- 2015年7月のRニュース(2015年12月29日)
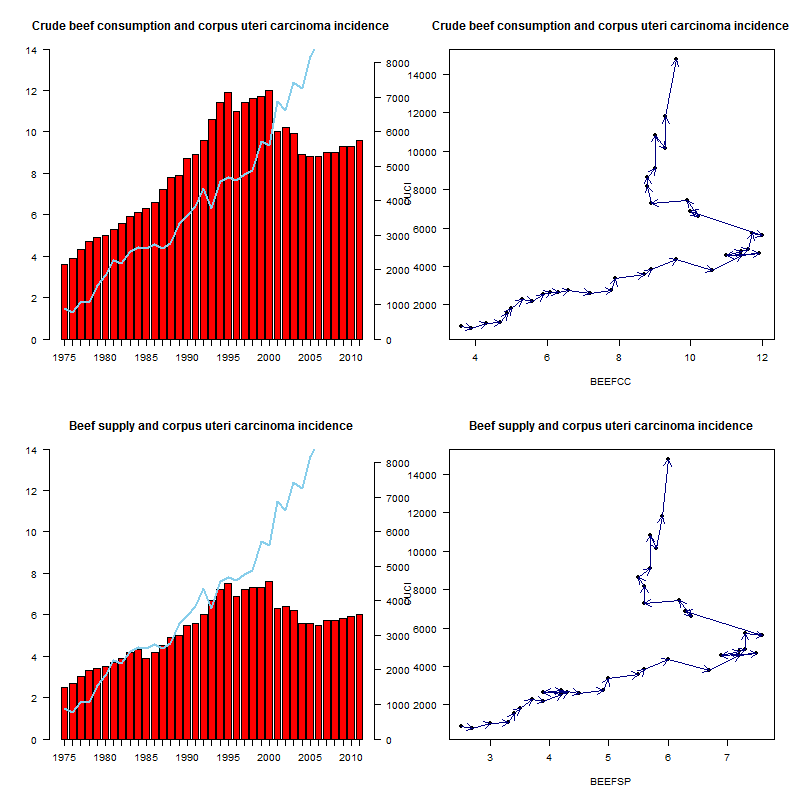
- ■(2015.7.4) 木曜の講義中,院生の一人が示した生活クラブのサイトにあるグラフ(ピタリと一致!子宮体がん発生数と日本人一人あたりの年間牛肉消費量,という題のもの)の見方には注意が必要という話をしたのだが,せっかくなので少し敷衍しておく。時系列の2つの量が関連しているというには,年次を横軸,2つの量を縦軸にとって推移が似ているというのでは不十分で,推移を矢印でつないだ散布図が最低限必要だし,本当は女性のみの一人当たり年間牛肉消費量が必要だが,食糧需給表からではそれは計算できない。とりあえず,ここに示されている元データを入手するのはそんなに難しくなくて,日本人一人当たりの年間牛肉消費量は食糧需給表から,3-7の中の牛肉というところからExcelのワークシートをダウンロードでき,子宮体がん発生数は,このページの「2.罹患データ(全国推計値)」からExcelのワークシートをダウンロードできる。それぞれ該当データを抽出してタブ区切りテキスト形式にしたものがbeef-and-corpus-uteri-carcinoma.txtである。数値からみると,当該グラフで使われている「日本人一人当たりの年間牛肉消費量」は国内消費仕向量の粗食料の値であり(リンク先データではBEEFCCとした),歩留まりが考慮されていない。むしろ1人当たり供給量(リンク先データではBEEFSPとした)の方が摂取量には近いと考えられる。リンク先データでは子宮体がん発生数はCUCIとし,年次はYEARとした。このRコードを実行すると,生活クラブのサイトにあるグラフを再現したものが左上に,消費量を供給量にしたものが左下に,それぞれ矢印で推移を辿る散布図が右側にできる(下図)。真の正の相関関係であれば,左下と右上を結ぶ方向に推移するはずだが,ほとんどそういう推移になっている年度はない。摂取から発症までの潜伏期間を考えてプロットする年をずらしても,きれいな関係にはならなそうである。
- ■(2015.7.7) 先週末に書いた,誤解を生むグラフについてのフォロー記事への参照数が,奥村さんがtweetしてくださったおかげで200を超えている(奥村さんのtweetのretweetが200以上ある)。その関連で,擬似相関を集めたサイトやその書籍版の存在を知った。そのうちメイン州の離婚率の推移と米国のマーガリン消費量の推移の強い相関を図示するコードを書いてみたが,この場合は,数値として大小の変化を共にする関係が存在することは否定できない。その上でまったく因果関係は考えられないので,典型的な擬似相関と言える。しかし手作業だとしたら気が遠くなりそうな組合せを調べたと思われるが,そうではなくて,さまざまなソースから自動的にコンピュータに探索させたのだとしたら,何となくやり方は想像が付くものの,自動的にデータとして読み取らせるための加工ルールをどうやったのかが知りたいところ。書籍版には,これらの擬似相関をどうやって見つけたのかというアプローチ法の詳細は書かれているだろうか?
- ■(2015.7.17) R-3.2.2(コードネーム:Fire Safety)のリリース予定が8月14日というメールが入った。あと1ヶ月もないのか。
- ■(2015.7.30) 医療保健統計学・疫学特講IIの集中講義1日目。RStudioを使って,今日はデータ操作と作図テクニックと因子分析を説明した。途中,計算はできるが図が描けないという院生が続出したが,Windowsでユーザ名に2バイト文字を使っていると嵌まる罠らしい。追記せねば。図を描くのは素のRでやればできるということで回避したが,今度はパッケージのインストールをシステムでなくマイライブラリにすると,2バイト文字がユーザ名にあるとlibrary()で呼び出せない問題が起こった。Windowsのユーザ名は半角英数にすることを強く薦めると書かねば。しかもこれが,relaパッケージは大丈夫だがpsychパッケージがインストールできたように見えて呼び出せないという不思議な状況で,状況把握に難儀した。なぜこんなことが起こるのだろう? 依存関係絡みか? それにしても6コマ弱喋ると疲れる。明日は5コマなので多少マシか?
- 2015年8月のRニュース(2015年12月29日)
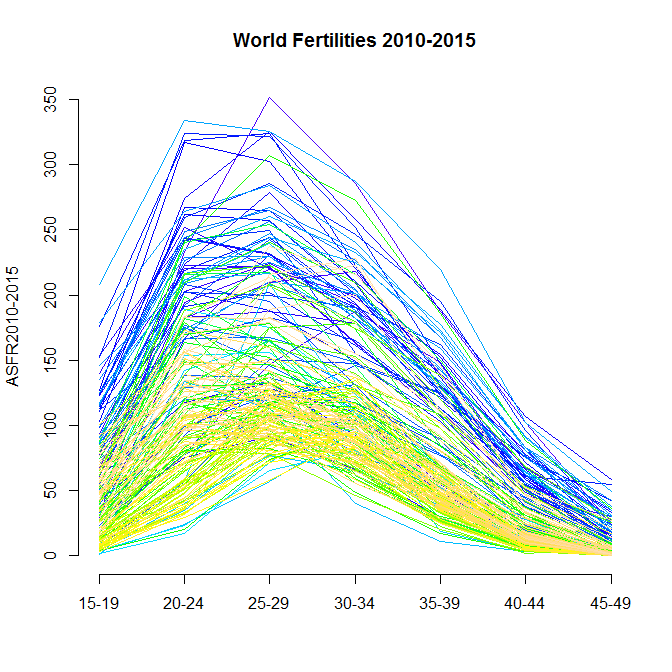
- ■(2015.8.1) 食べながら正規分布など好きな関数の曲線を描きたいという記事をみて,この程度ならbaseでやる方が早いしわかりやすいしきれいに書けるよなあ,と思ってコードをtweetした。それでWPPのトップページを見て以来ずっと作りたかった世界各国の2010-2015の年齢別出生率(ASFR)を図示するコードを書いた。注釈を書いたとおり,WPP2015のデータはExcel形式で提供されているので,直接読むにはxlsを読める機能をもったパッケージが必要だが,Hadley Wickhamさんが作った爆速readxlパッケージを利用することにした。このパッケージではURLから直接ファイルを読み込むことができず,Rの作業ディレクトリ(setwd()で指定できるが,readxlをロードした後では変更不可になってしまう? かもしれない)に予め置いておく必要があるが,読み込んでしまえば後は簡単で,下のようなグラフがすぐできた。ちょっと工夫すれば,日本だけ赤い線で強調するとか,5年ごとの推移をanimation表示することも,さほど労せずしてできそう。腕に覚えのある方は作ってみては?
10:00からは集中講義3日目で,非常勤講師の先生がオミックス解析の話をされる予定。今日はただ聴くのみ。
導入がいきなりオリセットネットの写真(住友化学としては,タンザニアに工場を作って技術移転をした成功例でもあるから,確かにアピールポイントとしてはいい狙いだと思った)で,毒性学入門的な話から始まり,ゲノミクス,トランスクリプトミクス(トキシコゲノミクス),メタボロミクスの解析は何を目的としていてどうやって進めるのかという話を現場の視点を交えてされ,大変興味深かった。確か2年前のR研究集会で「オミックス解析はRが使えないと話にならない」という発言があった気がするが,確かに主要な道具がSVM(サポートベクターマシン)とPCA(主成分分析)と階層クラスタリングだったらRにたくさんのパッケージがあるから,その通りなのかもしれないと思った(木曜の1日目に主成分分析は説明したが,実行例にオミックス解析も入れよう。たぶんprcomp()関数を使わないとできない場合が多いと思われるが)。さすがに今日「オミックス解析はRが使えないと話にならない」が本当なのかどうか尋ねはしなかったが。ちょうど11:30に講義が終わった後も,11:45まで質疑にお付き合いいただいた。ありがとうございました。
その後,21:00までかかって,昨日まで講義をしながらデバッグしたテキストを修正してアップロード。神戸大学大学院保健学研究科の大学院生諸氏には,研究デザインの説明から,EZRを使って医学/保健学分野でよく使われる統計処理をする方法を解説したエビデンスベーストヘルスケア特講テキストと,RStudio(または素のR Console)のスクリプトエディタでコードを打って,細かい作図,主成分分析と因子分析,構造方程式モデリング,マルチレベル分析を行うための医療保健統計学・疫学特講IIテキストを併読していただきたいと思う。
微修正していたら21:50になってしまい,土曜の湊川公園廻り終バスに乗れない時刻になってしまった。諦めて研究室でovernightすることにしたので,上述のアニメGIFを作ってしまった(コード)。 - ■(2015.8.2) ふと思い立って,昨日アップロードしたテキストの主成分分析のところをさらに追記した。論文に載っている例をRで再現してみたが,欠損値の扱いが明記されていなくて難しかった。結果からみて,たぶんペア単位の除去をしているのだと思う。
昨日の深夜に作った世界各国の年齢別出生力パタンの1950年から2100年までの変化を示すアニメGIFを改良した(コードも改良版をアップロードしておく)。データソースは,World Population Prospects 2015の年齢別出生力のExcelファイルの,シート1に入っている1950年から2015年まで5年ずつの推定値と,シート2に入っている中位予測による2015年から2100年までの将来推計値。こうやってビジュアル化すると,国連中位推計だとこんなに世界中で出生力がシュリンクすることになっているのか,とインパクト大。 - ■(2015.8.5) EZRバージョン1.23から実装されたサマリー表の作成機能は超便利で,相談された内容はほぼそれだけで片付いてしまったが,EZRというよりも,コンピュータの扱い方そのもので引っかかっているようだった(タブ区切りテキストとしてクリップボードにコピーされた内容はExcelに貼り付ければそのまま表になるとか,拡張子でソフトへの関連づけがされていることとかが,たぶんわかっていなかった)。そういう院生多いよなあ。エビデンスベーストヘルスケア特講Iの最終ミニテストの問題と解答例(と英語版問題)を今年のものに更新した。解答例を作っていて,これまでのテキストのサンプルサイズ計算の数式に致命的な符号の間違いを発見してしまい,テキストも更新した。RやPSで計算するのが普通なので,これまで気づかなかった。もし手計算している人がいたら大変申し訳なかった>院生諸氏。
- ■(2015.8.7) 夜中に届いていたR-develメーリングリストのやりとりを眺めていたら,R-3.2.2(コード名Fire Safety)は,既にベータ版が入手できるようだ。明日がRCのリリースで,14日が3.2.2のリリース予定。とはいえ,基本的にメンテナンスリリースだが,目に付いた変更点は,--internet2オプションがデフォルト動作になるのでオプションとしては不要になることと,これまでNaNを返していたqt(*, df=Inf, ncp=.)がqnorm(*)を返すようになったということか。
索引付けをしつつ,奥村さんの美文書第6版を読んでupLaTeXの使い方をだいぶ改善してクロスリファレンスができるようにしている途中だが,医療保健統計学・疫学特講IIのテキストを更新したのでアップロード。 - ■(2015.8.14) 自分がかつて書いたり現在も更新中の,ある程度長いR関係のpdfファイルについて,スラドの日記にまとめた。「からだにいいもの」さんの記事rafalibパッケージの紹介に「文字列を因子クラス(factor)に変換するas.fumericコマンドは役に立つのではないでしょうか」とあったが,その説明はちょっと変。rafalibの関数定義をみると,文字列をいったんファクターにして,さらに数値型に変換しているだけだった。それだけならas.integer(as.factor(x))で可能だが,as.fumeric(x)はas.numeric(factor(x, levels=unique(x)))としているので,数値がカテゴリのアルファベット順でなく,データ内での出現順になるのが違う。どっちが便利かなあ。
missDeaths: 'Correctly Analyse Disease Recurrence with Missing at Risk Information using Population Mortality'というパッケージがcranで公開されている。疾病の再発データを分析する際,死亡率を使って欠損値を正しく処理する方法を2つ提供しているとのこと。 - □(2015.8.14) R-announceメーリングリストに,予定通りR-3.2.2がリリースされたことが告知された。
- ■(2015.8.25) Twitterで知ったが,Word文書内の表からデータをdata.frameオブジェクトに取り込めるパッケージdocxtractrというものがリリースされたようだ。
- ■(2015.8.30) Rで学ぶ人口分析のページを若干更新した。
- 2015年9月のRニュース(2015年12月29日)
- ■(2015.9.8) RのGUI環境としては,RStudioやR Analytic FlowやRcmdr/EZRが有名だが,BlueSky statisticsも凄そうだ。グラフィクスはggplot2ベースのようだ。データの前処理メニューも充実しているように見える。たぶん自分では常用しないが,暇を見つけて試用はしておこう(しかしそれ以前に,9月3日付けで,人口動態統計H26確定数が発表されたので,fmsbパッケージのJvitalデータフレームを更新しなくてはならんし,さらにそれ以前に前期成績を決定して入力を済ませなくてはならんのだが)。ふと魔が差して,BlueSky statisticsをインストールしてみた。起動するといろいろ追加パッケージが必要というメッセージが出るので,"Tools"の"Package"の"Install ALL required R packages from CRAN"を選ぶ。Syntaxエディタの方にスクリプトを読み込んで実行すると,できるものとできないものがあるが,うまく行けばOutputウィンドウに結果が出る。ただ,このソフトの売り物であるらしいデータエディタがどうやっても開けない。というか,データフレームをアクティブにする方法がわからない。マニュアルをちゃんと読めばいいのか。
- ■(2015.9.10) useR! 2016のアナウンスが届いた。来年は6月27日から30日までStanford Universityで開催とのこと。行きたいなあ。
- ■(2015.9.10) 数日前にメモした人口動態統計データをfmsbに入れる作業をしていないのが気持ち悪いので更新作業をしてしまった。データを追加すること自体は簡単だが,ドキュメントの更新が面倒。19:30頃アップロードしてメールを送ってから終バスで帰宅し,帰宅途中に業務スーパーで買った冷凍野菜とウインナーを茹でてスウィートチリをかけたおかずと白いご飯で晩飯を済ませてからメールをみたら,R Core TeamのDr. Kurt Hornikからのメールが入っていて,CRANへのsubmissionの方法がweb経由ですることに変わったのでそちらからやって欲しいと書かれていた。そういえば,以前そういう告知があったなあと思い出したが,すっかり忘れていて申し訳なかった。慌ててwebからsubmissionし直そうとしたら,Noteがたくさん出てきて,NAMESPACEにたくさんのimportFrom()を付けなくてはいけないというsuggestionが出てきたのでそれを追加した。さらにRStudioのBuildのtoolsの設定で,Checkのオプションとして--as-cranを指定してチェックしたら,DESCRIPTIONのDateのフォーマットとTitleのフォーマットを直さなくてはならないことがわかったので,それも修正した。去年の今頃に0.5.1をアップロードしたときに比べると,デフォルトでメモリに読み込む関数が減ったために,それをimportFrom()で明示しなくてはいけなくなったのだろう。あと,Dateの書式やTitleのキャピタライズの仕方に至るまで,ずいぶんチェックが厳しくなった気がする。ともあれ,何とかチェックはパスしたので,これから再アップロード。1:00過ぎにできたと思うが,cranにはすぐ載らないと思うので,お急ぎの方はこのページからtar.gzかzipをダウンロードされると良いかもしれない(でもcranに載ってからinstall.packges()やupdate.packages()を使う方が良いと思うが)。
- ■(2015.9.11) "on cran now"という通知が届いた。ミラーサーバに行き渡るには少し時間がかかるかもしれないが,fmsbは0.5.2となり,日本の人口動態統計データが2014年まで入ったものになったはず。
- ■(2015.9.12) 構造方程式モデリングについてメモ。Dr. John Foxのsemの解説は,これまで2006年の論文を紹介していたが,実は本の2nd Ed.の付録としてアップデート版が 著者サイト内に掲載されていた。こっちの方がいいなあ。
- ■(2015.9.16) Rを使ったワクチン効果のシミュレーションコードを書いてアニメーションを公開された方がいた。*世界一わかりやすいワクチン講義(誇大広告)(脅威のアニオタ社会復帰への道,というブログの9月6日付け記事)は,この条件では定性的には当然と思われる結果だが,このアニメーションは大変わかりやすくimpressiveで素晴らしい。
- 2015年10月のRニュース(2015年12月29日)
- ■(2015.10.14) 石田基広先生の新作『新米探偵、データ分析に挑む』が,ソフトバンククリエイティブから,今月末に発売されるとの情報。かつて夢想した『統計探偵』ほどマニアックではない気がするが,いい線行ってるかも。
- ■(2015.10.23) UseR!2016のデッドラインがいくつか更新された。
- ■(2015.10.26) ご恵贈御礼。石田基広先生から,ラノベでありながらRによるデータ解析をするという企画の弁当屋シリーズに続く新シリーズ1作目『新米探偵、データ分析に挑む』ソフトバンククリエイティブ,ISBN: 978-4-7973-8230-3をいただいた。大卒新人がほとんど事前知識なしに就職していきなり変人上司から強烈なOJTを受けるというプロローグは『なれる!SE』を彷彿とさせ,豆知識っぽいところは松岡圭祐の万能鑑定士や特等添乗員シリーズを思い出させるが,事件ファイル01に入って,データ処理の必要性からいきなりRStudioを使うところに持って行く展開が豪腕で独自。若干強引だが,入門書と小説のmixtureという狙いだとすれば,こういう持って行き方しかないかもしれない。ぼくがかつて夢想した「統計探偵」企画は,入門であることはまったく目指していないので,あれとはちょっと違うテイストだが,これはこれで面白い。弁当屋シリーズよりも小説としての納得はいく。関連して,最近本屋で見かけて衝動買いしてしまった,『占い処・陽仙堂の統計科学 』は,データ処理の中身にはまったく触れていないものの,易学(四柱推命)を科学にしたいヨーセンさんが何日もコンピュータに計算させ続けないとできないくらいのデータ処理をしているという描写があり,ビッグデータからの機械学習によるデータマイニングなのだろうなあと思わせてくれたところが個人的にはツボだった。途中からの展開はほとんど統計と関係ないので,タイトルから期待した方向ではなかったのだが,小説としてはそれなりに楽しめた。
- 2015年11月のRニュース(2015年12月29日)
- ■(2015.11.7) 岡田さんは既に紹介記事を書かれているが,ぼくは漸く読むのを再開したばかりの,石田基広『新米探偵、データ分析に挑む』ソフトバンククリエイティブ。キャラやストーリーは前にも書いたが『なれる!SE』シリーズのデータ解析版的な雰囲気で楽しめる。細かく見れば,離散値の度数分布図をヒストグラムと呼ぶことには抵抗を感じるし,作図もhist()に生データを与えるよりも,せっかくtable()で度数分布を数字として求めるところまで説明しているのだから,table()の結果である度数分布表をそのままbarplot()に渡す方がいいと思うし,hist()の区切りがデフォルトでは「以上,未満」でなくて「~を超えて~以下」であることは明記すべきなど(せっかく物語形式なのだから,新人くんに横軸の疑問として問わせれば良かった),突っ込みどころは多々あるが,統計学というよりは実務のデータ分析の入門書だから,これはこれでいいのかもしれない。
- ■(2015.11.8) 帰宅後読了したので,事件ファイル02以降の突っ込みどころをメモしておく。(1)pp.77の「Excelのワークシートを手慣れた様子で操作して」の部分は,A1:K2を選択してカットし(A1の上でCTRLとSHIFTを押しながら右矢印1回,CTRLを放して下矢印1回,次いでCTRL+X),シート2のA1に移ってから「形式を選択して貼り付け」で「行と列を入れ替える」にチェックを入れてから値を貼り付け,シート1に戻ってA3:K4をカットしてからシート2に行ってA11で「形式を選択して貼り付け」,「行と列を入れ替える」がチェックされているのを確認してOK,最後に再びシート1に戻ってA5:K6をカット,シート2のA21で「形式を選択して貼り付け」,以下同様という手順は短いので書いて欲しかったし,Rでやったならコードを載せて欲しかった。(2)pp.78-79でbreads.csvが出てくるときにcsv形式がどういう形式なのか,Excelでどうすると保存できるのかが説明されていないが,ここはExcelがわかる人なら説明不要ということか? (3)pp.92-93では,仮説検定で有意差がなかったことから「慎重を期していえば,重量が減っていると疑う根拠はない」という台詞があるが,慎重を期していえばもなにも,それしか言えないはず。(4)p.113のコメント部分で,read.csv("file.choose()")となっているけれども,当然ダブルクォーテーションは不要。(5)p.122は積み上げ棒グラフよりもモザイクプロットの方が描くのも簡単だし(何せ,2次元のクロス集計表がtable1に付値されているなら,mosaicplot(table1)だけで良い)わかりやすいのでは? (6)p.127は,「ごくごく簡単な目安だが」と書いてあるのでいいのかもしれないが,カイ二乗検定における近似が正しくない可能性があるのは,「分割表のどこかに5未満の頻度がある場合」ではなくて,「期待度数が5以下のセルが全体の20%以上あるとき」である。(7)pp.143-144での,sakurada.csvからmenus.csvへの変換過程のコードも示して欲しかったところ。Perlか何かで書く方が楽そうだが。(8)pp.158の相関係数の判断基準の目安表は誰が提案した基準なのだろう? (9)回帰を相関の延長として説明するのは違和感がある。(10)台詞だからいいのだが,pp.252でオッズ比が競馬で使われているというのは違っていて,競馬で使われるのは「オッズ」であって「オッズ比」ではない。glm()の結果からオッズ比を出すときにさりげなくexp()を取っているのだが,そこに触れていないのも気になった。(11)pp.254からロジスティック回帰分析の計算練習用に取り上げられている例がMASSパッケージ内のbirthwtだが,説明がざっくりしすぎなので,この部分に関してはぼくの大学院修士課程用のテキストのp.121からを読んで貰う方が良いと思った。表紙イラストの背景に使われているのも,birthwtのロジスティック回帰分析の出力なのだが,本書の特徴を出すには,図05-09とか図05-10の方が良かったんじゃないだろうか。とはいえ,事件ファイル05でMecabを使ったテキストマイニング入門を扱っているのは石田先生の面目躍如といったところだと思うし,openairパッケージのcalendarPlot()など,ぼくが知らない関数も紹介されていて,それらがすべて1つのストーリーの中に凝縮されているわけだから,やはり凄い仕事というべきと思う。
- ■(2015.11.16) 院生からの相談に答えていて,フィリピンのGIS関連のデータの不整合には苦労した。院生が入手していた乳児死亡率のregion別データをコロプレス図にするというのが目標だったが,シェイプファイルはPhilGISとかDIVA-GISの国別データダウンロードページから簡単に得ることができるが,前者のregionレベルのdbfには長い名称のフィールドREGIONしかないし,後者のAdministrative Boundariesには,国全体とprovinceとbarangayの水準はあるがregionという水準がないのだった。逆にDIVA-GISのprovinceレベルのシェイプファイルを使ってやろうとすると,今度は乳児死亡率がprovinceごとに得られるサイトを探すのが大変で,pdfで提供されているページは見つかったがprovinceの名称がDIVA-GISのdbfに入っているものと違っていて,簡単には対応づけられないのだった(2000年から2004年までのデータならregion別やprovince別の死亡数がExcel形式で入手できるし,Quickstatから1つずつ拾ってくればregion別やprovince別のさまざまな値が得られるのだが,一覧表になっているものが見当たらない)。もちろん,どのregionにどのprovinceが入っているかがわかれば,regionレベルの値をそこに属するprovince全部にコピーしたデータを作るとか,PhilGISのregionレベルの地図情報データのdbfをLibreOfficeとかEpiInfoで直接編集してregion番号のフィールドを作り(実はQGIS自体でも簡単で,属性のプロパティを表示させてからエディットモードにすれば新しい属性を追加できるので,整数で2桁と定義してやれば表形式で入力できるのだった),乳児死亡率データの方もregion番号を入れるという方法もとれると思うが,いずれにせよ若干裏技的。もっといい手がありそうだが,結局今回は,院生が乳児死亡データが入っているテキストファイルの方にdbfと同じregion名をタイプすることで問題解決した。なお,今回はQGISでやったが,コロプレス図を描くだけなら,Rのmaptools(当サイト内にも群馬県や神戸市の描画などでいくつか使用例を載せている)とかEpiInfoのEpiMapを使う方が簡単だと思う。
- 2015年度R研究集会(2015年12月5日→コメントある方は当日の鵯記へどうぞ)
- R研究集会は予定通り10:00スタート。以下メモ(内容は中澤が聞き取った範囲なので間違っていたらごめんなさい)。
- (1) 今朝リリースされたR AnalyticFlow version 3の話(ef-prime鈴木さん)。4ペインのGUI操作できるRのフロントエンド。データプレビューから実際に読む→「結果が見える」設計なので,head()とかprint()とかsummary()をしなくてもいい(それらはボタンになっているので簡単に実行できるが)。フローへはドラッグドロップでノードができる。テキストファイルの読み込みはファイルビューアで選択して開くだけ。ファイル形式は自動判定される(指定することもできる)。オプションは選ぶだけでなく,自分で追加できる(ファインチューニング)。今回の特徴は,Rの知識がなくても,統計解析の知識があれば使えるようにしたこと。Rの知識があればファインチューニング可能。Javaで開発したので(Oracle Java 8 JDKが必要)いろいろなOSで使えて多言語対応している。社内で実際に運用してきたものなのである程度安定しているはず。カスタムUI機能でこんなモジュール作ってみました(生存時間解析など歓迎),という場合はお知らせいただけると有り難い。それがオープンソースの強みでは。詳細は"R AnalyticFlow"で検索(バージョン3のファーストガイドがあった)。(質疑)Windows環境でJavaは32bitでも64bitでも大丈夫。forループを書くためのツールもある。グラフィックのinteractiveな操作は未実装。でもRのパッケージは全部使えるので大丈夫。dplyr,data.table,ggplot2を使っていないのは生成されるコードの可読性のため。subsetでdata.frameにしている。
- (2) 岡田さんによるRとIoT (Internet of Things=モノのインターネット)。岡田さんは7月からuminに異動。マイコン機器(Raspberry Piのようなものも含む)によって自動計測されたデータをRで処理するという話。機械自体がWiFiやBluetooth,3Gなどの機能をもったことが大きい。Rはシングルスレッドなので,基本的にリアルタイム処理は苦手。ネットワーク経由で少しずつデータが入ってくるのも苦手。普通は他の方法で蓄積したデータを解析するがShinyでやりたい。IoT機器がどのように通信するかを考える。いったんマイコンでデータを受けてから,BT+スマホ,WiFi,3Gなどでネットにデータを流す。httpで通信するものもあるがマイコンでは扱いにくい。MQTTというプロトコルがIoT機器ではよく使われる。データフォーマットはXMLは重いのでJSONがよく使われている。行単位の情報送信が多いのでcsvも見掛けない。MQTT Broker自体はストレージ機能が無い。mongoDBなどのKey-Valueストアにそのまま流す。mongoDBに蓄積したデータをRから読むのが初級。Rから直接MQTT Brokerにsubscribeして送られてきたデータを読むのが中級。ここまでは成功。Rで直接ハードウェアアクセスする上級編はまだできていない。mongoliteパッケージを利用。mongoDBのクエリsort={"$natural":-1}を使って最新X件のデータだけ取り出している。データフレームへの変換も自動。GPS位置情報,気温・気圧などの測定値をリアルタイムで送信してShinyで自動的にグラフが更新されるようにでいている。施錠・解錠とか,LEDの点灯数を変えるとか(モバイルルータ経由で)もできる。Shinyで表示するには若干のTipsがある。reactiveValues()とかreactivePoll()を使う。後者がミリ秒単位でポーリング間隔を指定。本当のリアルタイムでやりたければシリアル通信。
- (3)は自分の発表(今年夏にやった集中講義の一部の紹介)。semの結果でAGFIが出てないとか中途半端で申し訳ありませんでした(追記:AGFIが出るコードを含む改良版プレゼンpdf……といってもまだ不十分……をアップロードしました)。尺度構成における得点について丁寧な検証が必要ではないか(リッカート尺度のままの場合と標準化した上で分散を最大化する場合と別のスコアを割り当てる場合で大きな違いが出る事例はないのか? など)というコメントをいただいた。時間を見付けてやってみなければ。
- (4) 谷村さんによる「RとTikZを組み合わせたインフォグラフィック」。地域住民にわかりやすくデータを提示するためにRはどこまでできるか。国際助産師の日のインフォグラフィックの例。Rの機能だけで。(A)新聞に掲載されているグラフをRで再現する。背景はストライプ,xlabやyabはない。タイトルがグラフに入り込むなどコンパクト化。まずストライプを描画する関数を作成。backrect関数を定義し,panel.firstを使おうと思ったがbarplotではうまくいかないので,先にbackrectを描いてからbarplotをadd=TRUEで描画。他にもいろいろ工夫する。heisei.l関数で軸ラベルに平成年号,speech.baloon関数で吹き出しを付けた。できたものはフォントが弱いのが弱点。フォントの追加が面倒で,基本的に1つのfamily。(B)新聞記事の主要国の論文数。国別データであること,ノーベル賞のメダル画像で学術研究関連のデータであることが一目でわかる。CSVで主要国の論文数データをダウンロード(2009年まで)。メダル画像の読み込みはlibrary(png)のreadPNG("",TRUE)で読み,rasterImage()で貼り付ける。これをpanel.firstの引数に使えば背景に載せられる。matplot()はpanel.firstに非対応なので,まずplot()で1つの国だけ描画し,matlines()で他国を重ね描き。影付のラベルを描画するための関数も作った。ぼかしが必要なドロップシャドウはRだけでは難しい(gridSVGパッケージを使えば可能)。単に位置をずらした灰色のボックスを下に敷いた。ImageMagickを使うとちゃんとしたドロップシャドウも簡単に作れる。Rからsystem()を使ってラベル画像を作り,readPNGで読み込む手もある。文字のレイアウトが難しい。Rで再現すると折り返しも自動化はできない。そこでTikZを(tikZDeviceパッケージ,options(tikzDefaultEngine="luatex")で)使う。Beamerとの相性は抜群(開発者が同じなので)。tikz()でTeXファイルを吐いてスライドに読み込むだけ。図をTeXにすればpdfの命令を埋め込むことができる。pdfliteralを追加してサイズ,色,白抜きなども可能。ただしtikz()はラスター画像に対応していない。Rグラフィックの中でメダルを背景に貼り付けてもTeXファイルに変換できない。(C)日本人の男女別平均寿命の推移。元データは西暦なのでlibrary(Nippon)のjyear()を使って和暦に変換。X軸はcexで●の大きさを変えてプロット。次にTikZコードを編集し,\node at (120, 60) {\ includegraphics[width=15mm]{agedmale.png}};のようにする。吹き出しも簡単。本文中からの矢印で参照といったこともTikZなら可能。TikZで世界が広がるが,本格的なインフォグラフィクスはドローソフトに任せるのが順当。(質疑)版下作りのときフォントはpdfよりもcairoやquartzの方がずいぶんマシ。Rの中からpdf内部で吹き出しなどの解釈が可能なコードを出せると便利というコメントがあったが,現状ではTeXにしてから弄るしかないとのこと。
- 昼休みは往路で買ってきた握り飯を食べ,コーヒーを飲んだ。いろいろな知人とゆっくり喋れた。
- (5) 探索的データ解析におけるR,Python,Juliaの比較。トヨタIT開発センターの福島さん(クルマ関係のデータマイニングが本業)。『データ分析プロセス』『データサイエンティスト養成読本』の著者。近々『R言語徹底解説』が共立出版から出る。Hadley Wickham渾身の本の訳。Wonderful Rシリーズが共立から新シリーズとして出る予定(『データ解析のためのR・Python・Julia入門』というのも出る予定だそうなので,その著者が福島さんなのか? Juliaの伝道師と呼ばれる方と共同執筆とのこと)。Juliaは今のところMatlab代替な感じ。データ解析ソフトの動向で,KDnuggetsアンケート(2015年5月)の結果によるとRが1位,Pythonは4位。従来はSASやSPSSと比較されてきたが,今回はPython,Juliaという言語処理系と比較する。Rは7000を超えるパッケージ,強力なグラフィクス機能など,統計解析のデファクトスタンダードといえる。Pythonは1991年開発。PyDataと呼ばれるデータ解析環境のコミュニティも強力。ライブラリも多数ある。JuliaはMITのJeff Bezanson氏を中心として開発されている科学計算のソフトウェア。LLVMによるJITコンパイラによる科学技術計算の高速化が期待されている。洗練された言語仕様。なぜ作ったか? の答えはIn short, because we are greedyとのこと。データの読み込みはどの言語も大差ない(PythonとJuliaは外部ライブラリを使うが簡単)。要約統計量はRのsummary()ほど賢くない。bankというオブジェクトに対して,Pythonのbank.describeやJuliaのdescribe(bank)は不十分。層別集計はPythonとRは手間は大差ないが,Pythonの出力は見にくい。Juliaはaggregate関数でできるが出力が見にくい。相関係数は簡単。多変量連関図は,RではGGalleyパッケージのggpairsが素晴らしい。Pythonはできるがカテゴリ対応が今ひとつ。Juliaでは多変量連関図は自分でフルスクラッチビルドが必要。まだまだ探索的データ解析に関してはRはPythonやJuliaよりずっと多機能。ただし,速度に関していえば,MCMCのGibbs samplingの同じ処理をするコードを3つの処理系で作って比べてみると,Rでは0.03~0.04秒,Rcppでは100倍くらい高速化される。Pythonでは0.02秒弱。JuliaではRcppの倍くらいの時間に収まる。Dynamic Time Warpingの例では,Rが250マイクロ秒程度。Rcppでは約5マイクロ秒。Pythonが約1250マイクロ秒,Juliaは130マイクロ秒程度。速度はRcpp最強。フルスクラッチでアルゴリズムを書きたい人にはJuliaは良い。(質疑)deep learningはPythonではあるけれどもRには見当たらない。deep learningの入出力をRでというのはh2oパッケージくらいしかない。既にPythonでのインターフェースが主流になっているから,今後もRにそのようなインターフェースが増えてくる見込みはあまりなさそう。(質疑2)最適化の信頼性とかはどうか。一応,PythonやJuliaにもパッケージはあるが,今後の検討課題。(質疑3)Rにおけるfactorのような型は? Pythonのpandasパッケージに名義変数や順序変数という型は提供される。Juliaは型はあるけれどもカテゴリは鬼門。モデル内で自動的にダミー変数に展開するような機能はない。
- (6) なかまさんのパッケージRhpcの状況。ここ最近増えた機能の説明。Rhpcは,元々Rをスーパーコンピュータで使うベンチマークだった。RhpcBLASctlは一部で人気。データ採取のための最低限の機能として,Rhpc_worker_call及びRhpc_lapplyを実装。スーパーコンピュータ上では,通常SPMD。でもなかまさんがSPMDを嫌いなのでapply系で並列処理。スーパーコンピュータなのでMPIを選択(MPIが入っていないスーパーコンピュータはない)。ワーカープロセスはEmbedding Rで作成(libR必須)。Windows版も始めた(Rユーザの9割がWindowsなので)。Rhpc基本関数はこれまでと同じ。MPIの初期化と終了処理及びコミュニケータに関するRhpc_initializeとかAplly系のRhpc_lapplyとか,ワーカー上の乱数の初期化の関数とか。Rhpc_applyとかRhpc_sapplyもラッパーとして実装した。parallel::ClusterExport(MPI)では8ノードでsnowの2.7倍の速度がでた。定期的にGCがかかるため,その時間が大きい。MPIよりRhpcは遥かに速い。ロードバランシングなしだと激速。foreign MPIとしては,FortranやCの外部MPIプログラムは。Fortranや.Cで呼び出す。データの受け渡しにいろいろ工夫が必要らしいが,たぶん自分でこの関係のコードを書かないとよくわからないな。MS-MPIは最新はバージョン7で1週間くらい前に出たばかり。MS-MPI v5 SDK以降のデフォルトパスには括弧が含まれ,64bit版ではdefファイルを用いてリンクする必要がある。MPIの実効だけならSDKは不要。Rhpcはソースからビルド可能なように,いずれのMS-MPIでもできるようになっている。Windows上では,mpiexec.exeを使うがオプション引数が複雑なのでバッチファイルを書いたとのこと。もっと良い並列化技術が必要。
- (7) Rを利用した災害情報の収集と解析・可視化(山本義郎先生と院生)。『Rによるデータマイニング入門』がやっと出た。これから始めようという人にお勧めの入門書とのこと。東海大学の地域連携活動として減災に取り組んでいて,災害情報処理を始めた。DITSの開発・活用→To-Collabo。本年の防災週間にはTwitter社がTwitterを活用した防災訓練の実施を全自治体に呼びかけ,何十もの自治体が参加した。例えば和光市では災害用ハッシュタグ基準が定められている。ほとんどのTwitterユーザはGPS機能をオフにしているのが困ったところ。そこで災害情報tweetのためのDITSというアプリをスマホ用に作った。Web-GISイメージなど(東京23区でYahooのウェブサービスを使って実現した)。Googleマップへの可視化。plotGoogleMapパッケージを使用し,座標系は平面直角座標系(たぶん緯度経度でも使える)。データはcsvで読む。EPSGコードを指定するところで緯度経度を入れれば良さそうなものだが,今のところエラーが出てしまってうまくいかない。平塚市と伊勢崎市で例示。平塚市の公開データ世帯数,総人口,等々。位置参照情報は国土交通省の「GPSホームページ」CSV形式による街区レベル位置参照情報と大字・町丁目レベルデータを取得。オープンデータは大字・町丁目単位で集計されることが多いので,大字・町丁目レベル位置参照情報と結合したcsvファイルを作った。これをdata <- read.csv("", header=TRUE)で読み,plotGoogleMaps(data, zcol="総人口", ...)で地図を表示。mapTypeIdでいろいろなプロットができる。bubbleSP()ではバブルをプロット,iconlabels()で数字とアルファベットは表示できる。Windowsでは日本語は文字化けする(文字コードをutf8にしてもダメか?)。男女別人口を円グラフでプロットした例。複数の可視化を1つの地図にまとめることもできる。基本的にadd=TRUEしたプロットをオブジェクトに付値し,それをpreviousMaps=で参照してプロットする。Rとtwitterの連携は,twitteRパッケージとROAuthパッケージを使用。streamRパッケージでtweetを取得。JSON形式で,取得実行中のtweetのみを取得できる。filterStream()関数。オプションでtrack=iconv("検索語", "CP932", "UTF-8")指定で取得できたが,3ヶ月くらい前からできなくなってしまった。ジオタグが付いていないtweetは,Google Geocoding APIを使ってツイート中の住所を緯度経度に変換した(アクセス制限が1日2,500件)。これも今現在はうまく動作しなくなっている。座標系番号は位置参照情報から取得。和光市での実証実験のとき,RMeCabで地名を抽出して分析したが,川崎市,町田市のつぶやきが入ってしまうと変なグラフになるので,それを外して対応分析して可視化した。(質疑)谷村さんの本に書かれている方法で中継させると直角座標系への変換はエラーにならないはず,とのこと。災害情報の標準化の動きはまだ不十分。
- (8) Rによるデータ視覚化のための動的グラフの利活用。久保田さん。インターラクティブに操作できるものということ。manipulate,ggvis,iplots,rCharts,plotly,gridSVG,googleVis,shinyを使って,自殺統計の表示を例にしてやってみる。難易度はmanipulateが簡単だが,RStudioの中でしか呼べない。公開はRPubsなどに出すと静止画になってしまう。スライダーやピックを組合せることもできる。複雑なことは難しい。自殺の地域統計をNipponパッケージでコロプレス図にしたい場合に,年の選択をインタラクティブにしたいとして,manipulateで呼べるのは1つの関数だから,複数の処理を1つの関数にしなくてはいけない(まあ,function()で関数定義するだけだから大した手間では無いと思うが)。分割を変えたいとかになると,それも引数に入れた関数を作らねばならない。ggvisはggplot2に慣れた人には良さそう(結局対話操作にはshinyを使うが)。iplotsはJavaベース。平行座標プロットやモザイクプロットなどで複数のグラフをリンクできる。plotlyは最近できた便利なパッケージで公開できる(注:ただ,plotlyパッケージをインストールしてみたら,plotly()で呼び出せるインターフェースは既にdepricatedでggplotly()推奨となっていた。gridグラフィックスになってしまったが,exampleでコメントで表示される例にでてきた最初の2行をやってみたら,確かに簡単に動作した)。shinyがもっと便利。複雑なインターフェースが簡単に定義できるし公開も簡単なのでお勧め。
- 30分休憩。
- (9) 徳島大学の服部さん。元々音声認識と認知科学をやっていた。オランダにおけるヒッチハイカーのマインドについて。自己紹介としては,R fanaticでStackOverflow好き,猫好き,GIS好き(注:しかし,それ以上に英語の発音が素晴らしいのが印象的だった)。ヒッチハイカーのデータがHitchwikiに転がっていた。元自衛隊員の旅人から教えて貰った。2006年11月オープン。2015年12月3日現在,22680のデータ点が存在。一ヶ月に1000くらいのペースでデータが増えている。最近ポーランドのデータが増えた。ダウンロードできるデータの形式はKML形式。データの前処理が大変だった。StackOverflowで情報検索したら,layer nameがわからないと読めないという返事とカスタム関数を書けという返事があった。headerを見たらlayerらしきものがあって試したが読めなかった。そこでreadLinesで全部読んでパタン検索することにした。enc2utf8()とiconv()で多言語を統一しgrep()とna.lock()で分割し,stringiパッケージの関数を使ってlapplyでデータ抽出。stringiパッケージは高速で便利(しかも日付オブジェクトも操作可能)。悪戦苦闘してオランダのヒッチハイクデータを抽出した。ヨーロッパ全土のデータから20kmメッシュにして,どこでヒッチハイクが多いかを地図に示した。他の国では大都市周辺で多いが,オランダは国全体で多い(合法だし)。国としてはフランス,ドイツ,オランダの順。都市名を抽出し(GADMのlevel2で,最も長い形式で),ヒッチハイカーのコメントとともに抽出し,コメントが書かれた場所からコメントに出てきた都市までの距離をdistN1()で計算。これを地図に載せると,アムステルダムやユトレヒトを起点としたネットワークができていることがわかる。比較的近いところから入ってくる線が多い。Gronigenだけは特殊。オランダでは近くの町を考えながらヒッチハイクをしているらしい。町の名前がウムラウトの処理など悩ましいところ。ドイツ語を母語としない人の書き込みではウムラウトが使われていなかったり。networkVisで視覚化というのを今後やりたい,とのこと。(質疑)名前の揺らぎの解決は?→結局は自分でコードを書くしかないかも。鉄道網との関連は?→まだやっていないが,マップに載せれば見られるはず。なお,stationという単語は出てくるがgas stationであることが多いし,bus stopの方が関連高い。
- (10) 徳島大学石田先生。「API(周り)の話」という予定演題だったが,「Rとオープンデータ」に変更。専門はテキストマイニング。新米探偵の本も書いたのでR本が増殖した。Hadley Wickhamの本の原著は『Advanced R』。訳書は現在校正中。とても良い本とのこと。オープンデータとは自由に使えて再利用でき,誰でも再配布できるようなデータのこと。決まりはクレジットを残すことと同じ条件で配布すること。電子政府総合窓口にも,コンピュータ処理に適した形式の必要性が書かれている。「5★オープンデータ」の話。★pdf,jpg;★★xls, doc;★★★csv, xml,★★★★RDF, XML;★★★★★Linked RDFとのこと。利用者側の気持ちとしては,データの取得から加工,要約,作図まで自動化させて欲しい。四国八十八ヶ所の札所は日本語サイトでは一覧表がないが,USAのwikiにあるので,rvestを使って抽出できてLeafletで地図にも表示できた。しかし日本のオープンデータも増えてきていて,LinkDATAはRのAPIまで提供されている。SPARQLというパッケージを使うとRDFが読めるが,国会図書館のサイトはXMLからだとUTF16を返してきたりするが,xml2パッケージを使うとutf8に自動変換してくれる。rvestは便利で,LinuxやMacOSならOK。しかし,WindowsはCP932なので化ける。ダッシュの代わりに全角マイナスが使われているとかも切れる。一般ユーザはWindowsが多いので対応しなくてはいけないのが悩みの種。とくにHadley WickhamのパッケージはCP932と相性悪い。WEBスクレイピングをするには,Jsonとrlistは相性が良い。ただ生のAPIを弄るのは面倒。Amazonはタイムスタンプ込みで認証符号化しているが良いパッケージが多数ある。dichika/NHKGなどなど「盆栽日記」に多数のAPIを弄るパッケージが公開されている,とのこと。特定のSNSターゲットのAPIは今後増えてくるだろう。TwitterはtwitteRなど便利だが,Windowsの場合文字コード変換が鬼門。何度も変換する必要がある。
- (11) 東京医科歯科大学樋口先生による「Bioconductor update」。2011年に第2版が出た本以降のアップデートについて,主観に満ちた自分自身のためのまとめ,とのこと。Bioconductorはバイオインフォマティクス研究の支援環境提供。AMIやdockerイメージでも提供されている。サンプルコードにパイプ演算子が使われている。生物はゲノム=DNA→RNA→タンパクが原則で,オミクス解析はそれぞれの層ごとに違うターゲット。最近はRNA干渉とかSNIP多型とか翻訳後就職とか新しい知見も。Bioconductor version 3.2 Software (1104)にはたくさんのパッケージが入っている。AssayDomain,BiologicalQuestion,Infrastructure,ResearchField,StatisticalMethod,Technology,WorkflowStepなど。それぞれ既にdockerのイメージとして提供されていて,それを使って解析できたりするとのこと。データもいろいろ含まれている。大幅な機能向上。大量のマイクロアレイデータの正規化(oligoパッケージ),次世代シークエンサー関連ツール(Rsamtools,Rbamtoolsなど),大規模解析(ffとcrlmmでCNVコピー数変異の解析とか→コピー数の増減とがん発症には密接な関係がある),さまざまなデータベースがRの形式で提供されているとか,最新のツール(ゲノム編集によるRNS設計のCRISPRseekとか,AtlasRDFとか)も使えるとか利点が大きい。dockerによるBioconductorの利用としては,Rstudio経由とかコマンドライン版Rを使うなどの使い方がある。以降は「個人として」の発表(危ない話?)。Updateといえば第3版。いまさら? という感じもあったが,アップデートも必要かと。(中略)ブログや口頭での評価はいろいろ(hoxo_m氏から中途半端とお叱りを受けたので直接謝ったという話は面白かった)。第3版を書くとしたらRの基礎は書かなくて良いだろう。ただしケーススタディとしてデータフレーム操作やスクレイピングによる情報付加は効果的かもしれない(dplyrやrvest)。もう少し理論的背景の開設にも踏み込みたい。問題は育児が忙しくて(?!)時間が取れないこと。(質疑)cranとbioconductorの並立状態について,bioconductorにしか入っていないパッケージはどれくらいある?→未整理だがそのうちまとめたい(?)。
- 最後に総合討論があって,今後のこの研究集会の方向性についてなど議論して幕となった。
- plotrixパッケージのfloating.pie()関数(2015年12月9日)
- ■ふと思いついてplotrixパッケージを調べたら,R研究集会で谷村さんが扇形を重ねて作ったと言われていた複雑な円グラフは,floating.pie()とpie.labels()で作れるかもしれないと思われた。example(floating.pie)してみると良い。
- R-3.2.3リリース(2015年12月10日)
- ■R-3.2.3が予定通りリリースされたというアナウンスメールが届いた。
- ■予定通りリリースされたR-3.2.3のコードネームはWooden Christmas Treeだが,出典は例によってPeanutsのようだ(YouTubeの動画,Tweet参照)。
- 栄養関係のパッケージなど(2015年12月15日→コメントある方は当日の鵯記へどうぞ)
- ■ふと思い立ってcranに栄養関係のパッケージはどういうものがあるのか検索してみたら,NHANESのデータがパッケージ化されていることがわかった。解析手法を示すためのサンプルデータとして好適と思うのでメモしておく。実際,既にproject mosaicで開発された数学と統計学を教えるためのパッケージmosaicの中で利用されているようだ。さらに,SPADEというオランダの食事調査結果分析プロジェクト(論文)では,食事毎の栄養素摂取量が計算された後ならば,それを分析するための環境が提供されていて,RとRStudioを使ってhabitual dietの解析法を学ぶための200ページ以上のマニュアルがあった(Windows専用であり,かつメールでリクエストしてzipを貰って使うという手段でしか入手できないようだが)。
- ■けれども,今のところエクセル栄養君のような,食事調査から栄養素摂取量を計算するために使えるパッケージはないようだ(FAOのサイトのこのページの"Software tools for dietary assessment"にリストされているものは使えるかもしれないので,あとでチェックしよう。Windows専用だがNutriSurveyというソフトは使えるかもしれない(→無料なので試してみたところ,日本語版のWindows 8.1でも,とりあえず問題なく動作した)。ミネソタ大学のNDSRというソフトは高機能そうだが,値段が高いと思う)。
- factorのラベルはlabelsではなくlevels(2015年12月16日)
- ■昨日,tweetで知ったR言語のファクターの異常な分かり難さは、冗談か嫌がらせかという記事について,labelsを使わないと決めておけば多少マシでは?と引用tweetしたのだが,要するに,ファクター型の水準名はlevelsであってlabelsではないと考えれば,そんなに分かり難くないというのが主旨。
- 『健康・スポーツ科学のためのRによる統計解析入門』(2015年12月22日)
- ■毎月ご恵贈いただいている『トレーニング・ジャーナル』のA編集長から,出村愼一(監修)山次俊介・高橋信二・鈴木宏哉(編著)『健康・スポーツ科学のためのRによる統計解析入門』杏林書院,ISBN:978-4-7644-1142-5をご恵贈いただいた。主にRコマンダーを使って,記述統計,差の分析,関連の分析,検出力分析とサンプルサイズの決定という章立てからは良くある入門書かと思ったが,ところどころ実にマニアックで面白い。例えば,記述統計のところではRまたはRコマンダーでbaseの作図をした後,メタファイルとしてクリップボードにコピーし,それをExcelに貼り付けてグループ解除して編集する方法を提示していたり(PowerpointやWordでも編集できる,と書かれているが,それなら最初からPowerpointを使う方法を書いておく方が編集しやすくていいと思うし,もっといえば,LibreOfficeのDrawの方がやりやすいが),クロス集計の残差分析を説明していたり(pp.151-153),相関係数の差の検定方法のコードを書いていたり(pp.190-193;普通ならホテリングのT2を説明するところだと思うが……)する。ちょっと残念だったのは,カッパ係数(Cohenのκ)についてカテゴリ間の関係を分析というところと(p.133),信頼性の分析の表(p.204)に名前だけ載っていた点。κはカテゴリ間の関係ではなく,test-retest reliabilityやinter-rater reliabilityの指標で,対応のあるカテゴリ尺度間の一致度を示すので,測定自体のデザインはマクネマー検定または拡張マクネマー検定と同様で(但し,当然のことながら正方行列でなくてはいけないが),仮説が「変化があった」ではなく,「偶然とは考えられないほど一致している」という違いがあると説明すべきで,解析するコードも,fmsbパッケージのKappa.test()を使って欲しいとまでは言わないが,vcdパッケージのassocstats()を紹介しているのだから,Kappa()を紹介すれば良い話で,そこが載っていないのが惜しかった。なお,サンプルデータとプログラムは杏林書院のサイトからダウンロードできるようだ。
- Rでレキシス図(2015年12月25日)
- ■【からだにいいもの R】 Rと解析:人口統計学、レキシス図の描写「LexisPlotR」パッケージ……というtweetから当該ページに飛んでみたら,確かにLexisPlotRというのは,gridグラフィクスでレキシス図を描くためのパッケージのようだった。レキシス図はコホート研究のデータ提示に適していて,とくにage-period-cohortの3要因の効果を統合して眺めるのに良い作図法だが,baseグラフィクスでは,既にBendix CarstensenのEpiパッケージにLexis.diagram()という関数があるし(使い方を知りたければ,Epiパッケージがインストール済みであれば,library(Epi); example(Lexis.diagram)の出力を見たらだいたいわかると思う),3要因を分解して捉えるためのapc.fit()やapc.plot()という関数も用意されているので,ggplot2の愛用者でなければ,敢えてLexisPlotRを導入するメリットは感じられないかなあ。しかし,「人口統計学」という言葉を見て思い出したが,このところずっと『Rで学ぶ人口分析』は放置してしまっている。このテキストでは,fmsbとpyramidの他に推奨するパッケージとして,demographyとEpiは必須と書こうと思っているが,その辺のこともまだだなあ。時間が欲しい。
- グランフロントでKobe.R #23(2015年12月26日→コメントある方は当日の鵯記へどうぞ)
- ■10:00スタートに何とか間に合った。メニューはオープンデータ,カテゴリカルデータ分析,アソシエーション分析入門,RとMeCabを用いたtwitterマイニング,IoTハンズオン(仮)。IoTは時間がかかりそうなので最後で……ということで,以下メモ(例によって内容は無保証です)。
- 神戸に限らず,最近は大阪中心。Rに限らずデータ解析関連なら何でもOKな感じで。運営者募集中。
- この会場,壁がホワイトボードになっている! びっくり。
- ■最初の発表は,お肉の検査員(超非エンジニア)でもわかるアソシエーション分析入門。普段は病理検査や微生物検査をしている。超アナログ。PCはほとんど使ってない。データは主にエクセルでやっていたが,今春4万件以上のデータ集計をする必要がでてRを使い始めた。属性Aをもつobsは属性Bをもつ傾向にあるのような知識A→Bをアソシエーションルールと呼ぶ。ビジネスで重要な役割を果たす。このルールを見付けるのがアソシエーション分析。ルールヘッドやルールボディをトランザクションデータから見付け出す。4つの確率。前提確率p(A)は高いほどよい。適用するチャンスが高い。p(B|A)は信頼度と呼ばれる。この確率が高いルールは良いルール。適用されれば高い確率でヒットする(例:パチンコ台の特定の釘が曲がっている→大もうけ)。同時確率p(A, B)はp(A)*p(B|A)。高くなって欲しい。事前確率p(B)は低いほどよい。元々p(B)が大きかったらルールを見付けるうまみがない(例:上着を買う→ハンカチを買うというルールの条件付き確率と,ハンカチを買う確率に差がなかったら,「上着を買う」条件が不要になる)。改善率(lift値)を指標とする。改善率はp(B|A)/p(B)=p(B, A)/(p(A)p(B))。この値が1を超えたら採用。パッケージはarulesを使う。『銀座で働くデータサイエンティストのブログ』の購買データex_trans.txtを使用。まず元データを素性ベクトルの形にする。read.transactions()関数で,format="basket"を用いる。重複を消す場合はrm.duplicate=TRUEオプション。これをwrite.csv()でcsvファイルに書き出しておく。。apriori()関数でアソシエーションルールを推定。Inspect()関数でルールを表示。arulesVizパッケージでplot()するとグラフが出る(method="graph"を付ける)。バージョンによってはうまくいかないことがあるが,バージョンを落とすとうまくいくこともある。ここまでは元ブログに書かれている。前回のKobe.Rで河原さんがigraphを紹介していた。素性ベクトルを隣接ベクトルの形にするとネットワーク分析ができる。隣接行列はアイテムが行列に並んだ正方行列。推移数をカウントする。peccuさんのサイトがgithubにあって,peccu 隣接行列で検索すると出てくるコードをadjacency.Rと名前を付けて保存し,それをsource()で読み込み,adjacency()で計算。igraphパッケージを使えばgraph.adjacency()でグラフにできる。近接中心性や次数中心性,固有ベクトル中心性などがあるが,degree()関数で計算できる。Rで学ぶデータサイエンスシリーズ『ネットワーク分析』がお勧め。ネットワークのどこが違うのか(例えば,焼き肉屋のPOSデータを使ったデータハッカソンの優勝チームが示した,ワインを飲む人と飲まない人の注文の仕方の差はどこか?)を検出する方法はあるのか? が疑問とのこと。例えば,ワインを飲む人と飲まない人で(あるいは注文があったテーブル別)別々に集計してネットワーク図を書いたときに見た目で違うというだけか,分析手法があるのか? ■検査そのものも画像解析が応用できるんでは? ■腕の数の頻度分布はどう?(スケールフリーの検出は時系列の変化をみたら面白いかもしれない,と河原さんコメント) 4万件でも1秒かからないくらいでできる。アソシエーション分析と協調フィルタリングとの違いは? ■協調フィルタリングはユーザ側のデータが必要だから,このデータではできないはず。ワインの奴は経路分析しているのかも?
- ■次の発表は共起を用いたtwitterデータの分析(webスクレイピング)。神戸情報大学院大学の大学院1年の方。データマイニングやテキストマイニングの勉強中。SNSから商品被害を抽出する方法の探索。加水分解小麦石けん問題とか,カネボウ化粧品白斑問題とか,5年ほど売られてから被害が問題化した。もっと早く検出したい。被害者情報は消費生活センターや病院,企業経由で国民生活センターに集まるが,タイムラグが数ヶ月かかる。そこでSNSから被害情報を収集して検出したい。webスクレイピングはrubyで収集,postgresqlに格納。Twitter REST APIとTwitter Steraming APIがあるが,前者がプログラミング用。制限がきつい。2013年6月12日に制限が変更されたので古い情報には注意。twitter社は後者推奨。その中から前検索として日本語データを取り出し,被害候補があったらREST APIを使って詳しく分析。共起とは,ある単語がある文章中に出たとき,その文章中に別の限られた単語が頻出すること。例えばニュース集合では,「メルケル」と「難民」,「安部首相」と「談話」は共起している。今回はtwitterのstreamingの日本語tweetから特定の会社の社名を含むものを1万件抽出し,RMeCabのcollocate()とcolScores()を用いて共起を検出。collScores()は見せかけの共起(限られた単語の共起ではなく,たんに頻出する言葉を検出してしまう)を防ぐのに重要。結果をみると明らかにおかしいデータがあった。リツイートが1万行中に899行あったため。これはノイズ。前処理が必要。意味が重複した単語やリンクを削除(正規表現を使う)。そこはviで:sort uで済ませた。10000行→5113行。次に共起したのはその企業の創業者の名言。商品名はほぼ入っていないので:g/創業者の名前/dで削除。さらにアルファベット1文字などを除外し,Afterで並べ替え。そこでやっと商品名や商品の機能が出てくる。次に商品名はカタカナが多いことに注目し,カタカナだけ抽出。(■長音などの表記揺らぎは?→メーカがどう表記しているかの影響が大きい,とのこと。使う辞書によりどうにでも分析できる。)製品名や商品名を抽出するのは難しい。(■目的からしたら,この後さらに「被害」とか「問題」とかとの共起を探ることになるのか?)【質疑】▲最初からメーカー名ではなくてカタログなどから商品名を探して,それを検索しないのか?→目的が特定の商品に注目ではなく,いまSNSで問題になっている商品を探すことだから,そうしない。商品名はMeCabの辞書に入れると効率が上がるかもしれない。▲なぜ3スパン?→2スパンではうまくいかなかったので3スパンでやった。▲アソシエーション分析との関連は?→アソシエーション分析の中心語を入れるというのがこの分析法。▲全文の方が良いのでは?→広げすぎると関係のない単語が入ってしまうため試行錯誤で3スパンに決めた。
- 5分休憩。ハンズオン発表者はまだ来ていないため,とりあえず他の発表で終わるかも。
- ■次の発表はカテゴリカルデータの分析事例。データマイニングシリーズ本の『カテゴリカルデータ解析』を参照しながら。心理統計でサービス・マーケティングなどをやっているごとうさん(@hikaru1122)。ブログもある。R歴は1年ちょっと。来年からJAIST在籍。経営系の研究科。500人7変数のデータ。共創(co-creation)への姿勢の強さ(6段階の順序尺度)は性別によって違いがあるか? 成果指標(満足度とか口コミしたいとかの順序尺度)と相関するか? 成果指標に影響するか? を明らかにしたい。統計たん(@stattan)のtweet「なぜ3カテゴリの順序データを連続量とみなして分析するのか理解に苦しむ」に対して,順序カテゴリデータをちゃんと分析しようという企画。満足度が7件法のリッカート尺度ならば重回帰をやってもいいという人がいるかもしれない。成果指標はぜんぶ左裾を引いていて正規分布でない。xtabs(),wilcox.exact(),polychor() {polycor}, makedummies.R,polr(),orm(),lrm(),multinom()を利用。パッケージは{polycor}の他には{MASS},{exactRankTests},{nnet},{rms}にこれらの関数が入っている。まずはxtabs()でクロス集計。chisq.test()とwilcox.exact()で結果が違う。■chisq.test()の帰無仮説は2つの変数が独立ということなので順序の情報は一切使わないし,wilcoxは順位和をランダムな場合と比べるわけで,順序の情報を使うかどうかが違うから検定結果が違って当然。マンテル検定もありうる(■あれって行列の差の検定じゃなかったっけ?)。polychor()とcor()は多少結果が違う(■cor()でmethod="spearman"とかmethod="kendall"ではどうか?→スピアマンの順位相関係数はピアソンの相関係数よりもポリコリック相関係数に近かった)。HADを使ってみる。いま紹介したものは全部できる。Excelのマクロ。SPSSっぽいインターフェース。(■HADのカテゴリカル相関って本当に順位相関ではなくてポリコリック相関なのか?)心理統計では知られるようになってきた,使い方が簡単なソフト。ただし,使っていいのは学部生まで,と開発者(清水さん)は言っている。なお,texregパッケージのscreenreg関数の出力が見やすいとのこと。
- ■最後は河原さん。オープンデータの例としてe-Stat APIの使用例。加工も利用も自由なデータをオープンデータといいたい。e-StatのAPIは最近充実してきた。web「API機能」に説明あり。統計表一覧でDBというアイコンが付いてるものはAPIでデータが取れる。手順は,会員登録→自分のKeyを取得→ID(statsDataId)を取得→IDに対応するデータを取得→データ分析。難しいのは,statsDataIdを取得する部分。xmlなのでそこからスクレイピングしてリストにすれば良い。{rvest}というwebスクレイピングによく使われるパッケージを利用。{pipeR}も使用。Hadley Wickham開発。html_attrs()とhtml_nodes()が便利。
- Dataの情報(2015年12月30日→コメントある方は当日の鵯記へどうぞ)
- ■三重大学の奥村先生の「Data http://link.springer.com/book/10.1007/978-1-4612-5098-2 … 1985年の懐かしい本。有名なIrisのデータなど多数。今となっては紙に印刷したデータなど無意味だが」というtweetを見て,書誌情報を調べてみたら,Andrews DF, Herzberg AM (1985) Data: A Collection of Problems from Many Fields for the Student and Research Worker. Springer, ISBN: 978-1-4612-9563-1 (Print) 978-1-4612-5098-2 (Online) であった。
- ■奥村先生は別のtweetで,「 (Springer祭りには関係ないオープンアクセス本) Linked Open Data -- Creating Knowledge Out of Interlinked Data (2014) 」も紹介されていた。この本も面白そうだが,それはさておき。
- ■irisはRにデフォルトで入っているが,他のデータはどうだろうと思って,??"coal-mining"を調べてみたら, boot::coalが表示されたが,Datesが実数で入っているだけだった。英国で大規模な炭鉱災害が起こった日付のデータであり,元の本には西暦の年月日が整数で与えられ,各事故の死者数データも入っているのに残念と思い,「確かに。リンク付でオープンデータになっていて欲しいですね。irisはRのdatasets::irisで使えますが,Coal-Mining Disasterはboot::coalに日付だけ入っていました。他はどうなんでしょう? 」とtweetしてみた。
- ■すると奥村先生が,「さっきの「Data」という本,いちおうpdftotextでテキスト抽出できることを確認。ただ今でいうセル結合したもので,データにするには手作業が必要」「というわけでCoal-Mining Disastersデータを『Data』本からCSV化。Rのboot::coalには死者数が入ってない」とご返事くださった。
- ■これは凄い! と思ったが,いちいちテキスト抽出するのは大変だし,既に誰かやっているのではないかと思って調べてみた。すると,Exploring Dataという別の本(Amazonでハードカバー2万円くらいする。データそのものはリンク先のサイトからダウンロードできるが)のCompanion siteに,Andrews and Herzbergの"Data"のデータは,ここで提供されていると書かれていた。しかし,喜び勇んでブラウザで開こうとしたら,残念ながら404 Not Foundと,オリジナルは消えていた。
- ■こういうときはミラーアーカイヴを探そう。Googleの検索語としてオリジナルのURLを入れて検索してみたら,それらしいものが見つかり,開いてみたらビンゴであった。このサイトはAnonymous FTPで接続できるサーバにリンクされていて,このページでは各データのhead4行とtail4行を繋いだものが見えるのでイメージしやすい。しかも,ftpなので一括ダウンロードが簡単であった。いくつか開いてみたところ,スペース区切りテキストか固定長テキストにみえるのが若干残念で,できればタブ区切りかコンマ区切りであって欲しかったが,むしろAnonymous FTPで取れるということは,各データへのアクセスインターフェースをパッケージ化できるかもしれないことを意味する。というか,既にあるんじゃないかという気がして仕方がない。このサーバってrcom.univie.ac.atだし。
- ■ダウンロードできるデータがあったことをtweetしたら,奥村先生が「多分同じものが次のところにもありました: Andrews and Herzberg Data Sets」というtweetをしてくださった。確かにデータは同じようだ。こちらのページの方が一覧表としては見やすいと思う。
- ■考えてみれば,Rでデータを選択してダウンロードする関数が書けそうだ。R Consoleならmenu()かselect.list()で選ぶようにすれば良いし,RcmdrやEZRに実装しても便利そうだ。
Correspondence to: minato-nakazawa[at]umin.net.