン関数をRに移植してしまった。このコードは,ポインタを配列の添字にしたので,メモリ操作的には非常に無駄が多いが,移植自体はうまくできたと思う。ただ,これでack(4, 1)などやろうものなら,いったいどれくらいの時間が必要か見当も付かない。fib2 <- function(n, a1=1, a2=0) ifelse(n<1, a1, Recall(n-1, a1+a2, a1))
- R-3.1.0リリースなど(2014年5月2日)
- 3月末から4月末までのR関連の記事を拾っておく。
- ■(2014年4月10日)R-announceメーリングリストで,予定通りR-3.1.0(コードネーム「Spring Dance」)がリリースされたことがアナウンスされた。pdf()で使える新しいフォントファミリとして"ArialMT"が入ったとか,cos(pi*x)を正確に計算するための関数cospi(x)などが実装されたとか,fft()への入力データがこれまで1200万までだったのが20億まで可能になったとか,Sweaveが入力がUTF-8であると宣言してあればUTF-8の.texファイルを出力するようになったとかいった辺りが目に付いた。
- ■(2014年4月21日)RjpWikiのトップページへのコメントで知ったが,The R JournalにIFが付いていた。これは投稿するしかあるまい。このところ先延ばしにしていたが,R-3.1.0をインストールし,常用パッケージもインストールした(ただ,現在兵庫教育大ミラーが落ちている? ようなので,統数研ミラーを使ったが)。
- ■(2014年4月23日)ご恵贈御礼:石田基広先生から,『改訂2版 R言語逆引きハンドブック』C&R研究所,ISBN:978-4-86354-147-4をご恵贈頂いた。いつもありがとうございます>石田先生。本書は,Rでやりたいこと(目的)に応じて必要な関数が引けるように作られた事典のような本であり,この改訂2版では,バージョン3に対応したのと同時に,高速にデータ構造を前処理するのに適したdplyrパッケージについてや,統合環境RStudioについての記述が追加されたとのことである。目次と索引も見やすく構成されていると思う。
- ■(2014年4月30日)このブログ記事のembed()という関数は知らなかったが便利だな。別解として,先に添字の行列を作ってしまう
てのを考えてみた。が,汎用性がいま一つだな。x <- sample(1:100, 100, rep=FALSE) # 長さ100の配列を適当に作っておく
colSums(matrix(x[sapply(1:96, "+", 0:4)],5)) - カテゴリ変数間の関連について(2014年5月19日)
- ■エビデンスベーストヘルスケア特講Iで,クロス集計表とその分析という話をした。ついでに,ポリコリック相関係数についての補足説明を作ってアップロードした。
- ■院生などから統計解析関係の相談を受けていて,困ることの筆頭が,SPSSにしか出てこない用語での質問をされることだ。例えば,SPSSのクロス集計表の解析では,字面からは意味不明な用語として,「線型と線型による連関検定」なるものが出てくる(参考:名古屋大学のサイトにある説明)。これはSPSS用語なので,一般の統計学の教科書には出てこず,尋ねられても説明のしようがない。リンク先の名古屋大学のサイトの説明を読むと,「行、列のどちらも量的変数の場合、カイ2乗は線型と線型による連関検定になる」と書かれているが,これでは何をやっているのかの説明になっていない。
- □通常,こういう相談を受けたときには,「ソフト内部で何をしているか,少なくともどういう理論に基づいているかの文献引用くらいはマニュアルに書いてあるはずだから,マニュアルを読め」というアドヴァイスをするのだが,この例の場合は,マニュアルにもロクに説明がないようだ。
- □そこで英語版を調べたら,この解析の元の英語は,"linear-by-linear association"らしいことが判明したが,やはり理論の厳密な説明は見つからない。順序のあるカテゴリ変数間の独立性の検定手法として勧められていることはわかるが,どのように帰無仮説の下で自由度1のカイ二乗分布に従う統計量を計算しているのかがわからない。
- □そこでRのパッケージを調べたら,coinパッケージのlbl_test()関数で実行できることがわかった。ヘルプを見たら,詳細な説明がAlan Agresti (2002) Categorical Data Analysis. Hoboken, New Jersey: John Wiley & Sons.で得られることもわかった。methods("lbl_test")の結果を見てgetS3method("lbl_test", "IndependenceProblem")とすると,中でindependence_test()が呼ばれていることがわかり,methods("independence_test")からgetS3method("independence_test", "IndependenceProblem")とするところまでは追えた。しかし,その先は追えなかった。
- □けれども,Thompson (2009)によるAgrestiのカテゴリカルデータ解析第2版(2002)のためのR(かS-PLUS)マニュアルのp.39~40を読んで簡単な計算方法がわかったので試してみた(リンク先は名古屋大学のサイトに載っている数値例を使って,SPSSと同じ検定をカバーするために必要な手順を書いたRコード)ところ,結果が一致した。つまり,この手法は,2つの順序のあるカテゴリ変数の各個体に対して順序を整数のスコアとして与え,スコア間でピアソンの積率相関係数を計算して2乗した値にサンプルサイズから1を引いた値を掛けた統計量が,近似的に自由度1のカイ二乗分布に従うことから検定を実行しているのであった。検定手法の名前としては,カテゴリに線型性を仮定したカイ二乗検定とでも呼んで,Agresti (2002)を引用すればいいのかもしれない。
- その後の2014年5月中のR関連情報(2014年9月2日追採録)
- ■(5月21日)3日前にSPSS用語「線型と線型による連関検定」について書いたら,たけしょうさんから,藤井良宜『Rで学ぶデータサイエンス1 カテゴリカルデータ解析』共立出版,ISBN: 978-4-320-01921-8では「線形連関の検定」と書かれているとご指摘いただいた。確認したら,確かにpp.65-68で取り上げられていた。式もちゃんと載っていたし,coinパッケージのlbl_test()関数で自然数以外のスコアを与える方法の説明もあった。ただ,自然数でないスコアを与えると「線形」でなくなってしまうかもしれないのが気になった。コクラン=アーミテージ検定とかマンテル検定,一般化マンテル検定などでは順序尺度に適当なスコアを振れるので,同じように考えたら一定の合理性はあるのかもしれないが,この検定の場合は名前から言ってスコアは自然数固定でいいような気がする。あるいは別の名前にするとか(スコア連関検定とか?)。
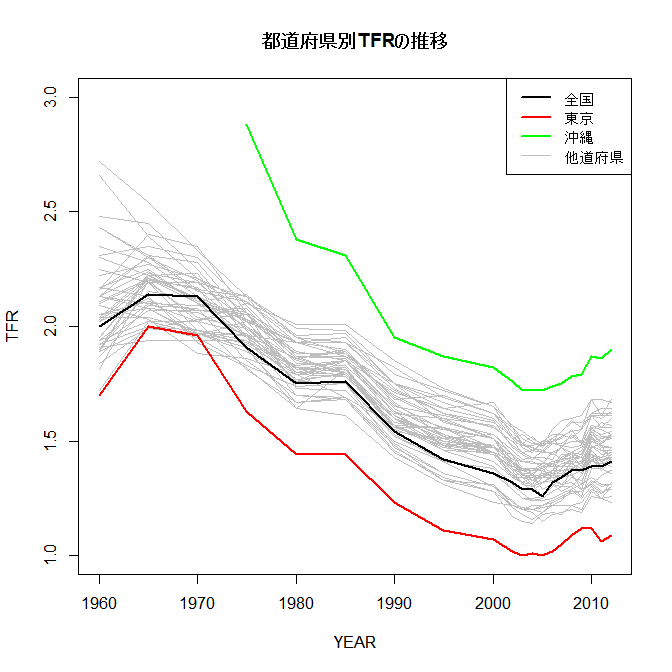
- ■(5月25日)東京のTFRが低くてpopulation sinkになっているという話は最近の話ではなく昔からだ(この資料の6枚目参照 )。東京のTFRが他道府県とはかけ離れて低いというグラフを,e-Statからデータをダウンロードして自動的に描くRコードを書いてみた。
- ■(5月30日)著者によりtwitterに流れていたのでRTした共立出版のR本の新作『Useful R (9) ドキュメント・プレゼンテーション作成』は面白そう。Amazonに発注しよう。
Correspondence to: minato-nakazawa[at]umin.net.